
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















Inside OCP Innovation: A Fireside Chat with Matty Bakkeren
Ahead of OCP Dublin, Matty Bakkeren joins Allyson Klein to break down rack innovations, liquid cooling, sovereignty, and the trends shaping data center infrastructure across Europe.

.webp)
Creating a Foundation for End-to-End AI Security Solutions
Your organization has caught the generative AI fever and is rolling out chatbots powered by cutting- edge models that promise to reveal valuable new insights and deep data linkages —– all accessible via plain-language prompts. You’re probably considering Retrieval-Augmented Generation (RAG) to add private, context-specific data to the model to address the risks of hallucinations and out-of-date or missing contexts. Your development team is under pressure to be first to market, and the business team may even be experimenting with things like “vibe coding” to get there even quicker. You’ll test and learn and then refine as you go. You’re keeping your private data sources on-premises, so you should still be covered for confidentiality, privacy, and regulatory requirements, right?
But here’s the deal — Regulations generally trail innovation, but likewise fully-compliant, out-of-the-box solutions tend to trail the regulatory mandates as they begin to be established. The “run fast” mentality could put you on a collision course with safety in critical domains such as healthcare, finance, autonomous vehicles, and agentic systems where “breaking things” can mean disastrous consequences. So, the question becomes: how do we keep innovating at today’s breakneck pace — without breaking the trust, security, and safety foundations our systems depend on?
"Our approach to security must adapt to AI. Some controls, such as static defenses, signature-based detection, and perimeter-based security, will no longer work."
Not Just Another Workload
I’ve been around IT and Enterprise systems for a long time. I started during the “PC Revolution”, putting real data processing into the hands of ordinary consumers rather than just specialists with access to mainframes. Soon we were marching into the “Internet Revolution”, with all its interconnected glory and chaos. The “Cloud Revolution” followed, enabling IT departments to become more agile and efficient by breaking free from the constraints of physical location and infrastructure ownership. And now the “AI Revolution” is careening forward, promising to disrupt even the basic ideas of where data can come from and how it can be used. Each of these eras required new ways of thinking about how we approach the core tenets of compute.
My primary area of focus is how to protect these systems, the data they process, and users and organizations that live and die by them. That hasn’t changed, and most of the cybersecurity principles we’ve lived by continue to apply. We still need to address the fundamental triad of Confidentiality, Integrity, and Availability. We still need to monitor networks and assets, manage access controls, secure our supply chains, and so on. It’s tempting to think of AI as “just another workload” and assume we’ll simply protect it like any other compute, but AI brings unique challenges we never faced before, at unprecedented scale.
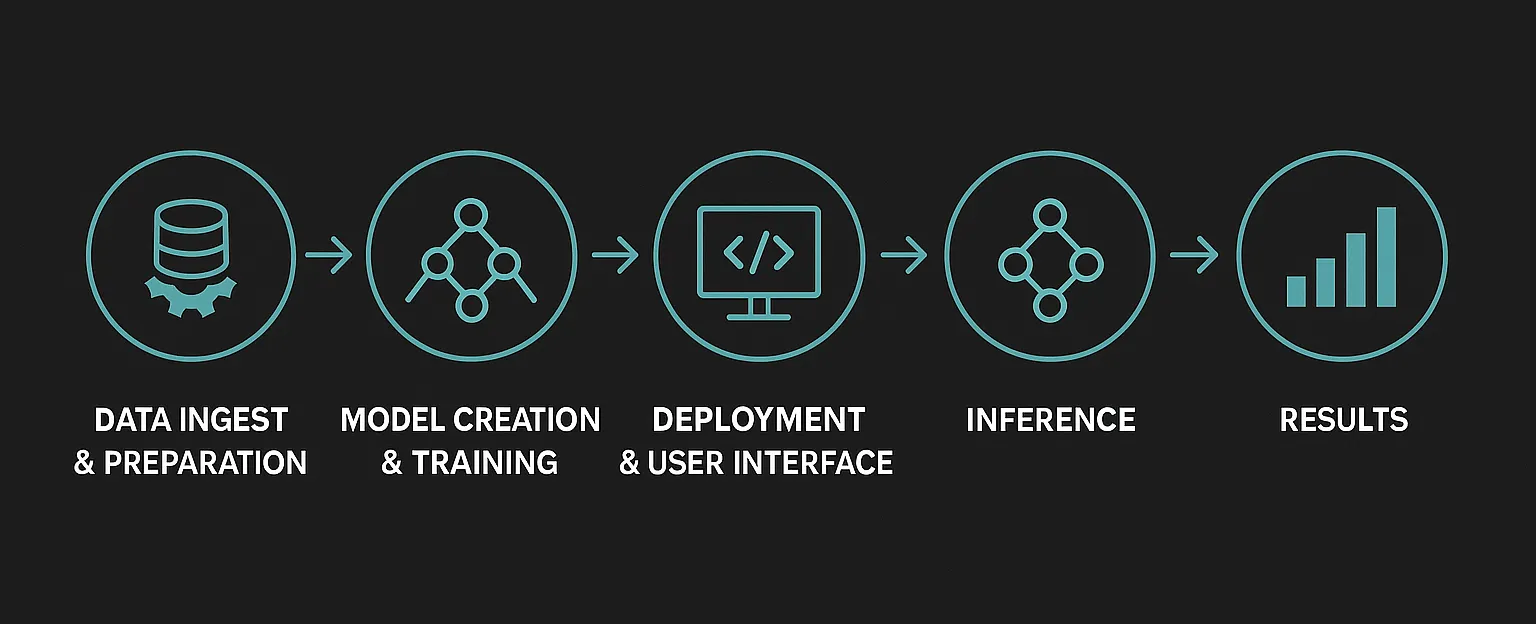
Scale and Unpredictability
I’ve noted two significant new factors. The first is the sheer volume of data involved. In the past, a program had specific and well-defined data sources and outputs. We knew what was going in, and how it would be processed; we were the ones deciding after all. But now we scoop up massive troves of data from previously unutilized sources. Different types of data, such as audio/visual, machine logs, multi-lingual, specifications and diagrams, out-of-date documents, and unsupervised social posts are all being pulled into training sets. Garbage in, garbage out. This makes me wonder how I ensure only valid, accurate, appropriate, and relevant data drives my AI when it literally could be anything.
The second major factor is the non-deterministic nature of AI. Sure, I set up data sources, I codify a model training structure, I sample and test the outputs. But I don’t know the linkages AI will find amongst all that data. I can’t evaluate each logic tree that led to a prediction. I won’t be able to fully anticipate the biases, blind spots, and misunderstandings that will be buried in a vector database and ultimately drive a decision. I’ve set up the arena, but the movements won’t always be what I expect, and my outcomes are determined by unknown probabilities rather than IF-THEN directives.
Our approach to security must adapt to AI. Some controls, such as static defenses, signature-based detection, and perimeter-based security, will no longer work. Others that were previously niche will become commonplace. We live in a world with billions of personal compute endpoints, fabulously interconnected across the internet, with access to infinite data hosted in the world’s clouds, but now we have an evolving and unpredictable logic operating across it all. These are exciting times full of promise, but we’d better not shoot ourselves in the foot as we race to realize it.
Start at the Foundation
We are starting to see some very good frameworks for addressing some of the unique aspects of securing AI. The OWASP Top-10 for LLMs and Gen AI Apps from the Open Worldwide Application Security Project is one these. It catalogues some of the primary vulnerability types, complete with attack scenarios and potential mitigations for each. MITRE’s ATT&CK framework and ATLAS are others for which Intel was a contributing developer. When assessing their security postures, most cybersecurity professionals consider network topologies, access controls, data architectures, DevOps practices, and more. Numerous software stack solutions are available to help solve this, and it’s generally taken for granted these will “just work” on whatever platform they reside on. But many still don’t consider the role the underlying platform plays in enabling secure solutions. Selecting the right foundation is actually your first security decision, and it can impact all the decisions that come after.
Defense-in-Depth: A Comprehensive Security Approach
Combating today's sophisticated threats requires a defense-in-depth strategy, where hardware and software are tightly optimized to enhance overall security. Intel has been a recognized leader in securing critical assets and data and offers a holistic approach to defend AI artifacts and workloads throughout their lifecycle.
Best-in-Class Platform Assurance
Product security is at the foundation of everything we do at Intel, and that’s proven by Intel’s number one rank in product security assurance compared with other top silicon vendors. Intel’s latest Product Security Report highlights how our proactive approach to identifying and mitigating vulnerabilities resulted in 96% of addressed vulnerabilities being were discovered by internal programs, rather than purely external researchers or attackers to find issues after-the-fact. AMD reported four times more firmware vulnerabilities in their hardware root-of-trust than Intel, and almost twice the number of vulnerabilities in their confidential computing technologies than Intel. This is especially significant since 43% of AMD’s platform firmware vulnerabilities were discovered externally.
Cryptographic Accelerators
Encryption and hashing sit at the heart of security solutions, and we just expect those to work. But we are approaching the era of quantum computing, where stronger algorithms and larger key sizes are required to resist the brute-force capabilities of future quantum computers. And these computationally-intense algorithms, in turn, put more strain on today’s processors. Intel is not only integrating the latest quantum-safe algorithms into our platform, but we’ve embedded encryption accelerators in our processors to support bulk crypto offload to significantly speed these computations and reduce the performance impact.
Hardware-Based Defenses
In protecting the application stack, security is only as good as the layers below it. Even the best application security techniques and architectures can be circumvented by vulnerabilities in the OS, attached components, supply chain, etc. This is why security should be rooted in the lowest layer possible, in the platform silicon. This begins with establishing a root of trust at the start of boot, with each level first validating the next before giving it permission to instantiate. Instructions in the processor can also identify and prevent return-oriented programming (ROP) and jump-oriented programming (JOP) attacks, which could be used to manipulate AI processing flows. And the processor also can provide low-level telemetry that can be utilized with AI to identify the processing signatures of ransomware and cryptojacking that would be otherwise undetectable by high-level monitoring.
"We’re stepping into a new epoch of compute. The old rules aren’t out, but new rules have been added, with more to come."
Confidential and Trusted AI
It’s common practice to encrypt data in-transit to protect against interception while it’s sent across the network. And more and more data is also being encrypted at-rest in case of malicious or accidental exfiltration from storage. But data exists in another state as well: in-use. In traditional computing, the data is in an unencrypted state while it is being processed in memory. This makes data in -use vulnerable to attack via malicious admins and malware that can exploit vulnerabilities at the OS layer to gain access. There are literally thousands of logged vulnerabilities that can result in an escalation of privileges, essentially granting root access for the attacker to access the contents of memory, including the data that would otherwise be encrypted at -rest and in -transit. But perhaps even more frightening are the zero-day vulnerabilities that haven’t yet been discovered and patched.
Confidential Computing technologies are rooted in hardware and provide trusted execution and encryption of memory, plus isolation and verification of the integrity of workloads, closing off low-level privilege escalations as a mechanism of attack. This is especially important where workloads run on infrastructure that is remote (such as edge) or not operated by the organization (such as in the cloud) but also applies for on-prem to reduce exposure to insiders and zero-days. Confidential AI solutions reduce the risk of attacks such as prompt injection, data and model poisoning, model theft, and sensitive data disclosure.
Conclusion
We’re stepping into a new epoch of compute. The old rules aren’t out, but new rules have been added, with more to come. We need to evolve our approach to security as well, with foundational capabilities rooted in the immutable core. Intel platforms have leading security built in by default, and deliver a security foundation to build upon.

Taurus Group Champions Open Infrastructure for Today’s IT Needs
In today’s rapidly evolving IT landscape, flexibility and adaptability are key to meeting the demands of businesses seeking innovative, scalable solutions. This shift in customer needs came into sharp focus at CloudFest 2025, where we sat down with Steve Gutierrez, director of sales at Solidigm, and Arun Garg, founder and CEO of Taurus Group. With a focus on open platforms and best-of-breed components, Taurus is providing businesses with the freedom to build the infrastructures they need, without being tied to a single-vendor, one-size-fits-all solution.
Taurus Group’s approach is centered around offering a diverse array of options to its partners, tapping into open compute platforms and leveraging the expertise of its sister company, Circle B, a specialized provider for the Open Compute Project Foundation (OCP). Alongside this, Taurus works closely with Cluster Vision to deliver high-performance computing solutions and open-source cluster management tools. These collaborations give Taurus the tools to provide cutting-edge, flexible infrastructure options while remaining agile enough to adapt to the unique demands of their clients.
Arun highlighted how important it is for businesses today to have the freedom to choose the best components for their needs, rather than relying on a single vendor’s ecosystem. The days of restrictive, monolithic IT systems with one-size-fits-all solutions are long gone — today’s customers are looking for more flexibility and the ability to customize their infrastructure.
Solidigm’s products, such as the recently launched 122TB storage solution, perfectly complement Taurus Group’s portfolio, offering innovative, reliable options for clients in need of scalable storage. According to Arun, customers appreciate the collaboration with Solidigm because it ensures that they can deliver the best possible solutions with the added benefit of excellent support from Solidigm’s technical and support teams.
What’s the TechArena take? The collaboration between Taurus Group and Solidigm is a great example of how true partnerships can help businesses deliver more powerful solutions to their customers. It’s clear that as companies like Taurus continue to push for openness and flexibility in the IT space, they’re creating a future where businesses are no longer constrained by traditional, single-vendor systems, but instead have access to a wide range of tools and solutions that are tailored to their needs.
For anyone looking to explore more about Taurus Group and how they can leverage the latest storage solutions, reach out directly through their website, tauruseu.com. With a clear focus on building strong, flexible partnerships, Taurus Group is poised to continue playing a key role in the future of IT infrastructure.

Synopsys + TSMC Angstrom-Scale AI Design
At the 2025 TSMC Technology Symposium today, Synopsys and TSMC revealed new milestones in their long-standing collaboration — signaling a major step forward for angstrom-era silicon design. With certified digital and analog design flows now available for TSMC’s A16™ and N2P nodes, the two companies are opening new pathways for semiconductor innovation, particularly in high-performance compute (HPC), AI, and multi-die architectures.
The announcement is packed with substance: certified EDA tools, new IP, deeper 3DIC integration, and early development for the next wave of process tech, A14. It all reflects a broader trend — the convergence of AI design complexity, extreme scaling, and ecosystem-driven innovation.
Angstrom-Scale Design, Accelerated
Certified Synopsys.ai-driven flows for both digital and analog design on TSMC’s A16 and N2P processes enable optimized performance, power efficiency, and rapid design migration. Enhancements such as backside routing and frequency-optimized logic placement in Fusion Compiler are designed to squeeze every ounce of efficiency out of GAA transistors — accelerating the transition from FinFET to gate-all-around.
While customers gain productivity today, the future is already in view. Synopsys is working closely with TSMC to develop flows for the forthcoming A14 process, giving design teams a head start on next-generation innovation.
Simplifying Complexity with 3DIC
As multi-die integration becomes the new performance engine for advanced workloads, the companies are also tightening their alignment on 3D packaging. Synopsys’ 3DIC Compiler — now certified for TSMC’s CoWoS® with up to 5.5x reticle interposers — enables ultra-dense chip stacking. That means customers can build larger, faster AI and HPC chips without waiting for smaller process nodes.
With support for 3Dblox and seamless integration of Ansys simulation technologies for thermal, power, and signal integrity, 3DIC Compiler offers an all-in-one toolkit for design exploration and signoff — critical for getting high-stakes multi-die systems to market quickly and reliably.
IP to Match the Mission
You can’t innovate at the edge of physics without the right IP — and Synopsys delivers it. The company announced first-pass silicon success for its Foundation and Interface IP portfolio on TSMC’s N2 node, giving customers the confidence to tape out with aggressive performance and power targets.
The IP stack spans industry-leading protocols including PCIe 7.0, HBM4, UCIe, USB4, LPDDR6, DDR5, and the newly added UALink and Ultra Ethernet technologies — reflecting the push for faster interfaces in data-hungry workloads. Synopsys’ 224G PHY IP, a cornerstone of this performance tier, is already demonstrating ecosystem-wide interoperability, including support for optical and copper links.
With this broad portfolio, customers building AI, HPC, edge, and automotive systems can reduce integration risk while maximizing bandwidth and energy efficiency.
The TechArena Take
This is more than a standard EDA/IP announcement. It’s a signal flare for where the semiconductor industry is headed — and how AI is shaping every element of innovation. From A16 silicon to multi-reticle packaging, to next-gen PHY IP, the collaboration between Synopsys and TSMC is pushing complexity behind the scenes so design teams can focus on what matters: delivering differentiated silicon.
It’s also an important marker for how platforms like Synopsys.ai are helping the industry move faster. As GAA nodes introduce new challenges in pin access, backside power delivery, and physical design, AI-native tools aren’t just “nice to have” — they’re essential.
And as 3D packaging becomes the standard rather than the exception, a unified environment like 3DIC Compiler becomes critical to maintaining speed and sanity in high-stakes design cycles.
At TechArena, we’ll be watching how this evolves — especially as the A14 node development matures and more chipmakers lean into multi-die architectures for inference acceleration, memory disaggregation, and compute scaling.
For now, one thing’s clear: Synopsys and TSMC are setting a new bar for collaboration in the angstrom era.
For More Information:
News release: Synopsys and TSMC Usher In Angstrom-Scale Designs with Certified EDA Flows on Advanced TSMC A16 and N2P Processes
Additional news blog post: First-Pass Silicon Success on TSMC’s N2 Process Will Enable New Generation of AI-Enabled Edge Devices

Scaleway’s AI Vision: Scalable, Sustainable Cloud Infrastructure
In a landscape often dominated by hyperscalers and familiar names, Scaleway is quietly rewriting the rules. With a clear vision and a sharp focus on what modern cloud scalers actually need, it’s stepping into a role that feels both timely and transformative. In a recent conversation between Solidigm’s Conor Doherty, field applications manager at Solidigm, and Yann-Guirec Manac’h, head of hardware R&D at Scaleway, we get a closer look at how this European cloud provider is not only keeping pace with hyperscale trends, but is also helping to shape them through focused innovation in AI infrastructure and sustainability.
Scaleway’s approach feels refreshingly grounded. It focuses on delivering a complete foundation — compute, network, storage — and binding it all together with a unified control plane that supports both traditional and AI workloads. But what really sets them apart is the dual-track strategy for AI: accessible GPU instances for smaller-scale use, and massive, tightly interconnected GPU clusters for the heavy-duty training jobs. It’s the kind of infrastructure that recognizes how AI work isn’t a one-size-fits-all operation — some tasks need 2 GPUs, while others demand thousands. Scaleway is designing for both.
Gaining a deeper understanding of Scaleway’s AI strategy starts with examining the data pipeline. As Yann-Guirec put it, AI training isn’t just compute-heavy — it’s about data complexity, scale and flow. Harvesting and curating vast datasets, handling throughput during training, managing checkpoints and doing inference all require different storage strategies. Cold storage for archival compliance, warm layers for preparation and hot storage for training — each has different hardware implications. It’s not just about speed, it’s about adaptability, and Scaleway’s infrastructure acknowledges that every phase in the AI pipeline has unique demands.
With the conversation around sustainability finally taking center stage in tech, Scaleway’s stance is more than a footnote — it’s core to their identity. Backed by the Iliad Group, the company has built and operates data centers that run on 100% renewable energy. DC5, the data center that houses a lot of their AI pods, forgoes traditional air conditioning in favor of adiabatic and free cooling methods. The result is dramatically lower power usage effectiveness without sacrificing performance. But Yann-Guirec takes it a step further, pointing out a rarely discussed metric: water usage. Scaleway is looking at water usage effectiveness as well, with a view toward responsible innovation that doesn’t overlook environmental cost.
What’s perhaps most fascinating is how Scaleway sees the future of AI training workloads. Today’s language models may be grounded in web-scale text, but tomorrow’s models — multimodal, agentic and domain-specific — will need exponentially more data across formats, such as images, audio and video. That means even more demand on both GPU throughput and the bandwidth feeding those GPUs. Scaleway is building toward this future now, with GPU pod systems capable of pushing hundreds of gigabits per second and storage systems built to scale with that need.
While big names in AI infrastructure often dominate the narrative, conversations like this remind us that serious innovation is happening beyond the usual suspects.
So, what’s the TechArena take? Scaleway isn’t trying to be everything to everyone – but for teams building sophisticated AI pipelines, in Europe and beyond, it’s quickly becoming a name to watch.
To dive deeper, visit scaleway.com.

Google's Antitrust Reckoning: U.S. and India Take Action
Reading the antitrust news about Google this past week gave me a keen sense of déjà vu as I thought back to my years at Intel and what it was like to witness its historic regulatory battles from the perspective of an employee (more on that in a moment).
During a week packed with regulatory friction, Google faces serious domestic and international challenges with legal actions that promise to shake the foundations of its business model. In the U.S., the Department of Justice (DOJ) is now in the remedies phase of its antitrust case against Google. The court already ruled that Google violated antitrust laws by using multi-billion-dollar contracts to entrench its search engine dominance. Those exclusive deals — like the reported $20 billion agreement with Apple — are now in the crosshairs of regulators. The DOJ’s proposed remedies could go as far as banning those contracts altogether or even forcing a Chrome browser divestiture.
In a separate case, a U.S. District Court found Google’s advertising business to be an illegal monopoly — one that actively suppressed competition and harmed publishers through a tightly controlled ad stack. The DOJ is pushing for a breakup here too, potentially including the sale of Google Ad Manager.
Outside the U.S., Google has just settled a longstanding case with India’s Competition Commission regarding its Android TV practices. The settlement, which includes a $2.38 million payment, will loosen Google’s grip on device manufacturers, allowing more freedom to choose non-Google apps and services. While this is a rounding error on Google’s balance sheet, it reflects growing global interest in holding the company accountable to anti-competitive measures.
Déjà Vu: Intel’s Antitrust Era
For those of us who have been in tech long enough to remember, Google’s situation feels eerily familiar. Let’s face it. The tech industry is ripe with antitrust challenges, and recent history has filled the headlines with companies including Apple, Amazon, Meta, Microsoft, NVIDIA, and Qualcomm facing legal challenges regarding anti-competitive practices.
During my tenure at Intel, I had a front-row seat to what it means to operate under a regulatory microscope. Intel was repeatedly investigated — and fined — for allegedly using its x86 CPU market position to suppress competition, particularly from AMD. The landmark 2009 European Commission decision fined Intel €1.06 billion (then $1.45 billion), claiming that the company gave rebates to PC makers and retailers in exchange for exclusivity, effectively locking out AMD. Though Intel spent over a decade appealing the ruling, the reputational and strategic impact was immediate and lasting. The FTC also launched its own suit, which Intel settled in 2010 by agreeing to a slew of business practice changes.
Those years were...educational. Internally, every marketing strategy and partner engagement had to be re-evaluated under the lens of compliance. Creativity and flexibility in the market were absolutely curtailed, and while the business remained strong, the regulatory pressure opened the door for new competitors and architectural shifts — including the rise of Arm and resurgence of AMD. And that’s what these restrictions are supposed to do – open the door to competition that benefits the broader market and customers.
Now, Google is facing a similar inflection point. What’s at stake isn’t just its business practices — it’s the foundational structure of its revenue model, particularly in advertising and browser dominance. If remedies go as far as DOJ proposals suggest, Google could be forced to rewrite the rulebook on how it competes, once again opening the door to new competitors in the market.
The TechArena Take
At TechArena, we’re watching this moment closely — because it’s not just about Google. It’s about how innovation and market power intersect, and how regulatory pressure can unlock or stifle competition. If history is any indication, the companies that come out on top in these moments aren’t the ones who just fight the legal battle — they’re the ones drive disruptive change into one player dominant markets at time of regulatory pressure. We celebrate open competition and standards-based tech stack innovation, and we’re excited to see how this regulatory pressure cooker will foment in new opportunity for the market and customer engagement.

GIGABYTE and Solidigm Unveil Advanced AI and HPC Solutions
At the NVIDIA GTC conference, where the latest advancements in AI and high-performance computing (HPC) are on display, Scott Shadley, director of leadership narrative and evangelist of Solidigm, sat down with Carrie Wang, sales marketing at Giga Computing, and TechArena, to discuss the rapidly evolving landscape of enterprise technology and AI infrastructure. Our conversation shed light on the critical role data centers and efficient computing play in addressing the growing demand for AI-driven workloads.
Giga Computing is making significant strides in the AI and HPC arenas. Carrie spoke about the company’s journey, noting how GIGABYTE’s server business began with a small team back in 2000, ultimately evolving into a leader in the AI infrastructure sector. Today, Giga Computing, a wholly owned subsidiary of GIGABYTE, is shaping the future of high-performance AI, cloud and HPC solutions for businesses worldwide.
As AI adoption surges across industries, the need for power-efficient and scalable infrastructure has never been more critical. Carrie highlighted that AI inferencing, the process of applying trained models to real-world data, is becoming more power efficient, but the growing demands of AI workloads mean that data-intensive processes are increasingly requiring better storage, networking and compute solutions.
One of the standout solutions Giga Computing is showcasing this year is the GIGABYTE G893 GPU server platform. With support for NVIDIA HGX™B200 and NVIDIA HGX™ B300 NVL16, this platform is specifically designed to handle the most demanding AI and HPC workloads. Paired with NVIDIA BlueField®-3SuperNICs, the G893 delivers outstanding performance while minimizing energy consumption – a key concern as data centers grapple with rising power demands. Additionally, Giga Computing’s innovative cooling solutions, including the GIGABYTEG4L3 platform, ensure that these powerful systems run efficiently even under heavy loads. At the conference, Giga Computing presented a comprehensive solution for data centers, featuring a direct liquid cooling (DLC) rack system that combines multiple racks for a fully integrated solution.
The conversation also touched on how Giga Computing is addressing the challenges faced by the industry. With AI workloads continuing to surge, the demand for power-hungry data centers is driving up rental rates, with increases of up to 6.5% compared to the first half of 2023. In this environment, businesses must carefully select the right components to maximize performance while keeping power consumption in check. It’s a delicate balancing act, and Giga Computing’s solutions are designed to help customers optimize their infrastructure to address these challenges.
Another topic discussed was the rise of agentic AI — systems capable of making decisions autonomously based on real-time data. Carrie emphasized that agentic AI relies heavily on inferencing, and Solidigm’s NVMe solid state drives (SSDs) play a critical role in supporting these models. With Solidigm’s cutting-edge storage solutions, customers can efficiently handle large-scale datasets in their data centers, minimizing delays and ensuring low costs and power consumption.
So, what’s the TechArena take? As AI, HPC, and cloud workloads continue to evolve, it’s clear that collaboration between companies like Solidigm and Giga Computing is key to driving the next wave of innovation. By working together to deliver integrated solutions that prioritize performance, power efficiency, and scalability, these companies are setting the stage for the future of AI infrastructure.
Watch the full video here.
For those looking to learn more about Giga Computing and their groundbreaking solutions, you can visit their website, gigabyte.com/Enterprise, or follow them on LinkedIn and Twitter to keep up to date on their latest offerings and innovations.

AI, Storage & the NYSE: Behind the World's Fastest Markets
Solidigm's Roger Corell chats with ICE's Anand Pradhan to explore how AI, storage, and system design fuel 700B+ daily trades — and what AI inference means for the future of storage at scale.

Torc’s Autonomous Trucking Platform: Powering the Future of Freight
The future of trucking is autonomous – and Flex is helping enable it by building the brains behind the big rigs.
At NVIDIA’s GTC 2025, Torc Robotics unveiled its latest advancement in autonomous trucking: a scalable physical AI compute system developed in collaboration with Flex and NVIDIA. The platform is designed to enable self-driving trucks to perceive and navigate their environment in real-time, utilizing sensors like lidar, radar, and cameras.
Flex plays a pivotal role in this collaboration by providing the Jupiter compute platform and advanced manufacturing capabilities. The Jupiter platform integrates NVIDIA’s DRIVE AGX with the DRIVE Orin system-on-a-chip and DriveOS operating system, delivering the high compute performance and low latency required for Torc’s autonomous trucking software. Each Jupiter unit has 2 SoCs, for a total of 8 SoCs in the four-unit version Torc is deploying.
This partnership ensures that Torc’s autonomous trucks meet stringent requirements for size, performance, cost, and reliability, aligning with fleet customers' total cost of ownership targets. The platform's adaptability allows it to accommodate varying operational conditions, including new routes, hardware configurations, and road environments.
Torc plans to commercially launch this autonomous trucking platform in 2027, marking a significant step toward scalable production and deployment of self-driving long-haul trucks.
Flex Wins Automotive PACE Award
In a testament to its pioneering efforts in autonomous vehicle technology, Flex was recognized with a two-time 2025 Automotive News PACE Award – honored for its industry-leading Jupiter Compute Platform and Backup DC/DC Converter design platforms. The PACE Awards recognize automotive suppliers for superior innovation, technological advancement, and business performance. The innovation awards demonstrate Flex’s leadership in compute and power electronics product design for next-gen mobility.
The Broader Impact of Autonomous Trucking
The introduction of autonomous trucks promises to bring transformative changes to the freight industry:
Cost Reduction: Autonomous trucks are projected to reduce shipping costs by 25-30%, primarily by eliminating driver wages, which constitute a significant portion of operational expenses.
Increased Efficiency: These vehicles can operate nearly 24/7 without the need for rest breaks, potentially cutting shipping times by 25-35% and enhancing supply chain efficiency.
Enhanced Safety: By removing human error factors such as fatigue and distraction, autonomous trucks are expected to significantly reduce accident rates, leading to lower insurance costs and improved road safety.
Environmental Benefits: Continuous operation and optimized driving patterns contribute to better fuel efficiency, reducing emissions and supporting sustainability goals.
The impact of autonomous trucking on employment, particularly for long-haul drivers, is a topic of significant discussion and analysis. A study commissioned by the U.S. Department of Transportation suggests that with slow to medium adoption of autonomous trucking technology, the industry could avoid mass layoffs. High turnover rates in long-haul trucking—often exceeding 90% annually—indicated that reductions in employment could be managed through natural attrition rather than forced layoffs.
In a model where adoption of autonomous trucking moves faster, USDOT study predicts a potential loss of up to 11,000 long-haul trucking jobs over five years, representing about 1.7% of the workforce. It's important to note that while automation may reduce certain driving jobs, it could also create new roles in vehicle maintenance, remote operations, and logistics management. The transition's net effect on employment will depend on various factors, including policy decisions, retraining programs, and the pace of technological adoption.
So, what’s the TechArena take? Torc's collaboration with Flex and NVIDIA represents a significant advancement in autonomous trucking technology. By integrating high-performance computing with scalable manufacturing, this partnership is poised to deliver safer, more efficient, and cost-effective freight solutions. As the industry moves toward a future of autonomous logistics, such innovations will be critical in addressing the growing demands of global supply chains.

An Army of Agentic EEs Unleashed by Synopsys
Last month, I had the pleasure of attending Synopsys’ first Executive Forum in Santa Clara. For those who don’t follow Synopsys, the firm has a multi-decade history of providing foundational technology to the semiconductor industry, and they have not missed a beat under CEO Sassine Ghazi’s leadership. And while I knew that the leadership team would be sharing the latest innovations that would help fuel the next generation of processors, what Synopsys put together was stunning in terms of its long-term implications to semiconductor design.
Taking a step back, a processor has historically maintained a five-to-seven-year development cycle from vision to production, and over time market pressures have shrunk this development cycle significantly. According to Jensen Huang, who was running his own conference across town as the Synopsys event unfolded, we have now entered a realm of hyper-Moore’s law advancements with silicon design cycles within a one-year window. Unheard of, aggressive, and seamlessly impossible with yesterday’s tools.
The first advancement to address this challenge has been the introduction of chiplet architectures and the movement of different IP blocks, sometimes manufactured with different process technologies, connected together to form complex and scalable systems. This allows for re-design of chiplets across a portfolio of products or even across a portfolio of vendors for design elements that are not critical to differentiated solution delivery. Synopsys itself operates in this space, delivering IP and multi-die integration solutions to the semiconductor ecosystem. We’ve seen the industry move in this direction with all major players favoring chiplet architectures, and while we’re still waiting for a vibrant chiplet ecosystem to emerge for open, interoperable designs, we are seeing an uptick in adoption of chiplet designs across the industry delivered to bespoke customers.
But what Sassine and his team envisioned next rips the doors off of semiconductor design to the point of considering that this is a next era of advancement: agentic AI controlled design. Imagine deploying millions of AI agents that a semiconductor designer can utilize to craft semiconductors. This starts with something Synopsys has already delivered – an AI Copilot that assists a designer in the process of his or her design, trained specifically on an organization’s technology and sitting aside other Synopsys tools and IP. This is a great advancement and a good use of LLM training for a pressured workforce. But…it’s only an amuse bouche of what is to come.

We are on the precipice of what Sassine called level 2 implementation of a journey taking us from copilot to auto-pilot design. Synopsys will be delivering agentic capability in their portfolio later this year to offload design of specific functions to agents, with human controlled integration of this design into larger workflows. Synopsys sees a reality where a portion of design is delivered through chiplet and IP blocks, a portion is delivered by agents, and actual engineers focus on the most challenging elements of execution, speeding design significantly.
This will be followed by level 3 delivery, where multi-agent models will include specialists orchestrated together for more complex work, followed by the integration of adaptive learning improving designs as they progress, and finally level 5 full autonomy delivery with agents empowered with decision making. Yes…in level 5, agents in theory can design and validate microprocessors autonomously.
This is stunning. It’s stunning for the acceleration of compute, given that we can also advance process technology and continue delivery of performance improvements, but it’s stunning for another reason. Microprocessors are the most complex inventions on the planet, and Synopsys’ vision includes processors of a trillion transistors, reaching new levels of design complexity. If AI agents can deliver this complex of problem solving, we need to ask what they will be incapable of doing.
While we do not have an acute time horizon for this advancement, one thing is clear. Just like the accelerated microprocessor design windows, the speed in which generative AI and agentic computing has been advancing makes this reality much closer than we’d historically predict. And while this story feels a lot like the backstory of Skynet, in the near term there is no escaping that AI agent assist will help Jensen and his team at NVIDIA, and the entire silicon ecosystem, accelerate design to meet the insatiable customer demand represented by AI. AI…creating AI.

MicroCloud + AMD EPYC™ 4004 = High-Density Win for CSPs
Supermicro’s new MicroCloud platform, powered by AMD EPYC™ 4004 CPUs, delivers higher core density, network flexibility, and TCO advantages for cloud service providers at scale.

ASBIS Tackles Regional IT Challenges with Smart Solutions
At the forefront of IT infrastructure advancements, ASBIS has been making significant strides in providing high-performance solutions, particularly in the transition from traditional hard drives to solid-state drives (SSDs). This shift, driven by the growing demand for speed, reliability and energy efficiency, has seen ASBIS collaborate closely with Solidigm, a leader in the SSD industry, to deliver cutting-edge storage solutions. Eduards Lazdins, business development manager at ASBIS, shared insights into the company’s approach during a recent discussion with Steve Gutierrez, director of sales at Solidigm, and TechArena
ASBIS, a value-added distributor and solution provider, has an expansive footprint that spans 28 countries, with over 20,000 active customers across 60 nations. Its reach is impressive, but it’s the company’s ability to address the unique needs of diverse markets that really stands out.
ABSIS serves a mix of established and emerging markets facing an array of opportunities and challenges for IT infrastructure development. While Western Europe leads in cloud adoption and AI-driven workloads, regions like Central and Eastern Europe, the Caucasus and parts of the Middle East and Africa are catching up rapidly. The challenge is striking the right balance between affordability and performance. This is where ASBIS excels — by offering high-performance solutions at scalable price points, making cutting-edge technology accessible to a wide range of customers.
ASBIS’ approach to staying ahead in the competitive IT landscape involves constantly expanding its product portfolio and geographical reach. The company is not just a traditional distributor — it operates its own server assembly line in the European Union, with the capacity to produce thousands of servers per month. This vertical integration, combined with strong partnerships with leading brands, such as Solidigm, enables ASBIS to deliver tailored solutions that meet the specific needs of its diverse customer base.
A key focus of ASBIS’ strategy has been the transition to SSDs, and it has leveraged its collaboration with Solidigm to accelerate this shift. SSDs provide significant advantages over traditional hard drives, such as faster speeds, improved reliability and lower power consumption. As businesses increasingly turn to SSDs for their storage needs, ASBIS is helping customers adopt this next-generation technology with specialized services, including pre-sales consultancy, robotic solutions, technical support and custom solutions.
One example of ASBIS’ impact is its work with cloud service providers and data centers. By integrating Solidigm’s SSDs into their infrastructure, ASBIS has helped optimize storage solutions, significantly reducing latency and improving workload efficiency. For industries handling vast amounts of data, these improvements in speed and reliability are essential. ASBIS’ solutions have not only enhanced performance, but also minimized power consumption, a critical factor for organizations aiming to reduce operational costs and carbon footprints.
What’s the TechArena take? In a world where technology is rapidly advancing, ASBIS’ commitment to providing innovative, high-performance solutions is a prime example of how the right partnerships and a focus on customer needs can drive real-world results. Looking ahead, ASBIS is well-positioned to continue leading the charge in IT infrastructure solutions, offering both the expertise and technology to meet the evolving needs of its customers.
To learn more about their product offers and solutions, visit ASBIS.com, or follow them on LinkedIn and X for the latest updates.

Supermicro Powers AI Innovation at CloudFest 2025
At CloudFest 2025, Supermicro showcased their innovations that are driving the future of AI, cloud infrastructure and storage solutions. As AI technology continues to evolve, Supermicro’s ability to deliver cutting-edge hardware solutions has become a game-changer, and their booth at CloudFest served as a testament to that progress. Solidigm’s Hayley Corell spoke with Thomas Jorgensen, senior director in the Technology Enabling Group at Supermicro,to dive deeper into how Supermicro is powering AI advancements and meeting the growing demands of modern infrastructure.
Thomas highlighted the rapid growth in AI, noting that the demand for powerful AI infrastructure is being driven by large-scale model training and, increasingly, AI inferencing. But what's crucial for this advancement? A center element of that answer is storage. Supermicro understands that AI models require fast, reliable storage to keep GPUs from idling, ensuring that the entire infrastructure is working in concert to deliver results as quickly as possible. As Thomas bluntly put it, “AI doesn't work without storage,” and Supermicro is delivering solutions to meet this growing demand.
Over the past few years, AI’s exponential growth has shifted the way companies are approaching infrastructure. As Supermicro and the rest of the industry ride the wave from training centric infrastructure demand to a demand curve that also reflects inference, new kinds of infrastructure for a wider range of environments is required. As AI continues to be specifically integrated into edge environments, Supermicro is positioning itself at the forefront, enabling AI at the edge with small, fanless servers that process inferencing directly where data is generated. This localized approach reduces latency, and it also improves the speed at which data is processed, ensuring AI workloads perform seamlessly.
A key part of Supermicro’s success lies in its commitment to delivering high-performance, low-latency infrastructure. Thomas discussed how AI clusters require not only powerful GPUs, but also fast network communication and efficient storage systems. The infrastructure design has evolved significantly to meet the demands of AI, particularly with the rise of high-density petascale storage solutions. Supermicro’s focus on providing multi-tiered storage setups ensures that data is delivered at optimal speeds for any given AI workload, enabling seamless performance across AI applications.
The collaboration between Solidigm and Supermicro has been crucial in driving these advancements, particularly in the realm of high-speed storage. Solidigm’s cutting-edge storage solutions, such as their high-capacity SSDs, perfectly complement Supermicro’s AI infrastructure. By combining Solidigm’s innovative storage technology with Supermicro’s powerful hardware, they deliver the performance and reliability required to handle the intense data demands of AI workloads.
This collaboration helps ensure that AI models can access and process data quickly, making it an essential part of AI-driven infrastructure.
Supermicro's petascale storage is capable of integrating up to 122 terabyte SSDs. This massive capacity allows AI workloads to scale up and manage vast amounts of data with ease.
So, what’s the TechArena take? For on-prem AI deployments, tapping large volumes of data locally for AI integration across business functions is becoming increasingly critical, especially as many businesses shift away from the cloud due to rising costs and data privacy concerns. Supermicro’s petascale storage delivers the speed and bandwidth needed to support the growing demands of AI models, ensuring that organizations can keep up with both the scale and complexity of modern AI workloads right from their own data centers. Solidigm’s leading 122 TB drives are a perfect match for these large scale deployments.
For those looking to learn more, Supermicro offers an abundance of resources on their website (supermicro.com) and social media channels (X, LinkedIn and YouTube).
Tech Innovations Help Consumers Say Goodbye to EV Range Anxiety
Financial incentives and future legislation are pushing EV adoption, but advanced power electronics and battery technologies are crucial to addressing range anxiety and driving broader acceptance.Range anxiety, the feeling of concern over the distance an electric vehicle (EV) can travel on a charge, is typically cited as the primary reason that EVs continue to see modest adoption. While both the carrot, in the form of financial incentives, and the stick, in the form of future legislation banning internal combustion engine (ICE) vehicles from entering major cities, are being employed to incentivize consumer adoption of EVs, extending the range of EVs is one of the most important factors to address to drive broader adoption.
One theme that I have highlighted in every blog to date is that the automobile has significantly transformed from the historical adoption of trailing-edge electronic technologies. Today’s vehicles and those on the drawing table (or maybe now it’s in the CAD tool) push the boundaries of employing state-of-the art technologies. Power electronics, specifically those used to power the electric motors of the EV and the associated control electronics and architectures, are no exception.
In this blog, I’ll provide a very high-level overview of some of the advanced technologies and architectures associated with powering the EV drive train and where these are being pushed to further extend the range of EVs. Each of these topics could easily warrant its own blog. Suffice to say, this will be a light treatment of these topics.
A very simplified block diagram of the powertrain of an EV is shown below.

While this block diagram hardly does justice to the complexity of the EV powertrain, it provides an adequate framework to highlight some of the major building blocks and the key technologies that are employed in the EV powertrain, the impact they have on the range of the EV, and the innovations that we can expect to see on the horizon to further extend that range.
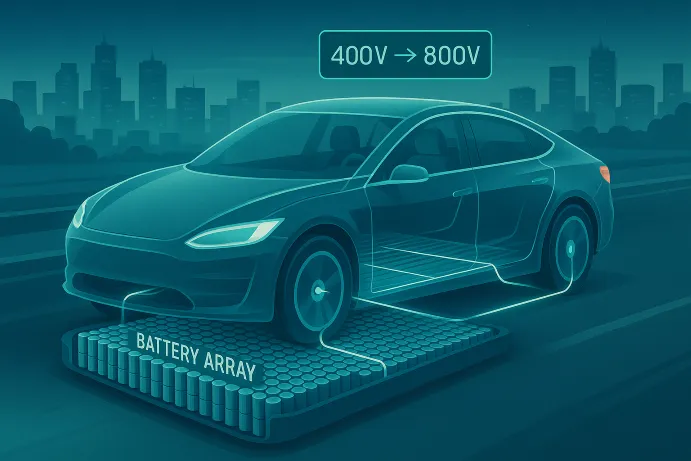
Starting with the battery pack, a typical EV on the market today consists of a total of 7,104 rechargeable 3-volt lithium-ion batteries — each roughly the size of an AA battery! These batteries are connected in series and parallel combinations to generate about 400 direct current (DC) volts (at 90 kilowatt-hours), which is used as the power source for the traction inverter. 90 kWh means that the battery pack can supply 90 kW of power for 1 hour, which is a lot of power! The average US household uses roughly 30 kWh of power in a day.
To further improve power efficiency in the future, the industry trend is for the battery pack voltage to move from 400V to 800V. That shift will lead to significant benefits in actual power consumption (reduced by a factor of 2!), which in turn leads to less heat and hence less weight required to address system-level cooling and less weight due to lighter cabling requirements. The move to 800V does, however, require the charging infrastructure and the traction inverter to support these higher voltages.
The traction inverter is responsible for supplying power to the brushless DC motors, as controlled by the accelerator. Historically traction inverters employed relatively mature power semiconductors called IGBT (insulated gate bipolar transistors). Semiconductors are typically challenged to operate at such high power and voltages, especially if high speed switching is required. While IGBTs can address the high-power demands, they offer relatively low switching performance and are not practical in the most efficient traction inverters, which are typically based on switched topologies.
Recent advances in manufacturing processes have made a relatively new class of power electronics, wide bandgap semiconductors, viable for volume production applications. Wide bandgap semiconductors can operate at very high voltage levels, power levels, and at high switching frequencies with very low resistance (no energy lost in the device). There are two different types of wide bandgap technologies — one based on silicon carbide (SiC) and another on gallium nitride (GaN). SiC can operate at higher power levels but at slightly lower switching frequencies compared to GaN, which supports higher switching frequencies at lower power levels. Both technologies offer significant improvements over the traditional IGBT devices.
Wide bandgap devices are one of the fastest growing segments in the power electronics market, driven by EVs, the EV charging infrastructure, renewable energy, and a host of other applications requiring high-power, high-efficiency semiconductors. They demonstrate how automotive now drives demand for leading-edge technologies. The ability to operate at 400V and then support the shift to 800V is only made practical through the advent and use of wide bandgap semiconductors.
The traction inverter also employs some of the industry’s leading-edge motor control techniques, which include space vector modulation (SVM) and field-oriented control (FOC) to deliver maximum inverter performance, efficiency and control over the state-of-the-art brushless DC motors. The switching circuitry topologies employed in the traction inverter also represent some of the most advanced topologies, which again focus on achieving the highest energy efficiency when driving the EV motor. With the objective to address range anxiety, there is no stone left unturned in employing innovative technologies whenever it is applicable, viable and beneficial.
The last building block in the discussion of the EV power train is that of the battery management system (BMS). The BMS also profoundly affects the range of the vehicle. As previously mentioned, the battery pack of an EV is based on thousands of rechargeable batteries that are connected in various series and parallel combinations to generate 400 volts. One of the key challenges that the BMS addresses is that each of those batteries has a different charge and discharge rate, and those rates need to be monitored and controlled to ensure batteries are not under-charged or overcharged. Under-charging will directly affect range (not a full charge), whereas overcharging can lead to catastrophic results, including fires and explosions.
The BMS uses advanced charging algorithms to ensure the maximal charge is achieved on a battery-by-battery basis, while optimizing for minimal time to achieve full charge, and without overcharging a battery or overheating the battery pack. Again, this is a non-trivial problem to solve that also leverages state-of-the art technologies, including wireless connectivity to communicate charge status to electronic control units (ECUs) that monitor the overall charging of the battery pack. Not only are advanced charging algorithms employed, but also AI is employed for preventative maintenance, flagging when a battery or battery pack is starting to fail. Over the air (OTA) update technology is also employed as new, more advanced algorithms are identified that lead to more effective charging or faster charging times.
Lastly, while not shown in the simplified block diagram, there are also significant considerations given to the vehicle architecture as it applies to the distribution of power. Similar to changes in automotive E/E architecture supporting advanced driver assistance and in-vehicle infotainment systems, trends are occurring in the power architecture of the EV in the interest of power efficiency and robustness. In a nutshell, the industry is moving from a functional architecture — where power is delivered over long cables from the power source to the EV motor, to an architecture that is based on spatial positioning, where the shortest reach can be achieved from the traction inverter to the EV motor. Each approach has its benefits and complications, but given the importance of range anxiety, expect the spatial positioning architecture to win out.
In summary, while 50 years ago the average vehicle used few electronics, just a quick look at the EV power train demonstrates the complexity of the technologies that are being employed today, and where this application area is headed. In the past, computers were considered the driver of electronics technologies, then it was computer networking, and then cellular technologies/smart phones. Today, the electronics industry acknowledges that automotive is now driving leading-edge technologies across many fronts. We live in amazing times.

Powering Agentic AI at Scale
From eight-way GPU racks to liquid cooling breakthroughs, Giga Computing and Solidigm explore what it takes to support AI, HPC, and cloud workloads in a power-constrained world.

Simplify Data Infrastructure at Any Scale with VergeIO
1. What are some of the key challenges your customers face related to generating, storing, and processing high volumes of data?
Our customers, particularly those in data-intensive sectors like telecommunications, financial services, education, and healthcare, encounter several significant challenges when managing large volumes of data. These include:
- Escalating storage costs as data volumes continuously grow
- Performance bottlenecks due to aging infrastructure and increasing capacity and performance demands from workloads.
- Complex scalability issues, where scaling resources efficiently becomes difficult.
- Maintaining legacy infrastructure that wasn't designed for today's data-intensive workloads.
- Extending hardware lifespans to avoid costly and premature hardware refreshes.
Additionally, they must consistently ensure uptime, data resilience, regulatory compliance, and energy efficiency amid growing data demands.
2. How does VergeIO help customers overcome these challenges with its products and services?
VergeIO provides a comprehensive solution through our software-defined platform, VergeOS, which seamlessly integrates virtualization, storage, and networking into a single, efficient operating system. The key advantages include:
- Built-in data optimization: Advanced deduplication and live VM tiering.
- Unified infrastructure management: Simplifying operations across virtualization, storage, and networking.
- Significantly reduced hardware footprint and operational complexity.
- Seamless scalability: Easily scale performance from dozens to hundreds of nodes without complexity.
- Elimination of vendor lock-in and hardware-refresh dependency, maximizing ROI and flexibility
3. How has the shift to high-density SSDs enhanced VergeIO’s ability to manage massive-scale virtual environments, especially in data-intensive sectors like telecommunications and financial services?
The adoption of high-density SSDs has greatly amplified the effectiveness of VergeOS. When paired with our high-performance distributed file system, these ultra-dense flash storage technologies enable:
- Unmatched VM density, dramatically increasing infrastructure efficiency.
- Per-node storage capacities approaching 3PB within compact 2U servers.
- Exceptional IOPS and throughput, vital for performance-sensitive environments.
- Reduced infrastructure footprint, cutting rack space, power consumption, and cooling costs.
- Improved scalability and reliability, essential for critical sectors like telecom and financial services.
This powerful combination ensures exceptional performance, efficiency, and cost-effectiveness for data-intensive, mission-critical workloads.
4. How does VergeOS contribute to energy efficiency and extend hardware lifespan?
VergeOS is purpose-built to optimize efficiency throughout your infrastructure lifecycle:
- Lightweight, resource-efficient architecture reduces CPU and memory overhead.
- Higher VM density allows more workloads to run effectively on fewer physical servers.
- Lower overall energy consumption, significantly reducing power and cooling expenses.
- Intelligent resource optimization, such as workload balancing and live VM tiering, maximizes hardware utilization.
- Extended hardware lifecycle, reducing the frequency and cost associated with hardware refreshes.
The result is a sustainable, cost-effective infrastructure designed for long-term growth and efficiency.
5. What new possibilities do VergeOS and advanced storage technologies unlock for your customers in terms of real-time virtualization, streamlined data management, and scalable infrastructure?
Together, VergeOS and next-generation storage solutions offer unprecedented infrastructure agility, enabling organizations to:
- Accelerate real-time virtualization with instantaneous VM spin-up, cloning, and replication.
- Simplify data management through a unified control plane covering virtualization, storage, and networking.
- Effortlessly scale infrastructure with Virtual Data Centers (VDCs) that provide secure, isolated multi-tenant environments.
- Enhance disaster recovery and automation with built-in capabilities for automated backup, fast recovery, and comprehensive observability.
- Ensure future-proof growth, enabling dynamic scalability without complexity or disruptions.
Specifically, VergeIO's Virtual Data Center (VDC) technology creates completely isolated, software-defined data centers within a single infrastructure, each with independent compute, storage, and networking resources. This isolation enables customers to:
- Rapidly provision secure, dedicated environments for tenants, departments, or projects.
- Implement granular resource allocation and control, ensuring efficient use of infrastructure.
- Automate and streamline disaster recovery processes through easy replication of entire VDCs.
- Achieve higher resource utilization, reducing operational costs and infrastructure overhead.
By leveraging this unified, software-defined approach, our customers achieve greater productivity, resilience, and innovation—all while simplifying operations and reducing costs.

How Scaleway Is Scaling AI Sustainably in Europe
Scaleway’s Yann-Guirec Manac'h shares how the company is simplifying complex AI pipelines, maximizing SSD performance, and driving sustainable innovation in European cloud infrastructure.

How Ocient Tackles Big Data Challenges
1. What are some of the key challenges your customers face related to generating, storing and processing high volumes of data?
- Cost and Unpredictable Spending: The cost associated with traditional data warehousing solutions, especially in cloud environments, has become unpredictable and is leading to budgets spiraling out of control.
- Data Movement: Moving data between disparate systems is inefficient, introduces vulnerabilities, security risks, and increases operational complexity.
- Increased Energy Consumption: Running compute-intensive workloads on legacy hardware and software architectures leads to excessive energy consumption and a large environmental footprint. This restricts an organization’s ability to innovate sustainably and impacts the overall operational burden associated with large, complex data workloads.
- Data Preparation: Preparing data for AI and machine learning is a time-consuming and resource-intensive process, with a lot of that complexity having to do with data pipeline.
- Operational Burden: Maintaining and managing complex data environments and pipelines poses a significant operational burden on enterprise teams who may already be constrained for time and resources.
- Data Sprawl: Enterprises with data spread across many different systems struggle with inefficient data ecosystems and sprawl.
2. How are you helping to address these challenges with the products and services you provide?
- Unified Data Platform: Ocient’s data platform consolidates various analytics capabilities into a single, efficient system, built for sustainable data performance with compute-intensive workloads.
- Compute-Adjacent Storage Architecture (CASA): Ocient's innovative architecture brings compute directly to the storage layer, minimizing data movement and maximizing processing efficiency.
- SSD-Based Infrastructure: With hardware partners like Solidigm, Ocient leverages an all-NVMe SSD architecture for high performance and efficiency.
- In-Database Machine Learning (OcientML): Ocient’s in-database machine learning capabilities enabling customers to train and deploy models directly on their data.
- Customer Solutions and Workload Services: Ocient offers comprehensive customer support, including pre-purchase workload analysis and post-purchase optimization, ensuring successful deployments and sustained customer success.
- Built for Efficiency: Ocient enables organizations to reduce the total cost of ownership, operational burden, and environmental footprint of their analytics and AI use cases.
- Streamlined & Consolidated Analytics Stack: Ocient helps organizations consolidate and streamline their analytics stack, eliminating the need for disparate ETL, real-time streaming, and orchestration solutions in many implementations.
3. How has the shift to high-density SSDs impacted your ability to handle massive-scale workloads, particularly in industries like telecommunications, geospatial analytics, and financial services?
- High-density SSDs, like those delivered by Solidigm, are foundational to Ocient's architecture and our CASA-based approach to large, complex, costly data workloads.
- With an architecture underpinned by SSDs, Ocient is able to deliver extremely fast data access and processing, which is essential for the following industry verticals:
- Telcos (e.g. data retention and disclosure; internet connected records),
- AdTechs (e.g. real-time bidding and reporting)
- Public Sector organizations (e.g. geospatial analytics; network operations and security, search and analysis)
- The speed and efficiency of SSDs enable Ocient to deliver real-time analytics and data processing capabilities that would be nearly impossible with traditional hard disk drives.
4. Can you elaborate on the role of high-capacity SSDs in enabling energy efficiency and sustainability within your data centers?
- With hardware-aware software and innovations delivered via Ocient’s Hyperscale Data Warehouse, Ocient can reduce the cost, energy, and system footprint for data and AI workloads by up to 90%
- Using SSDs with massively better IOPS than HDDs means that you can use fewer drives to handle real-time data and therefore cut the carbon footprint.
5. What opportunities do these advanced storage solutions unlock for your clients in terms of real-time analytics, data accessibility, and scalability?
- Cost Reduction: Cost efficiencies delivered via the hardware and software layer translate to an overall efficient system capable of delivering powerful data performance at a significant cost reduction.
- Scalability: Ocient's platform is designed for sustainable growth and data performance, which allows customers to handle massive-scale workloads while also being future-proof for future workloads.
- Faster Machine Learning: The ability to run machine learning directly on the data within Ocient's platform accelerates the deployment of AI models.
- Reduced Complexity: Consolidating data environments and simplifying data pipelines reduces operational complexity and frees up resources for innovation.

Arm Weighs in on AI’s Evolution
At GTC 2025, Arm’s Chloe Ma explains how AI is shifting from compute to full-system optimization — and why storage, inference, and the edge are becoming central to tomorrow’s intelligent infrastructure.

Unpacking the Power of Alluxio: A Game-Changer in AI Infrastructure
With NVIDIA CEO Jensen Huang’s headline-grabbing reference to GTC as the “Super Bowl of AI,” expectations for this year’s conference were sky-high — and key players delivered. Among the standout innovations was Alluxio’s contribution to transforming how data is managed and accelerated in AI workloads. Scott Shadley, Director of Leadership Narrative and Evangelist at Solidigm, joined Bin Fan, Founding Engineer and VP of Technology of Alluxio, to discuss how their team has been pushing the envelope in AI data acceleration and efficient storage management, and quickly establishing a tangible impact on how AI models are trained and deployed across industries.
At the heart of Alluxio’s innovation is its ability to decouple storage and compute. Traditionally, data storage has been tightly coupled with compute resources, limiting the scalability and speed of AI workloads. But with Alluxio’s technology, data scientists and AI modelers no longer need to worry about the complexities of storage management. Instead, Alluxio introduces an abstraction layer between applications and storage, making data access seamless and efficient.
One of the most compelling aspects of Alluxio is its ability to accelerate data access. By positioning Alluxio close to GPU applications, the technology significantly reduces the time it takes to access large datasets, especially in geographically dispersed environments. This is particularly important for AI workloads that require massive amounts of data across different regions or clouds. With Alluxio’s caching layer, repeated data access is minimized, ensuring that applications are running at peak performance without the usual latency or overhead.
But Alluxio isn’t just about speeding things up – it also brings simplicity and flexibility to the table. By abstracting storage into a unified structure, their solution enables organizations to seamlessly manage their data across multiple on-prem and cloud deployments without the hassle of manual configuration or inconsistent access. Whether it's scaling up GPUs in one region or shifting workloads to another, Alluxio’s virtualization and abstraction layers provide a seamless experience for both data engineers and end users.
To meet these varied and demanding workloads, Alluxio has partnered with Solidigm to provide reliable, high-capacity storage solutions. While Alluxio serves as the software layer for managing data storage, Solidigm brings its experience as a leading supplier of SSDs to offer the ideal hardware for Alluxio’s caching layer. Together, this collaboration ensures that AI workloads are running on the fastest, most reliable infrastructure possible. The ability to store and retrieve data efficiently is essential in today’s fast-paced AI landscape, and Alluxio’s integration with Solidigm hardware delivers that performance without compromise. (Learn more about data storage optimized for the AI era.)
Alluxio is doing more than just keeping up with the growing demand for AI infrastructure — it’s leading the way in making data management simpler, faster, and more efficient. As AI continues to evolve, technologies like Alluxio will be at the forefront, empowering organizations to harness the full potential of their data.
For anyone curious about diving deeper into Alluxio’s capabilities, the company’s website, alluxio.io, and social media channels, including YouTube, offer a wealth of resources. Watch the full video here.

Scaling Smarter: Peak AIO Tackles AI Bottlenecks at GTC
Peak AIO’s Roger Cummings joins Solidigm’s Scott Shadley at NVIDIA GTC to talk AI infrastructure shifts, single-node innovation, and making data placement as intelligent as the AI it powers.

Beyond Automation: Cloudflare’s Vision for Developer Empowerment
At NVIDIA GTC 2025, Cloudflare shared an exciting vision for the future of AI, automation, and developer tools. During a conversation with Scott Shadley, Director of Leadership Narrative and Evangelist at Solidigm, Aly Cabral, Cloudflare VP of Developer GTM, explained how they are becoming a critical player in the rapidly evolving tech landscape. As industries shift and change, Cloudflare’s focus is clear: empowering developers to navigate these transformations with the right tools and ample support.
One of the main topics of discussion was agentic AI, and how to define the loosely used term that’s been all the rage for next-gen AI predictions. Simply put, agentic AI goes beyond traditional automation by enabling systems to make decisions and manage more complex, dynamic tasks autonomously. While automation improves efficiency, agentic AI adds intelligent oversight, making it easier to both monitor and manage automated systems. Aly emphasized that automation alone isn’t sufficient — it’s about creating systems that are not only efficient, but also transparent and easy to troubleshoot. Cloudflare’s Workflows product addresses this by giving developers visibility into complex systems, helping them quickly identify and resolve issues in multi-step processes. This capability is becoming even more essential as automation plays a larger role in development.
In addition to automation, CodeGen tools are emerging as valuable resources for developers. These AI-powered tools simplify the coding process, allowing developers to generate code faster and with less effort. However, as Aly pointed out, the real challenge lies not in creating applications, but in managing and maintaining them over time. Cloudflare’s platform is built to support developers throughout the entire lifecycle of an application — from creation to long-term management — ensuring that systems remain scalable, secure, and efficient as they evolve.
Looking forward, Cloudflare is doubling down on AI and developer tools. As Aly mentioned, the company is preparing for Developer Week in April, where they’ll unveil new launches and innovations aimed at improving the developer experience. With new features and tools focused on simplifying the development process and harnessing the power of AI, Cloudflare is working to ensure developers have everything they need to create smarter, more scalable applications.
So, what’s the TechArena take? Cloudflare’s approach to partnerships sets them apart. Rather than locking customers into proprietary ecosystems, Cloudflare prides itself on being a connector, offering a globally distributed network and an open ecosystem that integrates well with a wide variety of third-party services – without an aggressive egress tax. This flexibility allows developers to use the best tools for their needs without being restricted to a specific platform. It’s this open approach that makes Cloudflare an ideal partner for companies like Solidigm, who offer unique solutions that complement Cloudflare’s services.
Watch the full video here. Learn more about Solidigm’s data storage solutions for the AI era here.
For those interested in staying connected with Cloudflare’s latest developments, the company maintains an active Discord community, YouTube channel, and X presence, providing ample opportunities for engagement and learning. Or visit their website.

Building Trust with NIST AI Risk Management Framework
NIST, the United States Institute of Standards and Technology, has long been an invaluable resource to product marketers. From data protection to AI, it has provided definitive technical definitions and processes. But if its role evolves, should we examine its guidance more critically?
The importance of NIST for product marketers
One of the jobs of product marketers is to get the team to agree on consistent terminology. We must use language that resonates with our audiences when marketing our product.
For example, if you have a security product (including backup and recovery), then you’ll need an authoritative guide to explain the best way to set up a secure computing environment. NIST offers that guidance. It’s simply good data center hygiene practice.
The NIST Cybersecurity Framework (CSF) has a dedicated website full of non-prescriptive guidance for companies developing and implementing cyber security programs. If you are selling to that market, it makes sense to use the CSF as the arbitrator for definitions and procedures.
I personally used the NIST framework many times, aligning product features to the CSF guidelines. So, I was extremely excited to know that NIST would build the same types of documents for AI environments.
NIST Artificial Intelligence Risk Management Framework
The NIST Artificial Intelligence Risk Management Framework was created to provide “in-depth, voluntary guidance primarily intended for developers and users of AI systems” (techpolicy.press).
The framework provides guidance on setting up governance for AI systems. It explains how to assess risks at every level, emphasizes the importance of documentation, and defines seven characteristics of trustworthy AI.
The U.S. Artificial Intelligence Safety Institute (US AISI) was established in November 2023, as a part of NIST. The Institute’s mission is “tasked with developing the testing, evaluations, and guidelines that will help accelerate trustworthy AI innovation in the United States and around the world.”
Interestingly, there have been new requirements for scientists partnering with U.S. AISI. According to a Wired report, these instructions require the removal of references to “AI safety,” “responsible AI,” and “AI fairness” from the expected skills of members.
But as AI continues to shape our world, it is crucial to ensure that the stories it tells are accurate, fair, and reflective of our diverse societies. NIST's frameworks provide a foundation, but it is up to us to build on it responsibly and require AI safety and fairness from the frameworks we rely on to tell the story of our products and services.
Those who tell the stories rule society
Plato is credited with saying, “those who tell the stories rule society.” If he was right, we must ensure that the stories told by technology are accurate, fair, and inclusive.
At its root, AI simply processes data to tell a story. For example:
• Sequencing genomes
• Detecting hackers before they can encrypt your data
• Finding new cancer treatments
• Animating your great-grandmother’s pictures
There have already been warnings from data scientists and linguists about concerns of AI safety and fairness. In the paper “On the Dangers of Stochastic Parrots: Can Language Models be Too Big” by Emily M. Bender et al, the authors raised concerns about how large language models can negatively affect the environment, diversity, social views, and encode bias.
AI tells the story of our world, based on its training data of course. Responsible AI is how we can be sure the entire world is represented as those stories are told.
Building a future with responsible AI
Product marketers and technical writers rely on frameworks like those from NIST to guide our work and ensure clarity for our audiences. With the rise of AI, the stakes are higher than ever.
By embracing responsible AI practices and using tools like the NIST frameworks, we can shape a future where technology tells the true story of our societies, one that promotes fairness, safety, and innovation.

Verge.io Reimagines IT Infrastructure for AI Demands
I recently had the opportunity to sit down with Jeniece Wnorowski of Solidigm, and George Crump, Chief Marketing Officer at Verge.io, to discuss how Verge.io is taking a fresh approach to IT solutions.
The Verge.io solution is game-changing for enterprises looking to optimize their IT infrastructure. Instead of relying on the traditional method of integrating different components through a GUI (Graphical User Interface), Verge.io has gone a step further by combining all aspects of IT infrastructure—networking, storage, and virtualization—into a single, unified code base. This results in a seamless user experience coupled with a dramatic improvement in performance - all while lowering hardware requirements.
By integrating these components, Verge.io improves efficiency and increases hardware flexibility. George shared that Verge.io supports hardware up to seven years old, making it highly adaptable for organizations with legacy systems. This innovation stems from Verge.io’s founding story — Greg Campbell, Verge.io’s CTO, was initially frustrated by the amount of time he spent managing infrastructure while developing a search engine to compete with Google and Amazon – so he decided to build his own solution. Today, this approach has resulted in a product that runs on less than 300,000 lines of code, ensuring fewer bugs and greater reliability compared to traditional solutions that often operate on millions of lines of code.
The solution also addresses one of the most pressing concerns for IT professionals today—cost predictability. Verge.io’s simple licensing model charges per server rather than by core or capacity. This straightforward pricing model appeals to a wide range of IT professionals. By supporting multi-tenancy, Verge.io makes it easier to manage resources across various clients, delivering efficiency and flexibility in a shared environment.
As AI continues to shape the future of IT infrastructure, Verge.io’s platform is designed to be AI-ready. George highlighted the growing importance of AI in enterprise workloads, particularly as organizations explore the use of private AI models. Verge.io is addressing the challenge by ensuring its platform can easily integrate GPUs for AI workloads.
One of the key factors that sets Verge.io apart from others in the market is its approach to migration. As George pointed out, migration is essential when transitioning to a new infrastructure. He also shared that Verge.io’s approach ensures minimal downtime, enabling businesses to shift their data and settings with greater efficiency. This streamlined migration process is key to Verge.io’s ability to deliver a seamless experience for their customers, no matter the scale.
In addition to seamless migration, Verge.io focuses heavily on reliability through its integrated platform. George pointed out that the system continuously monitors the environment, ensuring operations run smoothly even during network disruptions. For example, he described how Verge.io's platform maintained data integrity during network failures when traditional infrastructure would have struggled to do the same.
For enterprises considering storage solutions, Verge.io is leveraging Solidigm’s storage technology to optimize performance and lifespan. George shared how the platform supports various classes of SSDs, including QLC and TLC drives, and integrates them seamlessly into the infrastructure to meet workload demands. This approach ensures that organizations can optimize performance while managing their storage needs efficiently.
So, what’s the TechArena take? Verge.io’s unified infrastructure solution is reshaping the way organizations manage their IT environments. With a focus on cost predictability, AI-readiness, and seamless migration, Verge.io presents a compelling option for businesses that are looking to simplify their infrastructure and improve efficiency.
Listen to our full discussion here.

VAST Partners with Deloitte to Scale AI for the Enterprise
The AI landscape is evolving rapidly, and Deloitte and VAST Data have joined forces to deliver enterprise class adoption. From business strategies to cutting-edge technologies, this collaboration has the potential to bring transformative value to enterprises worldwide. Why is this one to watch? With Deloitte’s deep history of guiding enterprise IT strategy with clients and VAST’s disruptive architecture fueled by new enterprise inference focused solutions, the duo has the right mix of expertise and innovation to make a splash.
In a recent conversation with TechArena, Rick Scurfield, Chief Revenue Officer of VAST Data, and Stephen Brown, AI and Data Managing Director of Deloitte, discussed this collaboration and its impact on the next wave of AI growth. With 2025 and 2026 projected as the "years of scaling enterprise AI," they customers moving past the early phase of AI that has been centered around experimentation, proofs of concept, and business cases to transition to scaling.
This will require robust, secure, and efficient AI infrastructure, leading to the integration of data-driven business value and AI-powered outcomes. The goal is not just to deploy AI in isolated systems, but to ensure that AI can drive business value across multiple functions in the enterprise. As the two leaders explained, AI’s potential is truly realized when it operates across the business as a whole—transforming processes, improving decision-making, and, ultimately, creating new avenues for growth.
Central to this transformation is the integration of data security, risk management, and auditability. As Stephen pointed out, AI applications process enormous amounts of data from both internal and external sources. This data needs to be secured, monitored, and easily auditable at every stage. VAST excels at providing a solution that ensures data integrity, security, and full transparency to the operator. In an era where data breaches and compliance are top concerns for every organization, this ability to deliver a secure and auditable environment is invaluable.
While the collaboration around security is alone enough to turn enterprise heads, Deloitte and VAST are working together to leverage VAST technology for all of its potential. Powered by NVIDIA GPUs, VAST’s advanced data platform enables enterprises to ingest and process massive amounts of data efficiently. This paves the way for an upcoming generation of agentic computing capable of driving significant business value through improved process automation and smart decision-making.
So what’s the TechArena take? If we were looking at massive scale AI inference adoption and coming agentic workflow integration, this partnership has great potential to add significant value. Deloitte is well positioned to engage with customers on the ground, ensuring that the right workloads are handled effectively. At the same time, VAST’s continuous innovation, which we are notable fans of at TechArena, delivers tailored, scalable solutions to meet the ever-changing demands of the AI landscape which will grow and evolve at the pace of AI. And with uncertainty driven up by the rate of AI change, engaging with these vendors provides some much needed risk-mitigation. We are excited to learn more in the months ahead.
Watch the video here. To connect with Deloitte and VAST Data, check out their websites: deloitte.com and vastdata.com.