
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















.webp)
Insights on AI and Data Management from Intercontinental Exchange
In today’s rapidly advancing tech landscape, optimizing infrastructure to handle massive data sets has become more crucial than ever. One noteworthy story emerging from NVIDIA GTC is how Intercontinental Exchange (ICE) is tackling the growing complexity of data management, AI implementation and storage optimization across its vast network of financial exchanges, data services and mortgage technologies. We sat down with Anand Pradhan, the head of the AI Center of Excellence at ICE, and Roger Corell, senior director of leadership marketing at Solidigm, to discuss how ICE is using technology to stay ahead of the curve.
ICE, known for operating the New York Stock Exchange, processes over 700 billion transactions daily. With such massive volumes of data, building and maintaining an optimized, highly redundant infrastructure is essential. It’s not just about the network and servers — the flow of data through these systems makes storage a critical focus in ICE’s technology strategy.
Anand explained that ICE handles around 10 to 12 terabytes of data every single day with nanosecond granularity. This data, crucial for tracking financial trades, must be stored and accessed at lightning speeds. With millions of trades, real-time analysis and preventing fraud are key, which means both data retrieval and storage processes must be supercharged for efficiency.
One of the biggest challenges is the sheer volume of data and the input-output bottlenecks that arise when reading and writing to storage systems. To solve this, Anand’s team works closely with the InfraSolutions architecture team to fine-tune the storage infrastructure, ensuring that it scales easily, remains flexible and is resilient to failure. This involves rigorous testing and investment in systems that allow for fast, uninterrupted data access, while minimizing latency and maximizing performance.
But Anand’s insights extend beyond just infrastructure; he also highlighted how AI is shaping the company’s approach to data aggregation. At ICE, AI models are primarily used for processing unstructured data, such as images of real estate properties. The AI extracts valuable insights from these photos, identifying key artifacts, such as doors, kitchens or even the color of a room. With real estate photos pouring in from across the U.S., this AI-driven data processing is a massive undertaking. AI models are deployed at scale to make sense of the raw data, which is then converted into structured, usable information for the company’s real estate services.
As ICE’s AI adoption grows, so too does its need for an optimized storage solution. The storage systems of the future, Anand noted, need to accommodate millions of files — whether flat files, images or video data — and ensure they can be accessed quickly. As more and more workloads move to the AI space, fast access to large datasets and the ability to scale storage seamlessly are becoming essential. This is where storage systems that can horizontally scale, offer fast write speeds and support massive volumes of data will stand out.
Looking ahead, ICE’s evolving use of AI and machine learning is transforming its infrastructure and redefining what modern storage systems must deliver. What’s the TechArena take? With growing demands for speed, scale and real-time access, ICE’s journey offers a clear example of how AI is driving a fundamental shift across the industry. As adoption accelerates, organizations at the forefront of tech will need to rethink their approach to storage — those that do will be best positioned to gain a lasting competitive edge.
To learn more about ICE, visit www.ice.com, or find Anand and ICE on LinkedIn.

What’s next in CVEs Shaping Cybersecurity Compliance in 2025?
The landscape of Common Vulnerabilities and Exposures (CVEs) is evolving in 2025. This shift is driven by the transition of CVE management from MITRE Corporation to the CVE Foundation, and also by increasing recognition of the limits of CVE-centric metrics. By scrutinizing the governance of CVE reporting, one can better understand that more context-aware CVEs are unique identifiers for publicly known information-security vulnerabilities in released software.
For 26 years, MITRE Corporation managed the CVE program, a US government program that identifies and catalogs publicly known vulnerabilities. This centralized effort raised awareness and promoted dialogue on security risks. However, the recent development of the CVE Foundation – spurred by the US government funding uncertainties for MITRE – signals a potential paradigm shift in how CVEs are governed. This transition comes as cybersecurity experts acknowledge, at least privately, that simply counting CVEs often misrepresents their organization’s true security posture. The cybersecurity industry is grappling with the need for more meaningful metrics that genuinely reflect risk reduction, moving beyond performative measures to achieve tangible security improvements.
3 Key Trends Shaping the Future of CVEs & Their Impact on Cybersecurity Compliance in 2025:
1: The Transition to the CVE Foundation: Implications for Governance and Transparency Description: The most significant development is the ongoing transition of the CVE Program's management from MITRE to the newly established CVE Foundation. This shift aims to ensure the long-term sustainability and independence of the program through a more diversified funding model. In April 2025, the US government funding for the CVE program was cut with no transition plan. After public outcry, the US government extended funding for 11 months. This opens the potential for a more globally representative and resilient CVE program, less reliant on a single government funding source. The CVE Foundation (https://www.thecvefoundation.org/) was formed on April 16, 2025 and is actively working toward assuming full operational control and responsibility for the CVE program. Concerns regarding the transparency of its formation, and whether it is sufficiently independent from biased corporate self-reporting, have been raised within the cybersecurity community. This may affect the objectivity and reliability of the CVEs in the future.
2: The Declining Relevance of Simple CVE Counts as a Security Metric Description: There's a growing understanding that merely counting the number of CVEs identified or remediated is a flawed and easily gamed metric for assessing an organization's security risk. Although having an industry-wide quantifiable metric for budgeting, staffing, and tracking progress (KPIs), the severity and exploitability of individual CVEs vary – making simple tallies a poor measure of security improvement. This shift supports a move away from misleading metrics toward more context-aware risk assessments. It also encourages organizations to focus on risk rather than CVE counts. Organizations setting goals to "reduce severe CVEs by 5%" might achieve this by addressing less critical issues, while high-impact vulnerabilities remain unpatched, highlighting the inadequacy of this metric in reflecting true security improvement.
3: The Rise of Context-Rich Vulnerability Assessment and Prioritization Description: The future of cybersecurity compliance is trending toward a greater emphasis on vulnerability assessment approaches that incorporate more context beyond the CVE itself. This includes understanding the specific environment, existing security controls, and the potential impact of exploitation. New market segments, such as Adversarial Exposure Validation, are emerging to provide this richer context. Companies to watch include: Horizon3.ai, BreachLock, Picus Security, Cymulate, and others. These solutions enable m ore effective prioritization of remediation efforts based on actual risk and provide a better understanding of which vulnerabilities pose the most significant threat to a specific organization. Cyber threat actors actively exploit known CVEs – often those for which patches exist but have not been applied. This highlights the need to move beyond counting CVEs to actively validating exposure and prioritizing remediation based on exploitability in a specific environment.
How to Prepare
Organizations should prepare for these shifts by:
- Learning about risk-based vulnerability management: Prioritize remediation efforts based on the severity, exploitability, and potential impact of vulnerabilities within their specific environment, rather than solely on the number of CVEs.
- Staying informed about the CVE Foundation's developments: Monitor the CVE Foundation's announcements and governance structures to understand how the CVE program will evolve and how this might impact compliance.
- Exploring and adopting richer vulnerability assessment methodologies: Investigate and implement tools and services that provide contextual information beyond basic CVE data, such as Adversarial Exposure Validation, to gain a more accurate understanding of their security posture.
- Re-evaluating security metrics: Move away from simplistic CVE counting as a primary security metric and instead focus on measures that genuinely reflect improvements in security and reductions in actual risk.
Conclusion
The landscape of CVEs and their role in cybersecurity compliance is changing in 2025. The transition to the CVE Foundation and the growing recognition of the limitations of CVE-centric metrics signal a move toward a more nuanced and risk-aware approach to vulnerability management. Organizations must adopt better assessment methods to manage risks and stay compliant with their governance frameworks.
- Call-to-action: Share your thoughts on the future of CVEs and their impact on cybersecurity compliance in the comments below. Click here to learn more about risk-based vulnerability management strategies.
- Integration with Automated Security Tools: Discuss how the integration of CVE data with automated security tools, such as Security Information and Event Management (SIEM) systems and vulnerability scanners, can enhance real-time detection and response to threats.
- Machine Learning and Predictive Analytics: Explore how AI is being applied to CVE data to anticipate potential exploits and prioritize vulnerabilities based on historical trends and threat intelligence.
Global Collaboration and Data Sharing: Highlight the role of increased global collaboration and data sharing among cybersecurity entities, including how crowd-sourced vulnerability information and international partnerships could shape the CVE process and improve overall cybersecurity resilience.

Quantum Momentum: Nearing a Tipping Point or Just Growing Hype?
While many of us are focused on AI’s dizzying pace of innovation, an epic tech advancement has been coming closer to reality – quantum computing.
In the past six months, the quantum computing ecosystem has witnessed significant advancements, notably through the collaborative efforts of Microsoft and Quantinuum. Microsoft unveiled Majorana 1, the world's first quantum processor, powered by topological qubits, constructed using a novel material termed a "topoconductor," that combines topological and superconducting properties. This innovation aims to create more stable and inherently error-resistant qubits. Concurrently, Microsoft and Quantinuum achieved a breakthrough in quantum error correction by applying Microsoft's qubit-virtualization system to Quantinuum's H2 trapped-ion quantum computer, resulting in the creation of 12 highly reliable logical qubits with error rates 800 times lower than those of physical qubits. Additionally, Quantinuum's Reimei trapped-ion quantum computer became fully operational at RIKEN's facility in Japan, marking a significant step in integrating quantum computing with high-performance computing (HPC) systems like RIKEN's Fugaku supercomputer.

Just before the new year, Google introduced Willow, a 105-qubit superconducting processor. The announcement highlighted a benchmark, Random Circuit Sampling (RCS) computation completed in under five minutes, a task estimated to take today's fastest supercomputers 10 septillion (1025) years. This demonstrated significant progress in reducing error rates as qubit count scales.
The rapid pace of these and other quantum innovations – such as IBM’s Condor chip, NVIDIA’s launch in March of CUDA-Q, and Intel’s 12-qubit research chip – raises the question: Are we nearing the tipping point for quantum computing?
Technical Breakthroughs Accelerate, Funding Climbs
For years, experts have pointed to quantum error correction as the final boss to defeat. Microsoft and Quantinuum’s achievements show meaningful progress here, not just lab demos — bringing fault-tolerant quantum computers one step closer.
After a cautious funding year in 2023, venture capital and corporate investment into quantum startups are climbing again. Big players clearly see opportunity on the horizon.
New government initiatives from the U.S., EU, and China are pouring billions into quantum R&D. The global race is shifting from “if” to “how fast.”
Error Correction Needs Scaling, Real-World Impact Limited
On the other hand, today's most impressive systems still require thousands or millions of physical qubits to stabilize a single logical qubit — meaning commercial utility is still a work in progress.
And while we’re seeing a ton of innovation – no preferred or dominant quantum architecture has emerged. From superconducting qubits to trapped ions, to silicon spins and photonics, each approach comes with pros, cons, and scaling challenges.
While breakthroughs are exciting, most quantum advantage use cases (such as simulating complex molecules or optimizing massive logistics networks) remain just out of reach for mainstream businesses.
Quantum pioneers like John Preskill remind us that the NISQ (Noisy Intermediate-Scale Quantum) era may last well into the 2030s before fault-tolerant, at-scale systems become a norm.
The TechArena Take
The TechArena take is that we’ve reached the “Quantum Decade,” a period in which early enterprise experiments scale up, hardware and software ecosystems mature, winners in platform architecture and developer tooling start to emerge, and real-world proofs of concept – especially in pharma, logistics, and finance – begin to surface. The companies (and countries) that build quantum muscle now will be best positioned when the true inflection point hits — likely later this decade.
The journey to quantum computing is a marathon, not a sprint. The energy around quantum computing today feels significant. If you're not paying attention to quantum yet, 2025 is the year to start.

Dell’s Project Lightning: A Game-Changer for AI-Optimized Storage
At GTC, all things AI took center stage, and one thing that grabbed attendees’ attention was Dell’s latest innovation for AI computing, Project Lightning. We sat down with Scott Shadley, director of leadership narrative and evangelist at Solidigm, and Rob Hunsaker, director of engineering technologies at Dell, for a conversation that offered valuable insights into how Dell’s storage solutions are evolving to meet the growing demands of the AI market.
For those following AI developments, it’s clear that the performance demands of AI workloads are shifting. Traditional file systems are no longer sufficient to handle the immense data volumes and speed requirements of modern AI applications. Enter Project Lightning, Dell’s next-generation parallel file system, designed from the ground up to be the fastest solution in its market segment.
What sets Project Lightning apart is its ability to address extreme performance needs in AI environments. As Rob explained, the project was announced last year at Dell Tech World and is specifically optimized for AI use cases. This new file system offers unmatched speed and efficiency, which is essential as AI workloads continue to grow in complexity and scale. By leveraging Dell’s own intellectual property, Project Lightning represents a significant leap forward in storage technology, making it a game-changer for industries relying on AI.
This new addition to the PowerScale family of storage solutions isn’t just about speed. It’s about ensuring that storage solutions can scale with the growing demands of AI. Dell’s approach is rooted in the idea that data is the most critical asset in any enterprise, and having the right tools to manage and store that data is key to enabling AI’s potential. As Rob highlighted, Dell is working to ensure that all of its storage products are prepared for the future, with a strong focus on making data easily accessible and manageable.
One of the highlights of the conversation was Dell’s broader vision for data storage. Rather than simply providing individual storage products, Dell’s focus is on offering complete solutions that address the full spectrum of customer needs. The Dell Data Lakehouse, for example, is a powerful tool designed to unify storage, PowerEdge and software features into a comprehensive solution. This platform is designed to support AI applications by providing a reliable and scalable data management system that can handle the vast amounts of unstructured data AI processes require.
Throughout the discussion, it became clear that Dell’s role in the AI ecosystem goes beyond just providing storage solutions — it’s about creating a seamless environment where data can be used effectively to drive innovation. As Rob pointed out, the enterprise sector is just beginning to fully embrace AI, and Dell is committed to helping them navigate that transition. By ensuring that storage products can meet the needs of AI applications, Dell is positioning itself as an essential player in the future of enterprise AI.
In an industry where storage often takes a backseat to more glamorous technologies like GPUs and inference engines, it was refreshing to hear a conversation that highlighted the importance of reliable, high-performance storage. After all, as Rob noted, if the storage fails, the data is lost, and with it, the entire AI workload.
The partnership between Dell and Solidigm, known for their high-capacity quad-level cell (QLC) drives, further demonstrates the importance of resilient, high-performance storage. The TechArena take? By working together, Dell and Solidigm are able to provide a robust storage infrastructure capable of supporting the intense demands of AI environments, ensuring that customers’ data is safe and accessible.
To learn more about Dell’s cutting-edge storage solutions and their ongoing advancements in AI, visit the Dell InfoHub (infohub.delltechnologies.com) or check out their Unstructured Data Quick Tips blog for the latest updates.

Putting the AI Pieces into the Sustainability Puzzle
AI is revolutionizing industries and transforming our daily lives, but as we harness its power, it is crucial to consider its impact on the environment. Last week, at the GreenAI Summit, there was plenty of discussion around how AI impacts the environment and policy. A common theme was the significant energy demand that AI will put on IT, compute facilities, local and state environmental impacts, and, of course, the utility and water grids. With the speed at which the IT industry is moving, AI systems are already getting fragmented, and we have quickly moved to a decision-making era where “one size doesn’t fit all” when it comes to the type of AI system to build and where to run it.
Let us start with the distinctions between agentic AI, generative AI (Gen AI) and instinctive AI.
Initially, there was only Gen AI. We all have used Gen AI to create new content, such as text, images and music. Gen AI systems use machine learning algorithms to generate outputs based on patterns learned from existing data. Examples include OpenAI’s GPT-3, which can generate human-like text, and DALL-E, which creates images from textual descriptions. These are the “culprits” that give AI a bad name. Since they consume so much energy, they have raised many environmental and sustainability issues — and rightly so! IDC forecasts that AI data center energy consumption will grow at a compound annual growth rate (CAGR) of 44.7%, reaching 146.2 terawatt-hours (TWh) by2027. Put another way, that’s more than Sweden’s annual energy requirements(121 terawatt-hours of power).
Quickly on the heels of Gen AI came agentic AI. Agentic AI refers to AI systems that can autonomously perform tasks and make decisions based on predefined goals. They are designed to act independently, often mimicking human behavior. Suddenly, it seemed that every software and data management company was building AI agents — flooding the data centers with significant unplanned compute and storage requirements. Some examples of agentic AI include autonomous vehicles, robotic assistants and intelligent personal assistants, like Alexa+. However, agentic AI did not address the energy consumption issue, especially those involving robotics and autonomous vehicles — another bad rap!
And finally, the AI system that I find very cool — instinctive AI. Instinctive AI refers to AI systems that mimic instinctive human behaviors and responses. These systems are designed to react to stimuli in real-time, similar to how humans instinctively respond to their environment. Examples include AI-driven chatbots that provide instant customer support and real-time fraud detection systems. Instinctive AI brings two challenges to the energy consumption and emissions footprint debate: continuous real-time processing, which can be energy-intensive, but also have difficulty scaling effectively without compromising performance. I think that the business benefits, such as being able to provide instant solutions and support, enhancing user satisfaction and improving operational efficiency, will take priority over environmental concerns.
These AI systems create applications and workloads that require careful placement in any IT infrastructure. With environmental sustainability being the leading goal or criteria, businesses should look at a range of data center options. Cloud service providers offer the lowest levels of carbon intensity, while co-locations have low carbon intensity for sovereign AI. On-premises or enterprise data centers solve the “data gravity” challenge, where the compute resources are close to the data, whereas enterprise edge computing platforms offer the best inferencing environments, but at the cost of the highest carbon intensity.
Sustainable AI represents a crucial intersection between technological advancement and environmental stewardship. By understanding the differences between agentic AI, generative AI and instinctive AI, we can better assess their impact on the environment and leverage their benefits to promote sustainability. While challenges such as energy consumption and resource usage need to be addressed, the potential of AI to drive efficiency, innovation and data-driven decisions offers a promising path towards a greener future.

OVHcloud Innovates Cloud Infrastructure with AI, Sustainable Tech
At this year’s CloudFest, we caught up with Chris Ward, senior sales account manager at Solidigm, and Guillaume Gojard, product director at OVHcloud, to dive deeper into OVHcloud’s unique infrastructure strategy, its evolving role in AI and its long-standing commitment to sustainable innovation. Amid the cloud announcements and industry buzz, OVHcloud stood out for how it’s quietly reshaping the cloud landscape — one custom-built server and water-cooled data center at a time.
At a time when cloud providers are often defined by how they manage their hyperscale partnerships, OVHcloud stands apart by owning its full value chain. The company builds its own servers at facilities in both Europe and North America, operates more than 40 data centers worldwide and manages its own global fiber network. This level of integration isn’t just about control — it enables OVHcloud to deliver a price-performance ratio that resonates, particularly in today’s AI-hungry world.
And AI is everywhere. “It’s in every mouth,” Guillaume said, capturing the sentiment that defined the expo floor this year. For OVHcloud, this isn’t about scrambling to catch up. It’s about expanding what they started years ago. The company has been offering GPU-based compute since 2017, and it recently began rolling out ready-to-use large language models (LLMs) and AI endpoints — giving developers a practical starting point to integrate generative models into their stack. OVHcloud is pairing its AI push with an upcoming data platform designed to streamline how customers manage and leverage data inside complex workflows.
But the conversation didn’t stop at AI. Another topic discussed was OVHcloud’s long-standing use of water cooling, which is now getting mainstream attention. “And for example, water cooling with one glass of water, we can cool down one server for 10 hours of use,” Guillaume explained, noting that the company’s approach uses seven times less water than the industry average. That’s not a gimmick — it’s industrial innovation rooted in sustainability. It’s also a reminder that OVHcloud isn’t jumping on trends — they’re often ahead of them.
A large part of that innovation comes through partnerships. In this case, OVHcloud’s collaboration with Solidigm has allowed the company to push high-performance storage capabilities in its high-grade servers. “Blazing fast data access on our NVMe storage capacity, which is really great, because this is what the market demands,” Guillaume explained. For demanding use cases like real-time analytics, that speed translates directly into customer value. More importantly, the partnership gives OVHcloud the flexibility to respond to shifting demands — something Guillaume said has been smooth and responsive from day one.
Looking ahead, OVHcloud’s eye is on quantum computing. OVHcloud is supporting startups and even has a quantum computer. The company is also quietly building a quantum-friendly cloud platform, positioning itself to support ecosystems that will, like AI, demand entirely new infrastructure paradigms.
The TechArena take? In an industry full of noise, OVHcloud’s approach is refreshingly holistic. From LLM toolkits to next-gen cooling to the quantum horizon, it’s not just about where things are now — it’s about where they’re headed.

M2M and Solidigm Lead Industry Trends in AI and Cloud Computing
At CloudFest 2025, Khilna Chandaria, operations manager at Solidigm, caught up with Charlie Hacker, sales and marketing director at M2M Direct, and TechArena to chat about the latest trends in cloud computing and the innovations that are reshaping the industry. The conversation highlighted the growing importance of AI, the rising demand for high-capacity storage and the key attributes businesses are seeking in their cloud solutions. As cloud computing continues to evolve, M2M’s consultative distribution approach is helping organizations adapt to these changes, particularly through their collaboration with Solidigm.
The shift toward AI-driven cloud computing was one of the key topics of discussion.
“Cloud computing is shifting to an AI-based model, both for private and public clouds,” Charlie shared. This shift is reshaping how cloud environments are used, enabling businesses to handle larger amounts of data with greater efficiency and scalability.
As cloud adoption accelerates, businesses are looking for solutions that offer flexibility, scalability and competitive pricing. “Flexibility and price, price or flexibility, either or,” Charlie explained, emphasizing the trade-offs many organizations are grappling with when choosing their cloud partners. But these aren’t the only important factors. Scalability is also essential, as businesses must be able to expand their storage and processing capabilities as their needs grow.
Security is another major consideration in today’s cloud landscape. With more data being transferred across private and public clouds, keeping that data secure is a top priority. As businesses increasingly rely on cloud solutions to store and process sensitive information, they must prioritize robust security measures that can protect against cyber threats, ensuring both compliance and the integrity of their data.
One of the most pressing needs in cloud computing today is high-capacity data storage. As AI and other data-intensive technologies continue to advance, the demand for larger, faster storage solutions is growing at a rapid pace. “Size, size, size, size,” Charlie remarked, stressing how critical storage capacity has become in the face of AI’s massive data requirements. Solidigm’s quad-level cell (QLC) products, offering up to 122 terabytes of capacity, are meeting this demand head-on. With such large-scale storage solutions, businesses can manage and process enormous datasets efficiently, without sacrificing speed or performance.
M2M’s role in this evolving landscape is to provide not just products, but consultative services that help businesses navigate the complexities of cloud migrations and data center upgrades. “We’re like a sales arm for Solidigm, and Solidigm is a sales arm for us,” Charlie explained.
What’s the TechArena take? Collaborations like this one between M2M and Solidigm ensure that cloud infrastructure providers can deliver the right products at the right time, supplying on-demand solutions that are essential for businesses undergoing significant infrastructure changes.
For those interested in staying updated on the latest advancements in cloud computing and AI, Charlie encouraged viewers to follow M2M on LinkedIn and visit their website (m2m-enterprise.com) for the latest product offerings and updates.

Insights with Intel on Navigating Agentic AI Transformation
At TechArena, we’re continuously exploring the ways AI is shaping industries, and my recent Fireside Chat with Lynn Comp, VP and head of Intel’s AI Center of Excellence, brought to light some thought-provoking insights. One major takeaway: agentic AI is set to disrupt how enterprises manage their workflows, data and infrastructure.
During our chat, Lynn provided an in-depth look at how enterprises are navigating their AI journeys, moving beyond traditional machine learning (ML) to embrace more advanced approaches, such as generative AI and agentic computing. For Lynn, this shift begins with data — specifically, the ongoing challenges around data governance and readiness that continue to hinder enterprise AI adoption.
Lynn highlighted a key point that underpins all AI systems: it all starts with data. Whether it’s structured databases or the increasingly popular vector databases for generative AI, data management remains a significant challenge. For enterprises implementing agentic AI, the complexity ramps up even further, as multiple agents can sample data from
different sources, leading to potential misalignment. The need for observability in these systems is critical to avoid costly errors and ensure that the right data is being used by the right agents at the right time.
As enterprises explore agentic AI, Lynn also addressed the computational demands that come with it. The need for more powerful infrastructures that can handle the increased traffic between agents and the massive data flows of generative AI models is becoming evident. This is not just about scaling; it’s about optimizing performance while managing cost variability — another factor many enterprises are grappling with as they explore cloud-native solutions and increasingly complex workflows.
Lynn also delved into the commercialization challenges that lie ahead for agentic AI, particularly when it comes to interoperability and creating a thriving ecosystem. Drawing parallels to cloud-based services, she highlighted how successful agentic computing will require an open framework, akin to a software-as-a-service model, where agents can communicate seamlessly across different platforms. Google’s recent developments around their agent-to-agent platform point toward the necessity of such interoperability to avoid a lock-in scenario. By enabling agents to exchange data across ecosystems, enterprises can unlock the full potential of AI while maintaining flexibility.
Building out a marketplace for agents — where enterprises can purchase and implement AI tools based on specific needs — is another hurdle to overcome. Lynn emphasized that while the technology is promising, organizations will need to ensure that usage models are clear and predictable, especially in terms of cost. Enterprises are currently challenged by a lack of standardization in how agents are priced, with complexities such as pay-per-use and time-of-use models still in the works. Without clear pricing structures and observability tools, organizations will struggle to scale AI effectively while avoiding unforeseen financial burdens.
Looking ahead to the next 12 to 18 months, Lynn stressed the importance of laying a strong data foundation. For businesses, this means focusing on data pipelines and architectures that are flexible enough to support a variety of AI applications. Whether implementing machine learning or natural language processing, organizations that can build adaptable systems will be in a better position to leverage agentic AI for everything from logistics optimization to advanced predictive analytics.
What’s the TechArena take? In the fast-moving world of agentic computing, the next few years will be critical. As Lynn pointed out, the real breakthroughs will come when enterprises, hyperscalers and startups work together to build scalable, interoperable and user-friendly AI ecosystems that will transform industries and business processes alike. At TechArena, we can’t wait to see how these developments unfold — and to continue bringing you the latest insights on the intersection of AI and enterprise innovation.
Check out the full Fireside Chat. To keep up with Lynn and her insights on AI, connect with her on LinkedIn, where you can also check out her recent blog posts on agentic AI and scaling AI.

Oracle Unlocks Telecom’s Future With AI-Driven Network Automation
At TechArena, we’ve been closely following the transformative potential of AI in various industries, and after recently sitting down for a conversation with Solidigm’s Jeniece Wnorowski and Oracle’s Andrew De La Torre, one thing is clear: AI is revolutionizing how the telecommunications industry operates. From network management to customer service, AI is enabling telcos to optimize their operations and pave the way for the future of digital connectivity.
During our chat, Andrew explained how Oracle is at the forefront of AI-driven network automation, particularly in integrating AI with telecom infrastructure. As 5G networks continue to expand and evolve, the need for more efficient, scalable and autonomous systems becomes even more apparent.
The Shift Toward Autonomous Networks
Telcos are undergoing a massive migration from traditional telecom networks to autonomous ones, utilizing the migration to 5G to fuel new capabilities that speed and simplify network management. Andrew described how the integration of AI ops is essential to unlocking the full potential of these self-healing, self-optimizing networks. While it may sound like something from a sci-fi novel, the idea of a network that can monitor, troubleshoot and repair itself with minimal human intervention is becoming a reality.
This vision of an autonomous network is not just about improving efficiency; it’s about enabling telecom companies to deliver services more nimbly and improve service reliability at a fraction of the cost. Oracle’s focus on integrating AI capabilities into every layer of the telco stack — from cloud native infrastructure to front office applications — demonstrates the company’s commitment to transforming the industry.
AI Ops: A New Framework for Telecom Transformation
So, what is AI Ops? At its root, it is a framework designed to automate telecom network functions, which is essential for handling the complexity of 5G networks while minimizing manual intervention. Andrew explained that the key to building autonomous networks is the integration of cloud-native applications, data aggregation and AI analytics. By combining these elements, Oracle helps telecom providers to make data-driven decisions that improve performance and reduce operational costs.
For example, Oracle’s AI models can analyze vast amounts of network data to identify issues before they become critical. This predictive capability allows for proactive troubleshooting and service optimization, which ultimately leads to improved service uptime. With the rise of 5G, increased use of edge computing, growth in IoT and the resultant increased demand for data, this type of automation is becoming less of a luxury, and more of a necessity.
Generative AI vs. Traditional Machine Learning: What’s in Play for Telco?
One of the most insightful moments of the conversation came when Andrew addressed the role of different types of AI technologies in telco. While generative AI is making headlines, he emphasized that AI in telco is a diverse toolkit, with applications ranging from robotic process automation to advanced machine learning techniques.
Andrew pointed out that the telco industry is unique in its complexity, which is why specialized AI models tailored to telco use cases are so essential. AI’s ability to handle large-scale, repetitive tasks — such as network monitoring and optimization — while also supporting more advanced functions, such as natural language processing, is key to driving digital transformation.
The Human Element in AI-Driven Network Automation
Of course, the integration of AI into telco networks doesn’t come without its challenges. Andrew noted that the industry’s slow adoption of automation is partly due to deeply ingrained legacy infrastructure and attitudes. Networks are essential to national economies, and the cautious pace of change is understandable. However, Oracle is actively helping operators to navigate this transition.
Through tools such as automated test repositories and software solutions, Oracle is enabling telco providers to adopt a cloud-native mindset and deploy DevOps-style operations. The human element remains essential in this journey — operators need the right training and support to manage these new AI-driven systems effectively.
The Road Ahead: A More Connected, Autonomous World
In the grand scheme of things, AI-driven network automation is setting the stage for a future where telcos can deliver faster, more reliable and more cost-effective services. By embracing AI ops, Oracle is helping its clients build the autonomous networks of tomorrow — networks that promise to be smarter, faster and more responsive to the needs of both consumers and businesses.
At TechArena, we’re always on the lookout for stories that highlight innovation and transformation in the tech industry. We’re hot on the trail of AI Ops and its control of the IT infrastructure that will...accelerate broader application of AI. The insights shared by Andrew on Oracle's innovation demonstrate that AI Ops has survived the trough of disillusionment and is moving forward into real world deployment. The capabilities at stake will deliver a nimble edge, and provide telcos their potential edge for long term financial prosperity. We’re delighted to see it as fast and ubiquitous networks are a core of broad technology innovation.
Check out the full podcast.
To learn more about Oracle, visit their website at oracle.com.

Solidigm Spotlights AI Storage and Liquid Cooling at OCP
From breakthrough 122TB SSDs to the industry’s first liquid-cooled storage, Solidigm’s Avi Shetty unpacks how storage is powering AI workloads from hyperscale to neo-cloud.

OCP EMEA Summit Highlights: The Race to 1MW IT Loads per Rack
At the recent Open Compute Project Foundation (OCP) Summit in Dublin, one of the major announcements was Google’s unveiling of the 1 megawatt (MW) IT Rack. As AI continues to disrupt the IT landscape, it is also pushing the boundaries of the physical infrastructure in the data center. And it’s not just power — it’s the cooling, space and mechanical engineering required to support all this. In this article, I’ll outline some of the observations and insights I took from the regional OCP summit with regard to rack and power.
Status Quo
As a quick high-level baseline, let’s start with the status quo: the OCP rack specification is often referred to as “Open Rack,” followed by a version identifier. The current mainstream version you’ll find in most data centers is Open Rack Version 2 (ORV2). This version is powered by a 12-volt busbar. Unlike traditional 19" racks, where every piece of equipment has its own power connections and power supplies, the OCP racks and equipment are powered by a centralized busbar, which provides more efficient power delivery, saving 15% to 30% of power per rack! The ORV2 busbar runs at 12 volts, which, in this day and age, is challenged to support the more demanding IT workloads.
As such, ORV2 is in full transition to ORV3, which Google introduced in 2016. Version 3 increased the busbar voltage from 12 to 48 volts. This higher voltage allowed for more power to be delivered to the rack equipment, supporting compute-intensive workloads and the early AI accelerators.
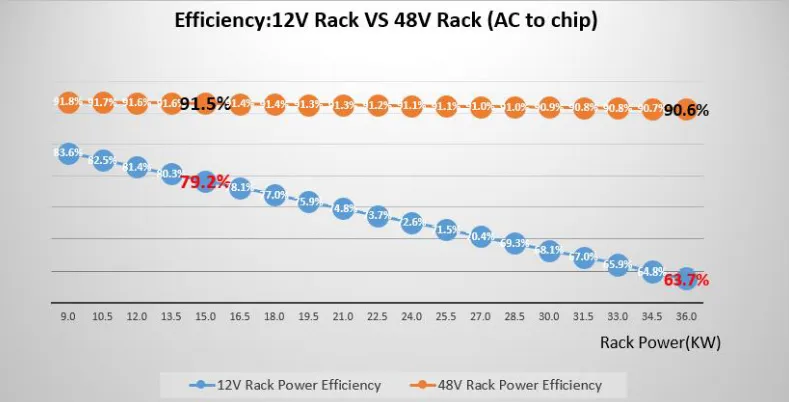
In addition to the increased 18 to 36 kilowatts (kW) of power, the ORV3 rack also brought new connectors and facilitated liquid cooling via optional rear-mounted manifolds, and it offers compatibility with 19" racks through adapters.
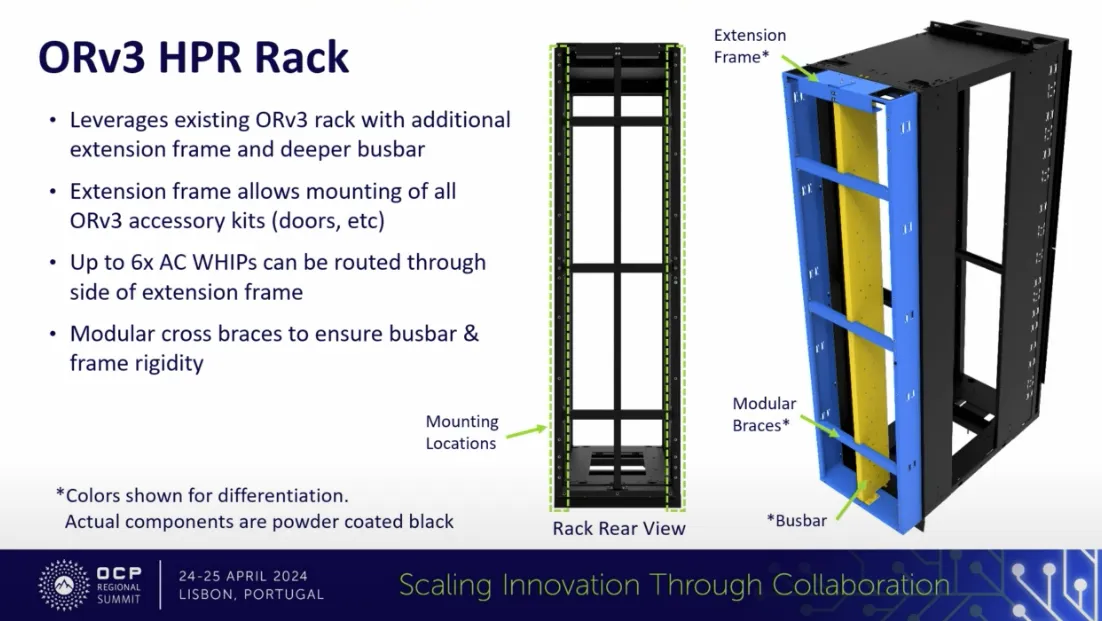
However, as machine learning and AI development accelerated, and as core counts in xPUs (GPUs/CPUs/tensor processing units) started driving the power density per rack to new heights, a new power and cooling architecture was required. The hyperscalers and the OCP community responded with a new iteration called the ORV3 HPR configuration, which pushed power capacity beyond 92 kW per rack, with projected supported loads of up to 140 kW. One of the main differences between the standard ORV3 and the ORV3 HPR racks is a deeper busbar. In the HPR configuration, the busbar is extended and deepened to support this capacity, while remaining compatible with standard ORV3 equipment.
This was pretty much the status quo until the Regional Summit 2025, when Google, together with Meta, Microsoft and the OCP, announced they are working on 0.5 spec for Mount Diablo, which will outline the next jump in rack and power architecture. The specification will detail what power delivery will look like when it jumps from 48 volts to 400 volts, supporting a staggering 1 MW of IT load per rack.
ORV3 HPR Next
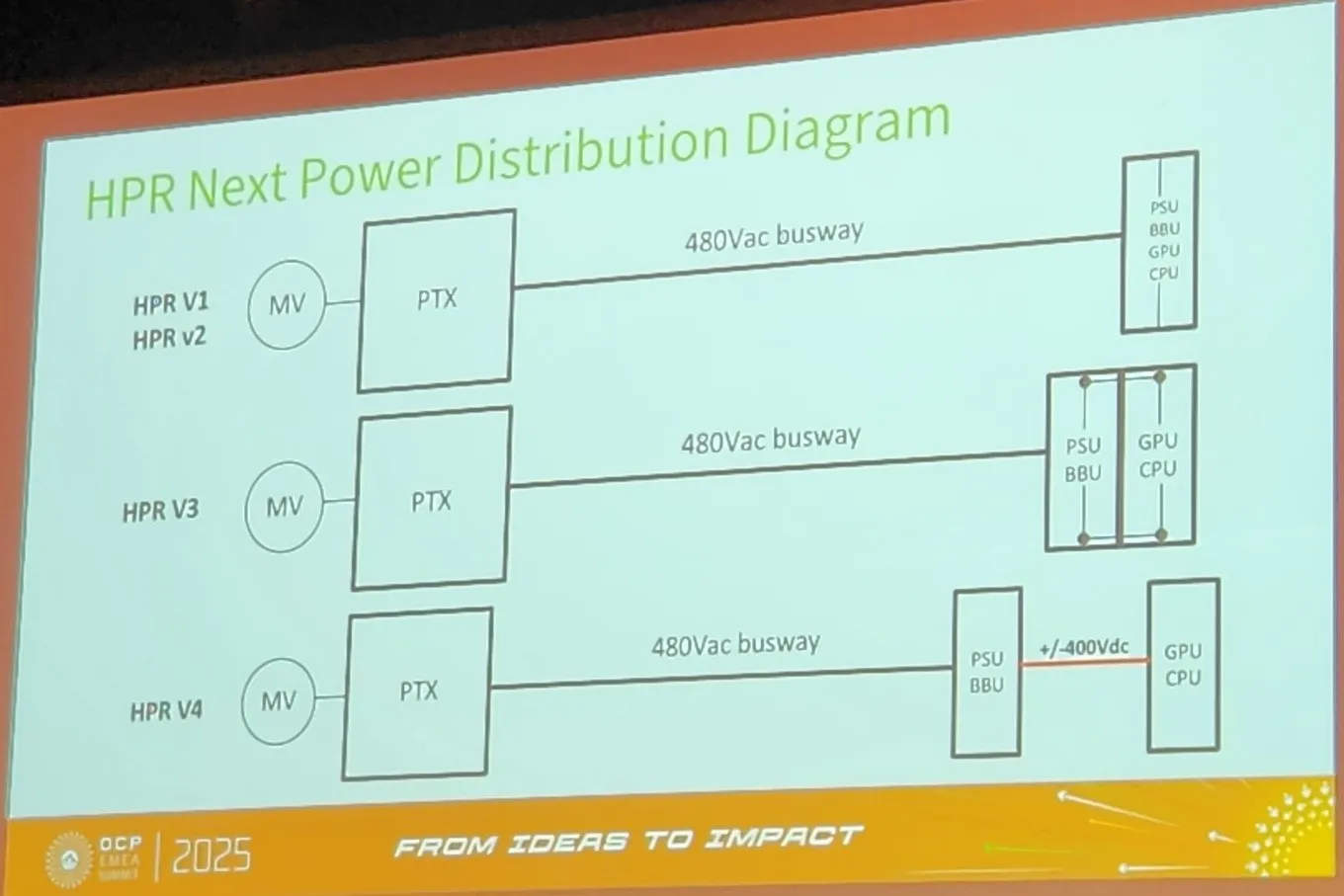
The need to support these types of capacities drives the evolution of AI. Typical enterprise and cloud workloads still fit well within the ORV3 power envelope, but hyperscalers have realized that supporting AI infrastructure in a single rack is quickly becoming unrealistic due to the power density. Ultimately, the solution lies in separating power and compute into disctinct racks, which we’ll refer to as “disaggregate power rack” going forward. At the OCP Summit, Meta took the stage for the first time to discuss ORV3 HPR Next and laid out a roadmap, which included three scopes of projects. The following information is directly from their slides at OCP Summit:

Each of these projects will increase the power capabilities of the racks to support next-generation AI workloads, but they will also come with their own architectural changes. ORV3 HPR V1 and V2 will still be singular rack designs with upgraded power supply units. However, to support the increased power delivery on the busbar, a new water-cooled version is required to keep the temperature rise within the max of 30°C T-rise as specified. The following information is directly from their slides at OCP Summit:

The first implementation of the liquid-cooled busbar was on display at the OCP showcase by TE Connectivity. The current busbar taps out at about 120 to 140 kW; applying liquid cooling to the busbar extends the operating range to 750 kW! Beyond that, design changes such as a deeper busbar with even more cooling plates will enable future scalability.

The first segregation of power and compute is when we scale beyond 200 kW capacity.
Initially, in V3, there will be a vertical busbar, which in V4 will be replaced by power cables to minimize current losses. Clearly, this work is not the current priority for most tier 2 data centers, as these volumes and workloads are primarily the domain of the hyperscalers. But they are a bellwether of things to come.
As power capabilities grow, so too must their cooling capacity. Liquid cooling has emerged as the solution to meet this challenge.
According to this piece by Google Cloud, water can transport approximately 4,000 times more heat per unit volume than air for a given temperature change, while the thermal conductivity of water is roughly 30 times greater than air.
A coolant distribution unit, or CDU for short, is a system that circulates liquid coolant to remove heat from data center equipment. These solutions scale as the power capabilities of the rack scale. Google shared a picture of the fourth-generation CDU, which has redundant heat exchanger pumps. The fifth generation of this CDU, codenamed Project Deschutes, will be contributed to the OCP later this year to accelerate the adoption of liquid cooling at scale!
Now, there are many details and nuances to all of this. The upcoming Mount Diablo specification will unveil more detail, and if this is close to heart for you, then I would encourage you to join the monthly OCP Power & Rack community calls to listen in or actively partake! Also, consider joining the next OCP summit, as it’s such a great place to keep a pulse on industry developments.
Rarely are hyperscalers so open about their designs and plans, and it’s a chance to connect with expert engineers and startups alike. The data center is transforming to cope with the massive disruption of AI.
While this is all very exciting, I would be remiss not to mention that the OCP community is also starting to actively track the requirements for quantum computing, which, currently, is hard to even define in a rack standard, but requires a more holistic approach and is yet another challenge for the data center to tackle in the near future!

Giga Computing Scales OCP Innovation with Giga PODs
From GPU and storage servers to turnkey rack-scale solutions, Giga Computing showcases its expanding OCP portfolio and the evolution of Giga PODs for high-density, high-efficiency data centers.

Zero Point Technologies on NeoCloud and the Future of AI Infra
At OCP Dublin, ZeroPoint’s Nilesh Shah explains how NeoCloud data centers are reshaping AI infrastructure needs—and why memory and storage innovation is mission-critical for LLM performance.

Supermicro and Solidigm: Revolutionizing Storage for AI Workloads
NVIDIA’s GTC is always a hotspot for innovation. This year, two industry leaders, Supermicro and Solidigm, brought their cutting-edge solutions designed for the next wave of AI workloads for CSP and Hyperscalers. From high-density storage to powerful cooling solutions, their collaboration is shaping the future of data centers. Wendell Wenjen, director of storage market development at Supermicro, and Shirish Bhargava, of Solidigm’s global field sales, sat down with TechArena to discuss how their partnership is addressing the growing demands of AI and what lies ahead for next-generation data center infrastructure.
Supermicro, known for pushing the envelope in server technology, showcased their latest systems directed at powering AI applications. Central to their presentation was the NVIDIA HGX B300 NVL16, featuring the powerful NVIDIA Blackwell UltraGPUs— Supermicro’s most advanced GPU solutions to date. These high-performance servers were designed with AI in mind, supporting the growing demand for deep learning and large-scale data processing. Supermicro also introduced a range of storage solutions optimized for AI workloads.
Another exciting announcement was the launch of a new 1U Petascale storage system, equipped with the NVIDIA Grace CPU. This dual-die, high-performance processor delivers impressive power efficiency, ideal for the ever-growing demands of AI. For those seeking even more storage efficiency, Supermicro unveiled a JBOF system powered by NVIDIA’s BlueField-3 DPU, which supports demanding storage workloads with lower power usage.
However, it wasn’t just Supermicro’s hardware that drew attention at GTC. Solidigm, a leader in enterprise solid-state drive (SSD) solutions, brought its own innovative technology to the table. The Solidigm D5 P5336 SSD, a 122 TB powerhouse, was also on display, offering extreme storage density that is essential for AI training and large-scale data management in all form factors. This SSD is part of Solidigm’s broader portfolio designed for AI, providing the kind of performance and capacity needed to handle massive datasets with low latency.
But what makes this collaboration truly stand out is the shared commitment to pushing the boundaries of storage capacity and efficiency. Supermicro and Solidigm’s joint focus on reducing data center footprint while maximizing storage capacity is a game-changer. By using Solidigm’s 122 TB quad-level cell (QLC) SSDs, Supermicro is able to pack three petabytes of storage into a 2U server, a dramatic leap from the previous one-petabyte systems. This compact, high-capacity solution not only optimizes data center space, but also reduces power consumption, making it a win-win for enterprises and service providers alike.
In an industry where cooling and power efficiency are critical, Supermicro’s approach to liquid cooling for high-performance GPUs stood out. Some of today’s most powerful GPUs can consume over 1,000 watts, making liquid cooling a necessity for keeping systems running at optimal temperatures. Supermicro’s comprehensive liquid cooling solution — ranging from cold plates for CPUs and GPUs to large outdoor cooling towers — ensures that even the most demanding AI systems stay cool, efficient and reliable.
So, what’s the TechArena take? This partnership between Supermicro and Solidigm is a testament to the importance of collaboration in driving innovation. Both companies have long been at the forefront of their respective fields, and their combined efforts are delivering practical, high-performance solutions to address the challenges of modern AI workloads.
For those looking to learn more, Supermicro offers an abundance of resources on their website (supermicro.com) and social media channels (X, LinkedIn and YouTube).

Solidigm & Supermicro Bring AI Storage to New Heights
From 122TB QLC SSDs to rack-scale liquid cooling, Solidigm and Supermicro are redefining high-density, power-efficient AI infrastructure—scaling storage to 3PB in just 2U of rack space.

Circle B Delivers End-to-End OCP Innovation in Europe
From full rack-scale builds to ITAD, Circle B is powering AI-ready, sustainable infrastructure across Europe—leveraging OCP designs to do more with less in a power-constrained market.

Bel Power Scales Up for AI-Hungry Data Center Racks
At OCP Dublin, Bel Power’s Cliff Gore shares how the company is advancing high-efficiency, high-density power shelves—preparing to meet AI’s demand for megawatt-class rack-scale infrastructure.

Will OCP Infiltrate NeoCloud?
The Open Compute Project Foundation (OCP) has undeniable impact on cloud deployments, and with $191B in forecasted infrastructure sales by 2029, there is no slowing this segment of the market. But many ask if OCP can transcend their current focus on hyperscalers to engage with neo-cloud providers. Who is neo-cloud? If you’re not familiar with the term, they are the large-scale players building infrastructure custom designed for AI workloads. Think CoreWeave, Lambda…or regional players like ScaleUp. And instead of building infrastructure to fail, as has been the case with the built in redundancy of the cloud, they are building infrastructure to scale to deliver the horsepower required for every aspect of AI.
OCP has been very CPU focused on its specs and marketplace, and with NVIDIA bringing some initial designs into the OCP ecosystem, the doors opened for neo-cloud influence. At the Dublin event this week, Solidigm, Fractile, FarmGPU, and ScaleUp discussed what it will take to make this segment of the market as robust as traditional hyperscale.
In the discussion, Fractile CEO Walter Goodwin pointed out that these players tend to push configurations even more aggressively, given the inherent challenges of accelerated computing. This can challenge traditional standards-based hardware’s speed of innovation. How can OCP deliver a standard without limiting designs to a perceived one-size-fits-all philosophy?
Discussion moderator Nilesh Shah from Zero Point Technologies pointed to an underlying change in infrastructure, moving towards a more storage-centric approach, including an example of OpenAI’s new storage-centric blueprint for accelerated computing. Finding a similar focus and pulling the storage industry closer into the center of OCP, he argued, would bring new approaches to configuration alternatives. Beyond storage centricity, Nilesh pointed to broader diversity of silicon design foundations for innovation, providing operators with different options for AI acceleration. Walter agreed, stating that his company’s planned product introduction in 2027, aimed at competing with NVIDIA GPUs, is designed for the rack and facility level – exactly where neo-cloud vendors are seeking accelerator alternatives.
JM Hands, CEO of FarmGPU, suggested that another opportunity for neo-cloud traction involves adoption of a mix-and-match approach to configurations, delivering a higher level of customization and a deconstruction of infrastructure to dial in exactly what providers need. Many of the challenges neo-cloud is grappling with, he argued, have been solved by the hyperscalers within OCP. Creating more flexible ways to tap this technology through the OCP marketplace would help spur interest and engagement from these service providers.
What’s the TechArena take? Neo-cloud is still arguably in its infancy. Yes, that is ridiculous given the valuation of some of these companies, but with AI moving so fast and furious, it’s hard to remember that some of these companies were not delivering services just a few years ago. Today, many neo-cloud providers are functioning as warehouses for NVIDIA configurations for hyperscaler consumption. Will they remain a function of outsourced compute for hyperscaler balance sheet management, or will their businesses take them further afield as more enterprises start adopting generative and agentic AI at scale? The discussion certainly underscored the challenge in data centers today that NVIDIA designs are taking some of the air out of the room for flexible innovation, and neo-cloud’s current reliance on NVIDIA GPUs certainly aligns with a narrower approach to deployments, at least in the near term. We applaud the call for more memory and storage-centric thinking, given the growing complexity of feeding AI and avoiding what we affectionally call agentic dementia, something we’ll cover in depth in an upcoming post. We see an acute opportunity for OCP, which is more of an imperative to capture the AI curve fully to build a vibrant ecosystem. We also see the industry – from chiplet designers to integrated rack manufacturers and power and cooling providers – benefiting through a widened view on the market opportunity from OCP-centric innovation. We’ll be watching attentively come October to see signs of significant traction in this space.

Optimizing AI Compute Value with OVHcloud’s Custom Infrastructure
At CloudFest 2025, OVHcloud shared insights on AI’s expanding role in cloud infrastructure, the benefits of custom-built servers, and how their global network is optimizing performance and efficiency.

Liquid Cooling Takes Center Stage at OCP Dublin
In this TechArena interview, Avayla CEO Kelley Mullick explains why AI workloads and edge deployments are driving a liquid cooling boom—and how cold plate, immersion, and nanoparticle cooling all fit in.

Giving Hardware a Second Life with Sims Lifecycle Services
At OCP Dublin, Sims Lifecycle’s Sean Magann shares how memory reuse, automation, and CXL are transforming the circular economy for data centers—turning decommissioned tech into next-gen infrastructure.

Silicon at the Edge of Innovation
Attending an Open Compute Project Foundation (OCP) conference provides a unique look at the bleeding edge of data center innovation, and this week’s event in Dublin has provided insight across the data center landscape. The foundation of advancement starts with silicon, and I was keen to see the latest technologies that are driving system capabilities forward. Here’s our quick take on the most interesting updates from the show.
Was the Elephant in the Room?
While NVIDIA was present across the show floor in vendor booths, they have been limited in their engagement within OCP shows. The most notable impact of NVIDIA’s recent contributions was seen in OCP CEO George Tchaparian’s keynote, during which he announced an IDC forecast of $191B of global OCP infrastructure sales by 2029, up significantly from the $73.5B forecasted for 2028 shared last year. This is reflective, at least in part, of the massive impact that NVIDIA spec and technical document inclusion within the organization’s offerings represents to uplift of OCP infrastructure sales. This opportunity was echoed by the prominence of NVIDIA systems within integrated rack configurations on the show floor, and centrality of NVIDIA within the first day’s sessions. In my mind, this expansion to accelerated computing is foundational for the next generation of OCP’s existence as it takes the organization into the heart of AI compute and makes the org’s programs relevant to the next wave of AI centric data center operators like CoreWeave, Lambda, and more (more on this in an upcoming post about the neo-cloud). The OCP Foundation doubled down on the importance of AI centric configurations, rolling out a new AI marketplace this week to serve as a central information hub for adopting AI configurations.
Who’s Up Next?
Of course, this is a bleeding edge tech conference, so TechArena is always looking for who’s going to emerge to compete with NVIDIA in the AI computing game.
Enter Fractile, the AI accelerator company that claims that they can deliver 100X faster inferencing at 1/10th the cost of existing systems.
While their first-generation product silicon has yet to tape out, Fractile has targeted their designs to solve a fundamental problem of current AI processing on GPUs – time and cost wasted in movement of data between memory and processor, and the resultant intractable trade-offs for inference between lowering costs and increasing speed.
Instead, Fractile CEO Walter Goodwin explained, the company is pursuing in-memory computing that fuses key calculations into memory structures, eliminating the friction and bottlenecking of constant movement of data between processor and memory. This means faster inferencing, and it also means reduction of energy consumption at scale, both capabilities that have garnered attention from the likes of industry heavyweights Stan Boland and Pat Gelsinger.
Goodwin has assembled a seasoned team – hardware, for instance, is led by ex-NVIDIA VP Pete Hughes. Time will tell if Fractile is the player to give NVIDIA a real challenge in the market. At this point it’s clear that at least in approach, they are taking a road that gives them an opportunity to compete at hyperscale.
What about Data?
With compute performance moving at hyper-Moore’s Law, pressure is increasing on other areas of the platform to keep pace. As we wait for in-memory compute to become reality, we need to take a look at discrete memory innovation. While HBM has provided fast delivery of data for AI systems, there are power and capacity limitations that make this technology imperfect for all target applications. ZeroPoint Technology’s Nilesh Shah shared his views in an OCP session stating that LLM’s today are memory bound with HBM GPUs operating at <60% of utilization and memory inference averaging a 6:1 read to write ratio. What’s more, current lossy-based memory compression technologies degrade application accuracy. New innovation is needed, and Nilesh pointed the way with a one-two punch of breakthroughs. The first is MRAM, a new memory technology that delivers HBM like bandwidth with 30-50% less power utilization. According to MRAM provider Numem, the technology is ready for mainstream adoption. But, the full story of memory innovation potential is, when coupled with a new approach in cacheline compression technology that avoids traditional lossy intolerance to nanosecond latencies, it delivers a 1.5X improvement in memory performance. ZeroPoint has introduced AI MX 1.0 to help the industry take advantage of this new approach with on-chip decompression engines…and in the near future compressions also brought on-chip.
Are We Talking Efficiency?
I expected compute and memory advancement at OCP, but Empower Semiconductor surprised me with their new technology that improves efficiency of power delivery on the board. They’re the world’s leader in integrated voltage regulation, reducing the need for on-board capacitors by deploying FinFast-based regulators on the backside of the PCB board and greatly reducing the distance that power is traveling across the board to get to host processors. Their solutions are increasingly tapped by hyperscalers to drive down power utilization and claim a reduction of up to 20% vs. traditional capacitor technology. What’s coming next? Integration of their Crescendo solutions directly into the chip, made possible by the physical size reduction of their designs vs. competitive alternatives.
What’s the TechArena take?
The biggest story of silicon innovation at OCP was more about who was not in the room – minimal presence from NVIDIA, AMD and Intel, to name a few – as much as who was present in Dublin. While OCP configurations deliver system- and rack-level standards-based advancement, we think that silicon driven configurations were lacking, at least within this event. And as the organization grapples with broader impact beyond hyperscalers, bringing new silicon players like Fractile to the table to drive disruptive innovation to the marketplace will help unleash a new wave of innovation that the industry sorely needs.

OVHcloud Brings Carbon Transparency to the Cloud
At OCP Dublin, OVHcloud’s Gregory Lebourg shares how the company is giving customers real-time visibility into the carbon impact of their cloud workloads — before they even hit deploy.

Intel’s Lynn Comp on Agentic AI: How Enterprises Can Prepare
Agentic AI is reshaping enterprise data, infrastructure, and governance. Intel’s Lynn Comp joins TechArena to explore how organizations can get ahead of the coming wave of change.

Synopsys, Intel Foundry Team Up to Spur Angstrom-Scale Innovation
APRIL 29, 2025: At Intel Foundry Direct Connect 2025 today in San Jose, Synopsys announced a major expansion of its collaboration with Intel Foundry, fueling a new era of high-performance chip design with certified, production-ready EDA flows, expanded IP portfolios, and next-gen packaging innovation.
When it comes to the future of silicon, Synopsys is pushing full throttle into the angstrom era. Building on a multi-year partnership with Intel Foundry, Synopsys unveiled several key initiatives to fast-track advanced node designs, from silicon to system, across Intel’s most cutting-edge process technologies — including Intel 18A and the new Intel 18A-P with its groundbreaking RibbonFET and PowerVia innovations.
Here are the high points:
1) Certified digital and analog EDA flows for Intel 18A are now ready for Intel customers, supporting faster, more efficient design starts.
2) Production-ready EDA flows for Intel 18A-P — the evolution of 18A featuring gate-all-around transistors and backside power delivery — are now available, built through early collaboration between Synopsys and Intel, informed by unique early DTCO work on Intel 18A.
3) Advanced multi-die design enablement is also on deck. Synopsys has developed an optimized reference flow for Intel’s new EMIB-T packaging technology, powered by its 3DIC Compiler platform.
4) Expanded Synopsys IP support for Intel’s angstrom nodes, with solutions designed to maximize performance, power efficiency, and silicon lifecycle management.
Synopsys also announced they’ve joined the Intel Foundry Accelerator Design Services Alliance, and are a founding member of the new Intel Foundry Chiplet Alliance, further deepening their leadership role in the Intel Foundry ecosystem.
What Makes This News Stand Out
The industry has been anticipating Intel 18A as a critical moment — not just for Intel’s re-entry into foundry leadership, but for the broader enablement of truly differentiated HPC silicon. PowerVia and RibbonFET technologies are redefining what’s possible in PPA (Performance, Power, Area) optimization, but designing on these advanced nodes requires a complete rethinking of traditional EDA flows and IP development.
Synopsys has done more than adapt. They leaned into early co-optimization efforts with Intel, notably through unique Design Technology Co-Optimization (DTCO) on Intel 18A, fine-tuning every stage from exploration to signoff, and enabling early adopters to move faster with fewer design iterations. This close collaboration continues, with Synopsys now engaged in DTCO work for Intel 14A-E.
Multi-die design is also a critical theme. With chiplets rapidly becoming a dominant architecture for AI accelerators, network processors, and HPC systems, advanced packaging solutions like EMIB-T — and the design tools that support them — will be make-or-break for innovation. Synopsys' unified 3DIC Compiler platform allows for exploration, planning, and multiphysics signoff in a single environment, which helps teams manage the complexity of heterogeneous integration at scale.
And on the IP side, the breadth of Synopsys' offering for Intel 18A is impressive. High-speed interfaces like 224G Ethernet, PCIe 7.0, UCIe, and USB4, along with critical foundation IP, such as embedded memories, logic libraries, IOs, and PVT sensors, all optimized for PowerVia and the unique characteristics of RibbonFET designs.
The TechArena Take
At TechArena, we see Synopsys' expanded collaboration with Intel Foundry as a key accelerant for the next wave of semiconductor innovation — especially in AI and high-performance computing, where the race for leadership is not just about process nodes, but about full-system optimization.
By delivering certified flows for 18A, production-ready flows for 18A-P, robust IP portfolios, and deeply integrated multi-die design capabilities, Synopsys is helping to de-risk early adoption of Intel’s most advanced technologies. This could open the door for a broader range of customers to confidently tape out designs on Intel 18A and 18A-P — and could ultimately help accelerate ecosystem momentum for Intel Foundry’s ambitious growth plans.
In an era where silicon leadership increasingly means system leadership, Synopsys isn’t just following the roadmap. They’re helping draw it.