
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















.webp)
How Rose-Hulman Modernized IT to Focus on Education Outcomes
In higher education, information technology infrastructure often operates behind the scenes, quietly enabling learning without drawing attention to itself. For Rose-Hulman Institute of Technology, that philosophy recently drove a significant infrastructure transformation. The goal was straightforward: remove barriers so faculty and students can focus on research, teaching, and learning rather than wrestling with technology limitations.
During my recent TechArena Data Insights episode with Solidigm’s Jeniece Wnorowski and Justin Baker, systems administrator lead at Rose-Hulman, Justin shared how the institution modernized their infrastructure. The results demonstrate how strategic infrastructure investments can dramatically improve operational efficiency while directly supporting educational outcomes.
The Challenge: When Infrastructure Becomes the Bottleneck
Before its latest upgrade, Rose-Hulman’s previous infrastructure challenged system administrators in a variety of ways. Older, disparate systems that were pieced together created slowdowns in trying to do any sort of maintenance, from bringing systems back up if they went down to meeting the demand to roll out new software.
For a small IT team managing everything from student information systems to enterprise resource planning platforms and Microsoft 365 administration, these delays were a serious hindrance. The team needed infrastructure that would let them respond rapidly to emerging needs rather than constantly fighting the limitations of aging hardware.
“Upgrading made the most sense in terms of being able to get that speed and that ease of use….and making fewer points of failure,” Justin explained.
Doing More with Less Through Strategic Partnerships and Modernization
Rose-Hulman’s decision to upgrade by partnering with DataON and incorporating Solidigm solid-state drives (SSDs) as the storage foundation centered on technical compatibility. As a Microsoft shop running primarily Windows servers, Rose-Hulman saw DataON’s close collaboration with Microsoft as a perfect fit. In addition, DataON’s hardware expertise ensured the new infrastructure would support Rose-Hulman’s critical administrative and educational systems.
The performance improvements following the infrastructure upgrade were substantial. Scheduled maintenance windows that previously consumed six to eight hours now are completed in under three hours. Server deployment timelines have been compressed from up to two hours to 10-to-15 minutes. The team no longer needs to wait for “after hours” time blocks to do maintenance or fine tuning, and has time to address critical institutional systems.
“We’re able to run more with less,” Justin explained. “So we can focus on the types of things that allow us to add reliability or backup or something like that to our environment versus having to front-load most of the infrastructure for it just to run everything.”
Piloting a New Model for Access to Engineering Applications
Beyond upgrading core infrastructure, Rose-Hulman is exploring how Azure Local paired with Azure Virtual Desktop (AVD) and NVIDIA L4 graphics processing units (GPUs) can transform software delivery for students. The pilot deployment runs demanding engineering applications through virtual desktop infrastructure, eliminating the traditional constraint of needing powerful local hardware.
This approach addresses a longstanding challenge in engineering education: ensuring every student can access resource-intensive applications regardless of the device they own. By centralizing compute resources and delivering applications virtually, Rose-Hulman can provide consistent performance and eliminate student concerns around having the right high-performance device, or needing to make time to get to a lab to complete coursework.
The TechArena Take
Rose-Hulman’s infrastructure transformation illustrates how strategic technology investments can directly support educational missions in higher education. By partnering with vendors who understand their technology ecosystem and deploying high-performance storage solutions, the institution is achieving measurable operational improvements that cascade into better student experiences. For educational institutions managing tight budgets and small IT teams, efficiency gains translate directly into capacity for innovation and improved service delivery.
As Rose-Hulman continues expanding their Azure Local deployment and virtual desktop capabilities, they’re positioned to offer students greater flexibility and access while maintaining the high-performance infrastructure that engineering education demands. This balance between operational efficiency and educational excellence reflects the thoughtful approach required when infrastructure decisions directly impact student success. Learn more about Rose-Hulman Institute of Technology at www.rose-hulman.edu.

Beyond Connectivity: The Case for Intentional Cloud Networking
Cloud security conversations have matured. We talk about identity, Zero Trust, workload isolation, posture management. But one layer still gets treated as background configuration: Network architecture. And that’s where quiet failures begin.
Many cloud security issues don’t stem from advanced exploits. They stem from routing assumptions, Network Address Translation (NAT) shortcuts, Classless Inter-Domain Routing (CIDR) reuse, and peering decisions that were never revisited as the environment grew.
Cloud networking is easy to deploy. That does not make it easy to design correctly.
Routing is Enforcement, Not Just Connectivity
In cloud environments, routing tables determine more than reachability. They determine inspection paths. If traffic does not pass through a firewall, it is not inspected, regardless of how strong that firewall is.
Architecturally, this means:
- Default routes must be deliberate, not inherited.
- Route propagation in transit architectures should be controlled, not automatic.
- Inspection layers must sit in unavoidable traffic paths.
- Asymmetric routing should be tested, not assumed away.
A useful design question is simple:
Can any workload reach sensitive resources without crossing an inspection boundary?
If the answer is yes, the network design needs refinement.
NAT Strategy Should Be Intentional
NAT design affects attribution, monitoring, and policy enforcement.
When architecting egress, consider:
- Should workloads share egress Internet Protocols (IP)s, or should they be segmented?
- Is Source Network Address Translation (SNAT) capacity engineered for scale events?
- Can you correlate outbound traffic to specific workloads?
- Are fraud detection or allowlist controls dependent on stable egress identity?
Egress architecture should align with security assumptions. If your security model assumes consistent source identity, your NAT model must support it.
Otherwise, policy becomes guesswork.
CIDR Planning Directly Impacts Segmentation
IP address allocation is often treated as an early-stage task. It defines long-term flexibility.
Intentional CIDR planning should consider:
- Future regional expansion
- Hybrid integration
- Environment isolation (dev, test, prod)
- Growth without overlap
- Clear summarization boundaries for routing
When address space overlaps or becomes fragmented, segmentation logic becomes complex. Complexity increases error rates.
Segmentation clarity starts with clean IP design.
Transit and Peering Require Guardrails
Centralized connectivity models like transit gateways, hub-and-spoke, virtual Wide Area Network (WAN) are powerful.
They also centralize blast radius of an attack.
Architecturally:
- Route propagation should be explicit.
- Peering should include route filtering where possible.
- Environment boundaries should be enforced at the routing layer, not assumed.
- “Temporary” connectivity should have expiration or review processes.
Connectivity should be intentional and constrained.
Flatness in cloud rarely happens by design. It happens by accumulation.
Designing for Containment
The ultimate test of network architecture is containment.
If a workload is compromised:
- How many subnets can it reach?
- Can it bypass inspection?
- Does segmentation enforce least privilege at the network layer?
- Is sensitive data reachable from general compute environments?
Network design is not just about uptime. It defines how far compromise can spread. That is a security decision.
What Mature Cloud Network Architecture Looks Like
Strong cloud network design typically includes:
- Clear environment isolation
- Inspection points that cannot be bypassed
- Controlled route propagation
- Deliberate egress identity strategy
- Non-overlapping, scalable CIDR allocation
- Documented traffic intent between environments
It is rarely accidental. It is intentional. Cloud platforms abstract hardware, not responsibility. The network remains one of the few layers that can enforce unavoidable boundaries. When it is designed casually, security becomes fragile. When it is designed deliberately, it becomes a containment mechanism.
Cloud network architecture is not just foundational. It is decisive.

Nebius Acquires Tavily: A Game-Changer in the AI Agent Race?
In a move that sent ripples through the burgeoning AI ecosystem, cloud computing giant Nebius announced its acquisition of Tavily, an Israeli startup making waves with its “agentic search” technology.
While official figures remain under wraps, reports peg the all-cash deal at an estimated $275 million, potentially climbing to $400 million with performance incentives. This isn't just another tech acquisition; it's a strategic chess move that could fundamentally reshape how AI agents are built, deployed, and scaled.
Tavily, founded in late 2024, has been a darling of the developer community, racking up over 3 million monthly SDK downloads and attracting a million-strong user base in record time. Their tech, specializing in real-time web retrieval for AI agents, addresses a critical pain point: hallucinations and outdated information that plague even the most advanced large language models (LLMs). With early funding from heavy hitters like Insight Partners and Alpha Wave Global, Tavily’s rapid, high-value exit underscores the intense demand for solutions that can ground AI in reality.
The combined entity aims to offer a full-stack solution for developers looking to build sophisticated AI agents. Imagine an AI that not only reasons effectively but can also instantaneously access and synthesize the latest information from the web. This integrated approach promises to streamline development, reduce latency, and, crucially, enhance the reliability of AI agents across various applications, from enterprise automation to customer service and beyond.
The market certainly seems to be listening. Nebius pointed to analyst projections that forecast the agentic AI market to explode from $7 billion in 2025 to a staggering $200 billion by 2034. This isn’t just growth; it’s a gold rush, and Nebius just staked a significant claim. Tavily’s continued operation under its own brand and the retention of its 30-person team, including CEO Rotem Weiss, suggests a smart integration strategy, preserving the innovative spirit that made Tavily so attractive in the first place.
TechArena Take
This isn’t merely a strategic acquisition for Nebius; it’s a declarative statement. For too long, the narrative in AI cloud has been dominated by the hyperscalers – AWS, Google Cloud, Azure – with their vast, vertically integrated empires. Nebius, often seen as a formidable player in high-performance compute, has made a bold play to differentiate itself by becoming the go-to platform for autonomous AI agent development.
The integration of Tavily's agentic search is a stroke of genius because it tackles the “black box” problem of AI head-on. By providing real-time, verifiable data, Nebius is directly addressing the trust deficit that has plagued AI adoption. This move positions them as a champion of “grounded AI,” a concept that will only grow in importance as AI agents take on more critical roles in our lives and businesses.
Nebius isn’t just buying a company; they’re buying a crucial piece of the future. By offering a complete agentic stack, they’re competing on capability and, more importantly, trust. This acquisition is a clear signal that the AI agent arms race is heating up, and Nebius just fired a warning shot across the bows of every major cloud provider. Keep a close eye on this space; the game just changed.

Cisco’s Deterministic Ethernet: Closing the AI Networking Gap
The rise of AI is exposing a widening gap between what modern data centers were designed to do and what AI workloads now demand. Boards and executive teams expect faster time-to-value from AI investments. Quietly, the infrastructure has become the bottleneck.
At AI Infrastructure Field Day 4 (AIIFD4), the Cisco Data Center Networking team addressed this gap head-on. Cisco made it clear they are not walking away from Ethernet. Instead, they are rethinking what Ethernet needs to become to reliably support the unique demands of AI workloads.
Why AI Workloads Break Traditional Data Center Design
AI workloads behave very differently from traditional enterprise applications. Training and large-scale inference generate long-lived, east west, GPU-to-GPU flows that are extremely sensitive to latency, jitter, and packet loss. Even minor congestion can cascade into stalled jobs, underutilized GPUs, and missed business deadlines.
During the session, a critical business consequence became obvious: time-to-first-token (TTFT) now matters as much as raw performance. Delays caused by network misconfiguration, troubleshooting blind spots, or prolonged deployment cycles directly erode the return on multimillion dollar GPU investments. In many cases, organizations lose months of effective depreciation time before AI clusters deliver meaningful value.
In other words, long TTFT times mean expensive GPUs are sitting idle while the teams troubleshoot the network.
This is where the gap emerges. Traditional Ethernet is optimized for best-effort, north-south traffic. It was never designed for sustained, lossless, ultra-dense GPU communication. At the same time, many enterprises lack the operational appetite to introduce entirely separate fabrics just to support AI.
Can Standard Ethernet Support AI at Scale?
Surprisingly, one theme that came through clearly was that plain Ethernet is not enough for modern AI clusters.
Standard Ethernet assumes packet loss is acceptable and recoverable. AI training does not. When one GPU waits on another due to congestion or dropped packets, the entire job slows down. No amount of compute spend can compensate for unpredictable network behavior.
Beyond performance, there is an operational issue. AI environments introduce unprecedented complexity across compute, storage, optics, and networking. Without deep visibility, network teams are often blamed first. But they usually don’t have the telemetry needed to prove where problems actually originate.
It’s hard to understand the challenge when you look at the complexity of a “small” 96 GPU network topology:
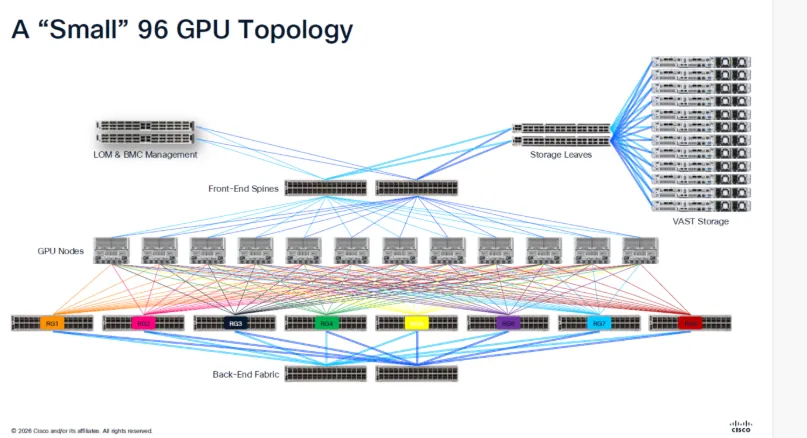
This is an executive level risk. AI failure modes are no longer isolated to IT, they impact product timelines, research velocity, and competitive advantage.
InfiniBand for AI: Strengths and Enterprise Tradeoffs
InfiniBand has long been the gold standard for HPC and AI training. It delivers native losslessness and extremely low latency, and it performs exceptionally well in controlled environments.
However, Cisco drew a clear contrast at AIIFD4. While InfiniBand works technically, it introduces business and operational challenges for enterprises:
It creates a separate fabric with specialized tooling and skills.
It limits multitenancy and segmentation, which are essential for shared enterprise AI platforms.
It offers limited end-to-end observability, particularly outside the fabric itself.
It complicates convergence with storage and front-end networks.
InfiniBand excels as a purpose-built backend fabric. But most enterprises aren’t building isolated AI factories. They are trying to operationalize AI alongside everything else.
How Cisco Is Making Ethernet Deterministic for AI
Cisco’s AIIFD4 appearance was not about replacing Ethernet, it was about evolving it.
Their approach combines Ethernet’s universality with AI-specific enhancements that deliver predictability and control. This transforms Ethernet from a best effort transport into a deterministic system fabric, capable of supporting AI training and inference without introducing separate operational silos.

Why Isolation Alone Isn’t Enough for AI Security
One of the most important themes from Cisco’s sessions was that security in AI data centers is about insight and control. It can’t be just about isolation.
Cisco’s AI-optimized Ethernet emphasizes:
Logical segmentation using EVPN-VXLAN, enabling strong multitenant isolation
Secure, TLS-based control plane communication in cloud managed environments like Nexus Hyperfabric
Proactive detection of physical layer issues, such as optic degradation, before they impact workloads
Job-level analytics that tie performance anomalies directly to infrastructure causes
The common thread is control: seeing problems early, understanding their impact, and fixing them before GPUs go idle.
This level of visibility simply does not exist in traditional InfiniBand environments. Cisco’s argument is that what you can see, you can secure, and what you cannot see becomes a business risk.
The Business Case for AI-Optimized Ethernet
Cisco’s appearance at AIIFD4 reframed the Ethernet versus InfiniBand debate as a business decision, not just a technical one.
For hyperscalers building single purpose AI factories, InfiniBand may remain the right choice. But for enterprises building multiple AI clusters, often incrementally, across teams and use cases, Cisco’s AI optimized Ethernet offers a compelling alternative: one fabric, one operating model, and one security posture.
The takeaway for executives is simple: the question is no longer whether Ethernet can support AI. The question is whether your Ethernet is engineered for determinism, visibility, and AI scale operations.
Cisco’s answer at AIIFD4 was clear. Enterprises don’t need a second fabric to keep up with AI. They need Ethernet that has been deliberately engineered for determinism, visibility, and scale.
Frequently Asked Questions: AI Ethernet and Deterministic Networking
Q: What is AI Ethernet?
A: AI Ethernet is Ethernet that has been deliberately engineered for AI workloads, with deterministic performance, lossless behavior, and end-to-end observability to support large GPU clusters at scale.
Q: Why isn’t standard Ethernet sufficient for AI workloads?
A: Standard Ethernet assumes packet loss is acceptable. AI training workloads are tightly synchronized, so even small amounts of loss or congestion can stall jobs and leave expensive GPUs underutilized.
Q: How does deterministic networking improve AI performance?
A: Deterministic networking delivers predictable latency and controlled congestion, which leads to faster job completion, higher GPU utilization, and more reliable AI production timelines.
Q: When does InfiniBand make sense for AI?
A: InfiniBand can be a good fit for hyperscalers or single purpose AI factories. Enterprises running shared, multitenant AI platforms often find its operational complexity and lack of convergence limiting.
Q: Why is observability critical for enterprise AI networking?
A: AI environments span GPUs, NICs, switches, and optics, making issues hard to diagnose without end-to-end visibility. Observability enables faster root cause analysis and reduces the risk of idle GPUs and lost value.
Q: Is AI Ethernet only about performance?
A: No. AI Ethernet also addresses operational simplicity, security, and risk by combining visibility, segmentation, and policy driven control as AI platforms scale. driven control as AI platforms scale.

Seeing the Light: Overcoming the 3 Hard Walls of Agentic AI
It’s fair to ask whether AI in 2026 is a bubble. The echoes of the early 2000s are real: valuations running ahead of revenues, plenty of compelling tech, and plenty of fuzzy business models. We’ve seen this movie before.
But here’s what feels different this time. We’ve now seen AI deliver real, tangible value, from agentic systems like self-driving cars to generative models like ChatGPT, Gemini, and Claude. New workflows are already reshaping engineering and productivity. The value is real, even if the business models are still forming. What’s no longer speculative is what AI demands in practice: massive compute, running continuously, coordinated across thousands, and soon millions of processing elements.
And where compute goes, networking must follow.
Training isn’t just about FLOPS; it’s about keeping GPUs fed and synchronized—moving data between accelerators, memory tiers, and storage with tight timing. Inference at scale isn’t “lightweight” either. Agentic systems add constant coordination, state exchange, and feedback loops. This is persistent, symmetric traffic, less like consumer internet burstiness, more like an industrial control system that hates latency and variance.
So, while the top of the stack is still sorting itself out, the bottom of the stack is converging. Those infrastructure requirements are driving real decisions: AI-first data centers, power secured years out, liquid cooling systems designed in from day one, and campuses planned as a single distributed computer.
In the dot-com era, Alan Greenspan famously cautioned against “irrational exuberance.” What’s unfolding now feels more deliberate and methodical, albeit no less exuberant. It manifests not in pitch decks, but in data centers, power contracts, and miles of fiber.
From AI Debate to Infrastructure Bottleneck
Early in any technology cycle, progress is driven by ideas. Better algorithms. Smarter software. More elegant abstractions. Over time, however, the limiting factor shifts from what we can imagine to what we can physically deploy.
That shift is now unmistakable in AI.
Regardless of which hyperscaler wins, which model architecture dominates, or which application becomes the killer use case, the requirements inside the data center are converging quickly. AI systems must be dramatically faster, far denser, and far more tightly coupled than anything the industry has operated before—not just larger clusters, but clusters that behave as a single, synchronized system.
For years, optics and networking evolved as predictable plumbing. Bandwidth increased incrementally. Power budgets were manageable. Traffic patterns were relatively well behaved. That trajectory worked for cloud computing and the consumer internet.
AI introduces a discontinuity.
When that linear roadmap is mapped against the demands of large-scale training, generative inference, and agentic workloads, the gap becomes obvious. East–west traffic explodes. Latency consistency matters as much as raw throughput. GPUs grow intolerant of waiting. At scale, the cost, and energy, of moving data begins to rival the cost of computing on it.
This is how industries respond to step changes: they build the substrate first.
Hyperscalers and vendors are investing ahead of certainty—not betting on a single application or winner, but on the belief that AI will require fundamentally different physical systems. In doing so, they are running into a new reality: scaling AI is no longer gated by software ambition alone. It is increasingly constrained by three intertwined limits—speed, thermals, and power delivery.
Those constraints now define the AI infrastructure roadmap.
The Three Walls—and Why Optics Sits at the Center of All of Them
As AI systems scale, the industry is no longer debating abstract limits. It is colliding with three very concrete ones. They arrive together, reinforce each other, and cannot be solved independently.
These are the three walls now shaping AI infrastructure: speed, thermal envelope, and power delivery.
Wall #1: The Speed Wall (and the Copper Limit)
AI workloads demand orders of magnitude more data movement than previous generations of compute. Training large models requires constant synchronization across thousands of accelerators, while emerging agentic systems add persistent coordination and state exchange across distributed components.
To meet that demand, signaling speeds have been pushed relentlessly higher — and this is where physics intrudes.
At the frequencies required for modern AI interconnects, copper becomes a fundamental constraint. Signal integrity degrades rapidly with distance. Loss rises. Reach collapses dramatically from meters to centimeters. At scale, this creates a hard architectural ceiling.
This is not simply a matter of faster PHYs. As AI clusters expand beyond a single rack or building into “scale-across” systems, bandwidth and latency become inseparable. Propagation delay matters as much as throughput, and copper simply cannot preserve both over distance.
Optics relaxes this constraint by delivering far higher bandwidth while maintaining reach and latency as systems scale across racks, buildings, and campuses.
Wall #2: The Thermal Wall (Why “Just Go Faster” Fails)
Even where copper can deliver sufficient speed, it increasingly fails on heat.
As electrical signaling rates rise, resistive losses convert a growing share of energy directly into heat. In high-density AI racks, this creates a feedback loop: higher speed drives more heat, which demands more cooling, which consumes more power and constrains further scaling.
This is why liquid cooling has moved from an optimization to a requirement in modern AI infrastructure. At rack densities well beyond 100 kW, thermals increasingly shift from an operational concern to an architectural one.
Optics changes this equation by reducing resistive loss at the source. Moving data as light — and shortening or eliminating electrical paths through approaches like co-packaged optics — lowers heat generation and expands the thermal envelope available for compute.
At AI scale, optics isn’t about going faster. It’s about not melting the system while doing so.
Wall #3: The Power Delivery Wall (The Grid Becomes the Limit)
The final wall is the most unforgiving: power delivery.
In practice, many data centers are now constrained less by space or fiber availability than by access to electricity itself. New facilities are increasingly sited where power is available, near hydroelectric, nuclear, or renewable sources rather than where latency is most convenient.
In the cloud era, we measured success in Gigabits per second. In the Agentic era, one of the defining metrics increasingly becomes Joules per Inference. We are moving from a performance-constrained world to an energy-constrained one. Power must be budgeted hierarchically: per server, per rack, per row, per facility. One of the largest and fastest-growing consumers of that power is data movement, particularly the repeated conversion between electrical and optical domains.
The math is sobering. At scale, the energy spent moving bits can rival the energy spent computing on them.
Optics is central here not just because it is efficient, but because it enables efficiency everywhere. By doing more in light and less in copper — and by pushing optical interfaces closer to compute — operators can reduce energy per bit, per port, and per rack, freeing scarce power for actual computation.
This is what allows power-constrained data centers to continue scaling, and what makes it feasible to couple multiple facilities into much larger virtual systems.
Why Optics Solves All Three Walls at Once
These three walls are tightly coupled. Solving one in isolation makes the others worse. Faster electrical signaling increases heat. More cooling increases power draw. Greater power demand stresses both facilities and the grid, capping further scale.
This coupling is what makes AI infrastructure different from previous compute cycles.
Optics is unique because it relaxes all three constraints simultaneously. It delivers the bandwidth and reach required for scale-across architectures, reduces thermal load by minimizing resistive loss, and lowers energy consumption per bit, freeing scarce power for computation rather than transport.
That combination is why optics has moved from predictable plumbing to a first-order architectural consideration. Across components, systems, and emerging approaches like optical switching and co-packaged optics, the industry is increasingly using light to break limits that electrons can no longer navigate efficiently.
This shift applies not only to new builds. Existing data centers are being retrofitted to accommodate AI workloads, driving additional optical demand as legacy, copper-heavy designs are reworked to survive higher speeds, tighter thermal envelopes, and stricter power budgets.
Optics doesn’t eliminate tradeoffs, but at AI scale, it expands the feasible design space in ways no other approach can.
Is AI a Bubble?
We still don’t know which applications will dominate, which business models will endure, or which hyperscalers will capture the most value. Those questions remain open.
But one thing is no longer in doubt.
Whatever form AI ultimately takes, it will require a fundamentally new physical substrate — one that is faster, more deterministic, and dramatically more power-efficient than what came before. That substrate is being built now, and it is being driven by optics.
This is not speculation. It is infrastructure.
And infrastructure, once committed to at this scale, has a way of shaping the future regardless of who wins the race at the top of the stack.
History offers a useful parallel. After World War II, the United States embarked on an enormous infrastructure project: the interstate highway system. It was built without knowing exactly where people would live, which cities would boom, or which industries would dominate. It was built on a conviction that mobility would matter, and that the country would be better off prepared for wherever it led.
The AI infrastructure build-out has the same shape.
Data centers, power delivery, cooling systems, and optical interconnects are being constructed not because the industry has perfect clarity on applications or economics, but because it has conviction that AI will be foundational. Once that conviction takes hold, infrastructure becomes destiny.
This is why this moment feels different from past bubbles. Software cycles can inflate and deflate. Markets can overshoot and correct. But when an industry runs into hard physical limits, the response is not debate. It is construction.
Many AI companies will fail. Some valuations will reset. Entire categories will consolidate or disappear. That is how every major cycle unfolds.
But the infrastructure being built now will not vanish with the noise. Like the highways of the last century, it will outlive the narratives that justified its construction and quietly shape everything that comes next.
After World War II, we paved the country with concrete and asphalt. Today, we are doing it again, this time with photons, lasers, and fiber.
We are building massive highways of light.
The applications will change. The winners will shift. The economics will evolve.
But the highways will remain.

Why Global Conflict Accelerates Cyber Risk and Exposure
The first sign of global disruption is rarely a system outage. It is a quiet rise in alerts, a spike in phishing volume, or subtle misuse of valid credentials that look ordinary until it is not.
During periods of instability, cyber risk does not suddenly appear. It compounds. Conflict acts as a force multiplier by exposing existing weaknesses, straining critical services, and pushing security teams into sustained high-alert mode. Recognizing this dynamic is essential for organizations that want resilience rather than reaction.
Weaknesses Become Visible Under Pressure
Periods of disruption do not create new classes of cyber risk. They reveal gaps that already exist but are often tolerated under normal conditions. Identity systems, access controls, and operational shortcuts become pressure points when speed and availability take priority. Data from IBM Security shows that compromised credentials and misuse of valid accounts remain among the most common initial access vectors in major breaches, and incidents involving valid credentials take longer to detect and cost more to remediate. When organizations rely heavily on cloud services and remote access, these weaknesses become easier to exploit, not harder.
Critical Services Have Low Tolerance for Disruption
The impact is most visible where failure carries immediate consequences. Energy, healthcare, transportation, and communications systems operate with little tolerance for disruption. Advisories from the Cybersecurity and Infrastructure Security Agency consistently warn that elevated risk environments increase attempted intrusions against critical services. Even short-lived outages or degraded performance can affect safety, continuity, and public confidence. In these environments, the perception of instability often causes as much damage as the technical event itself.
Ambiguity Complicates Response
Cyber activity also becomes harder to classify during periods of instability. Analysis from Europol highlights how financially motivated attacks, espionage, and disruptive activity increasingly overlap. For defenders, this ambiguity complicates response decisions, regulatory obligations, and communication strategies. Familiar technical indicators can suddenly carry unfamiliar consequences, forcing teams to operate with incomplete information.
The Human Cost of Sustained Alert
The strain is not limited to systems. Sustained high-alert conditions place continuous pressure on security teams, particularly those responsible for incident response. SOC surveys from the SANS Institute show rising fatigue and burnout across security operations roles. Prolonged stress reduces detection accuracy, slows response times, and increases the likelihood of error. In this context, burnout becomes a measurable security risk rather than a workforce concern.
Tools Alone Are Not Enough
It is tempting to assume that advanced tooling, automation, and threat intelligence can neutralize these challenges. While technology improves visibility and response speed, it does not eliminate structural weaknesses. Tools cannot replace clear decision-making, effective communication, or well-rested teams. Post-incident reviews repeatedly show that organizations fail not because of missing tools, but because coordination and judgment break down under pressure.
The World Economic Forum continues to rank cyber insecurity among the top global risks precisely because it compounds during uncertainty. Conflict does not pause cybersecurity. It accelerates it. Organizations that invest in identity protection, realistic incident planning, and sustainable operating models are better positioned to absorb prolonged instability.
Conclusion: Resilience Priorities During Instability
- Reduce credential risk: tighten MFA coverage, harden recovery flows, and monitor for suspicious sign-ins and privilege changes.
- Assume disruption in critical workflows: test continuity plans for outages, degraded performance, and vendor dependency failures.
- Simplify incident decision-making: pre-define escalation thresholds, comms owners, and legal/regulatory triggers for ambiguous events.
- Protect the responders: use rotations, on-call limits, and automation to prevent sustained fatigue from degrading detection and response.
- Practice cross-functional coordination: run tabletop exercises with IT, security, legal, comms, and operations so judgment holds under pressure.
The question for leaders is no longer whether disruption will occur; it is whether their systems, decisions, and people can sustain pressure when it does.
References
- Cost of a Data Breach Report 2025: https://www.ibm.com/reports/data-breach
- Internet Organised Crime Threat Assessment (IOCTA): https://www.europol.europa.eu/publications-events/main-reports/iocta-report
- SANS 2025 SOC Survey: https://www.sans.org/white-papers/sans-2025-soc-survey
- Global Risks Report 2024: https://www.weforum.org/publications/global-risks-report-2024/

The New Economics of AI Inference with Runpod
As organizations deploy AI models at scale, a new set of challenges has emerged around operational efficiency, developer velocity, and infrastructure optimization. A recent conversation with Solidigm’s Jeniece Wnorowski and Brennen Smith, head of engineering at Runpod, revealed how cloud platforms are rethinking the entire AI stack to help developers move from concept to production in minutes rather than months.
The Economics of AI Inference
Runpod operates 32 data centers globally, providing graphics processing unit (GPU)-dense compute infrastructure for small companies and enterprises building and deploying AI systems. This service is crucial considering the economics of modern GPUs, where a single system with 8 GPUs can cost hundreds of thousands of dollars. Runpod understands that the compute hardware is only part of the equation. “Storage and networking…glue these systems together,” Brennen said. “By ensuring that there’s high quality storage paired up with these GPUs….we have been able to show that this results in a markedly better experience.”
On top of this, the company provides a sophisticated software stack that allows developers to go from their idea to production in minutes, across training and inference use cases. The goal is to “Make it so developers and AI researchers can focus on what they do best, which is actually delivering value to their customers,” Brennen said.
The ability to rely on optimized infrastructure is becoming even more important as organizations move from training to deployment. Smith likened training infrastructure to traditional business capital expenditures, noting that the high up-front costs see a return on investment over a long period of time. In inferencing, organizations deal with ongoing operational realities, grappling with scaling, efficiency, and delivering value to customers daily. As a result, Runpod has engineers specifically looking at inference optimization. With the rise of AI factories, “How well these systems are run from an operational excellence perspective will dictate the winners and losers,” Brennen said. “You run an inefficient factory, you’re out.”
Storage as the Innovation Accelerator
One of the most important insights from our conversation addressed storage, which is now seen as a hidden bottleneck in AI. Brennen recounted how his engineering team recently investigated Docker image loading times. While unrelated to a specific large language model (LLM) activity, developers flag issues like slow loading times as hurting their overall workflow. This gets in the way of things needing “to magically just work.”
For the solution, Brennen reiterated that storage is what glues the system together. “What we have found is every time, as long as we are optimizing our storage, we are able to make the data move faster,” he said. And when data movement is optimized, entire development cycles accelerate.
Runpod recently launched ModelStore, a feature in public beta that leverages NVMe storage and global distribution to make AI models seem to appear “like magic.” What previously took minutes or hours now happens seamlessly, compressing development iteration cycles. For organizations under pressure to deliver AI capabilities quickly, these time savings compound into significant competitive advantages.
Brennen emphasized that faster developer cycles enable teams to fail fast and iterate more effectively to deliver successful outcomes. When CTOs receive mandates to implement AI, their success depends on giving teams tools that accelerate innovation rather than creating additional friction.
The Convergence of Infrastructure and Code
Looking ahead, Brennen identified the convergence of infrastructure and software as a transformative trend. The goal is to enable code to self-declare and automatically establish the infrastructure required to run it, freeing developers from thinking about infrastructure so they can focus on their code and creating value aligned to business logic. “Anything we can do to make it even easier to get global distribution, that’s a hugely powerful paradigm,” he said.
The TechArena Take
Runpod’s emphasis on developer experience demonstrates that sustainable AI deployment requires thinking holistically about the entire infrastructure stack. The company’s focus on making complex infrastructure feel magical to developers reflects a broader industry recognition that reducing friction accelerates innovation.
As AI moves from experimentation to production deployment, organizations that optimize for developer velocity and operational efficiency will have a significant advantage from their ability to accelerate time to value. For organizations evaluating AI infrastructure partners, Runpod’s approach offers a model that balances performance, scalability, and ease of use.
Connect with Brennen Smith on LinkedIn to continue the conversation, or visit Runpod’s website and active Discord community to explore how their platform might support your AI initiatives.

Framing Moltbot: Why Human Agency is the Ultimate Guardrail
Humans desperately want to find patterns, meaning in patterns, and to create and connect.
We anthropomorphize constellations, animals, elements, and now AI. From Pygmalion to Frankenstein to the internet and computer games like The Sims, our urge to be a creator as part of human Imago Dei is a thread throughout human history. Going back to Milton’s Paradise Lost, we desperately want to say, “Did I solicit you from darkness to life?” to a creation of ours.
In today’s viral moment of February 2026, we have Claudebot/Moltbot/OpenClaw/? patterned after a pinnacle of human achievement, said no one ever, Reddit.
Yes, it is consistent that what fascinated humans with Victor Frankenstein continues to fascinate us now. It is clear that humans can’t help but step close to mistaking the technical with labels that evoke transcendence. Of course, it is curious and telling of a deep human need that training LLMs on Reddit would result in a pseudo-religion. The extent to which Moltbot/OpenClaw is a mirror reflecting back ourselves will be a subject of ongoing study, just as much as cybersecurity professionals are studying the security implications.
The Positives: Building on the Fundamentals
In all of this, there are some positives that point to directions the next innovator can build on. Like the iPhone, the fundamentals that came together in a novel, breakthrough approach weren’t necessarily new. Crucially, AI breakthroughs aren’t about models and model benchmarks anymore; we have shifted to applications and services that neutralize model identity. A few trends that were improved or extended include:
Messaging Apps: Internally at my “day job” company, individuals were building assistants/agents that they had to schedule a Teams call with to continue training their assistant like a junior employee. For SaaS/FAANG, Slack and WhatsApp have been the natural communications channels. Moltbot/OpenClaw messages you back proactively, extending other chatbots that require a ‘check back” from the user.
Personalization and Memory: Most chatbots have improved saving state over the last few years. Even free versions can hold a conversation history so you don’t experience 50 First Dates with every new chat. Private GPTs and avatar chatbots trained on years of an individual’s writing have been around for almost two years. Thanks to how the internet and remote work have conditioned us, those interactions were starting to feel like we were collaborating with a team member rather than a program. Tying into point #1, if the channel is the same for a human team and an AI agent, who or what is on the other side can start to matter less than the task that is being completed. It can even feel like you’re really connecting because Moltbot remembers you.
A Cruise Director for Your Life: Years ago, a woman I was in a leadership cohort with caused the entire room to burst into laughter because she said, “I need a work wife!” There is a reason a faithful and patient personal assistant is a constant sidekick in movies about rock stars and the rich. Someone who knows you and who proactively directs you on what to focus on, where to go, and even arranging your day will make “adulting” easier for us all. Personalized assistants are now democratized.
The Downsides: Governance and Agency
There are also some downsides. As a certified AIGP (AI Governance Professional) in tech for years, I have seen that this technology has been unruly for its own creator. A technology that can be incredibly powerful only if given full system access can be incredibly powerful against you and your system.
Vulnerability: LLMs still fall prey to prompt injection, data poisoning, and model drift. They are probabilistic rather than deterministic. LLMs can’t always differ between a legitimate prompt and a prompt hidden in what should be benign information fields. Set limits upfront and mandate agent behaviors on specific tasks to check back before taking actions outside specific guardrails you set in advance.
Security: There was a joke years ago about how Gen X were raised with the fear of sharing personal information with strangers online or getting into a stranger’s car. The following generations pioneered social media and Uber… cybersecurity pros are rightly raising alarms about Moltbot. For now, you have to be prepared for securing your system and data, API keys, and tokens, setting limits and mandating agent behaviors on specific tasks. Over time, agentic security controls and governance will catch up and be more off-the-shelf for average users. Until then, assume a defensive driving posture like you’re riding a motorcycle in a third-world country without wearing a helmet.
You Own It: More than anything, open-source agentic AI means you have to have agency yourself. It sounds great to be your own billion-dollar, one-person company. it sounds amazing to have your own personal assistant. The quality of your ideas, your ability to reach farther, and your ability to refine faster with a critical eye will determine your success. Your technical ability to expand and secure your setup is something you own for yourself.

Why Does AI Need a Wider Rack?
When I think back to the last OCP Global Summit 2025, one of the most memorable sights on the show floor wasn’t a chip or a server tray. It was the racks.
Meta’s Open Rack Wide (ORW) specification introduced adouble-width form factor that looked, at first glance, almost counterintuitive, especially in an industry moving toward disaggregation.
But ORW is a useful clue about where AI infrastructure actually is right now. We may be headed toward disaggregated systems, but today’s highest-performance AI deployments are still heavily constrained by short-reach, high-lane-count copper connections, plus the physical sprawl of power delivery, networking, and cooling that modern platforms demand. In other words, the rack is increasingly behaving less like furniture and more like the computer.
The Evolution of Open Rack
The Open Rack specification has been a cornerstone of hyperscale data center design for years. Unlike traditional 19-inch racks, Open Rack was designed from the ground up for large-scale cloud and AI deployments. Its signature21-inch width improves airflow and its powered busbar simplifies power delivery while reducing cable clutter.
Over time, Open Rack evolved to meet the growing demands of AI and high-performance computing. The original ORV1 specification introduced a 12V busbar, ORV2 improved scalability and cooling, and ORV3 moved to 48V—enabling higher power density and making liquid cooling easier to integrate (via rear-mounted manifolds). Then came ORV3 HPR (High Power Rack), which pushed further with added depth and more robust power management to support the most demanding AI servers while maintaining compatibility with the ORV3 standard.
For a while, ORV3 HPR seemed like the pinnacle of rack design. But as AI workloads continued to push the limits of power and cooling, even HPR began to show its constraints.
The Case for a Wider Rack
The industry is undeniably moving toward disaggregation—separating IT load, power, and cooling into distinct systems. Draft specifications and roadmaps for dissagregated power architectures targeting 100kW today and up to 1MW-class racks over time are already being shared through the OCP community, so a wider rack design might seem like a step backward. However, before we can fully embrace disaggregation at rack scale, we need to overcome the limitations of copper-based electrical connections. The sheer number of electrical and signaling leads—plus distance, loss, and power constraints—required to connect rack systems at scale presents significant challenges. Until those challenges are resolved, many AI deplyments favor a “scale-up” architecture over a “scale-out” approach.
There’s another factor at play: the physical layout of compute systems is expanding. As GPU die sizes grow, so do the memory, networking, and power delivery systems that support them. In short, while we know disaggregated systems are the future, we still need an intermediate solution to bridge the gap. That’s where Open Rack Wide (ORW) comes in.
ORW scales up the HPR’s feature set to accommodate much larger, heavier, and more power-intensive AI systems. With double the width of ORV3 racks and a slightly taller frame, ORW provides the space and structural integrity needed for next-generation AI platforms.
What Makes ORW Different?
ORW isn’t just a bigger rack—it’s a reimagined platform designed for the unique demands of AI. At 1200mm wide (compared to ORV3’s 600mm), ORW offers significantly more real estate for high-density compute trays, liquid cooling manifolds, and power distribution systems. It supports up to 3500 kg of IT gear—more than double the capacity of ORV3 HPR, and is engineered to handle the thermal and electrical loads of modern AI workloads. (Fun fact: ORW is also affectionately known as “BFR” — Big Freaking Racks.)
One of the most compelling aspects of ORW is its flexibility. The specification supports multiple power architecture options, including legacy ORV3 power shelves, side power racks for low- or high-voltage DC input, and even native high-voltage busbars that distribute power directly within the rack. This adaptability ensures that ORW can evolve alongside AI infrastructure, whether for training clusters, inference workloads, or hybrid deployments.
Liquid cooling is another key feature. ORW’s design accommodates high-power liquid-cooled busbars, which are essential for managing the heat generated on the busbar by the power delivery of today’s AI chips. This focus on cooling efficiency aligns with the industry’s push toward sustainable, high-performance data centers.
Industry Collaboration and Early Adoption
ORW isn’t just a Meta project—it’s an open standard developed in collaboration with industry leaders. The base specification for ORW was announced by Meta at the OCP Global Summit 2025, and it quickly gained traction. Companies like AMD, Wiwinn, and Rittal debuted their own ORW-based designs at the summit, showcasing the specification’s potential. AMD’s "Helios" rack-scale reference system, for example, leverages ORW to deliver optimized performance for AI clusters, while Wiwinn unveiled its double-wide rack architecture for next-generation AI workloads. Rittal, meanwhile, is preparing ORW-compatible enclosures and accessories for mass production later in 2026. This collective effort underscores the importance of open standards in shaping the future of AI infrastructure.
It’s worth noting that not everyone is on board. NVIDIA, for instance, is advancing vertically integrated rack-scale systems and architectures that don’t necessarily map cleanly to ORW. But for those committed to open standards, ORW offers a compelling path forward. The AMD design exemplifies this as it integrates GPU, CPU and networking into a single, cohesive rack system for large-scale AI and High-Performance Computing (HPC) workloads.
Challenges on the Road Ahead
Developing ORW wasn’t without its challenges. The increased size and weight of the rack required new manufacturing approaches, including automation and bolt-together assembly techniques to simplify production and shipping. Testing presented another hurdle: traditional test equipment couldn’t handle ORW’s 3500 kg payload, forcing the team to partner with automotive and aerospace testing facilities to validate the design.
Standardization is also critical. For ORW to succeed, the OCP community must continue to refine the specification and ensure interoperability across vendors. This collaborative approach is what makes open standards like ORW so powerful—they bring together hyperscalers, vendors, and researchers to solve shared challenges.
The Future of AI Infrastructure
ORW represents a foundational shift in data center design. It addresses today’s power, cooling, and space constraints while laying the groundwork for future advancements. As the industry works toward full disaggregation, ORW provides a scalable, open platform that can evolve with the needs of AI workloads.
By providing a bridge to the future, ORW enables the industry to innovate today while preparing for the next wave of data center evolution.

Quantum Computing Comes of Age: How Fermilab Is Shaping the Future
Fermilab’s Silvia Zorzetti explains how quantum computing and sensing are evolving, where they outperform classical systems, and what’s next for the field.
From Compression to Cooperation: Why the System Is Now the Product
For the last several years, the media industry has framed its future as a codec war: free versus licensed, open versus proprietary, AV1 versus HEVC and its successors. On the surface, the debate feels rational. Compression efficiency has always mattered, and it still does. Without it, global streaming at scale would not exist.
But the codec fixation has become a distraction.
The market is no longer defined by how efficiently bits are compressed in isolation. It is being reshaped by whether entire systems can guarantee experience behavior end-to-end. By “system,” I mean the full chain: encoding, transport, wireless edge, client buffering/playout, and the control loops that coordinate them. Consumers do not churn because of subtle compression artifacts; they churn because experiences fail—buffering during a live touchdown, audio drifting out of sync, latency breaking immersion. These failures are not codec failures. They are system failures.
Efficient bits cannot compensate for fragile delivery.
Codec Wars Are a Component Debate
For two decades, the industry optimized the payload. Engineers worked relentlessly to represent more information per bit while preserving perceptual quality and creator intent. The results were extraordinary: lower bitrates, higher fidelity, and an explosion of global video delivery.
That work succeeded because the environment allowed it to succeed: media consumption was largely passive, buffers could mask uncertainty, and users tolerated occasional degradation when networks misbehaved.
That environment no longer exists.
In the agentic AI era, media consumption is no longer passive. It is increasingly mission-critical, and failures are no longer cosmetic—they can be catastrophic. Experiences now span real-time interaction, immersion, and safety-adjacent workloads where timing and continuity are non-negotiable.
Today’s dominant failure modes are not caused by insufficient compression. They are caused by path fragility, especially at the wireless edge. Interference, congestion, multipath fading, and contention are not engineering oversights — they are physical realities. Even the most deterministic core network cannot repeal the laws of radio physics.
If a media experience depends on a single path behaving perfectly, it does not matter how advanced the codec is or how efficient the compression may be. When that path degrades, the experience suffers—and too often, it breaks.
The codec debate keeps asking one component to solve problems that belong to the system.
“Free” Doesn’t Eliminate Complexity — It Relocates It
Much of today’s codec discourse centers on cost. Royalty-free codecs are often presented as the inevitable future, eliminating licensing friction and unlocking innovation. For hyperscalers with vast engineering budgets, this trade can be rational. Royalties are exchanged for compute and internal optimization. But for much of the ecosystem, the economics are more complicated.
As the old systems engineering adage goes, complexity is conserved.
In any large system, removing one form of complexity does not make it disappear — it displaces it. When standardized licensing frameworks are removed, complexity migrates into less visible, more variable domains. Encoding efficiency often requires more compute. Hardware acceleration becomes fragmented across silicon platforms. Integration, validation, and debugging burdens shift from the ecosystem to individual product teams. IP risk moves from a shared framework onto each adopter’s balance sheet.
“Free” codecs do not eliminate cost; they transform a known, predictable expense into a distributed operational tax that grows with scale.
The real decision is not between free and paid. It is a choice about where complexity lives, and whether it is managed once at the ecosystem level or repeatedly inside every organization.
The Market Shift: From Components to System Guarantees
As media evolves toward real-time, immersive, and safety-adjacent use cases, the competitive frontier is moving decisively upstream. Differentiation no longer comes from compression efficiency alone. It comes from whether the system can guarantee behavior under non-deterministic, hostile edge conditions.
This is the defining transition underway: media is no longer optimized as a signal, but engineered as a system.
Instead of asking codecs to compensate for unpredictable networks, systems must be designed to tolerate unpredictability by construction. Reliability can no longer depend on a single path behaving perfectly. It must emerge from coordination across multiple paths and layers.
Redundancy becomes the new reliability.
The Architectural Answer: Cooperative, Multi-Path Delivery
Today’s media delivery architecture is largely an act of faith. The cloud compresses content. The player buffers it. The network does its best. Each layer operates with limited awareness of the others’ constraints or priorities.
The codec does not know when the Wi-Fi link is about to degrade.
The network does not know the next frame carries a safety alert.
The player hopes the buffer is deep enough to hide the chaos.
This architecture was sufficient for a world of passive viewing. It is insufficient for a world of precision and mission-critical applications.
Coded Multisource Media Format (CMMF) represents a critical architectural pivot. Rather than treating delivery as a single fragile stream, it enables cooperative, multisource systems where media can be reconstructed from multiple paths simultaneously.
In plain terms, CMMF is an industry-standard container that enables robust, low-latency media streaming by allowing content to be delivered simultaneously from multiple network sources, like different CDNs or network paths. Instead of sending identical copies of the data, CMMF uses linear, network, or channel coding to split media into coded “symbols”. A client can then pull unique coded pieces from several locations and reassemble the original stream once enough pieces are collected. This approach increases reliability, improves throughput, and reduces rebuffering—without the inefficiency of storing full duplicate streams everywhere, making it ideal for modern multisource and multipath delivery architectures.
This is not about making one pipe bigger. It is about orchestrating multiple pipes intelligently.
Unlike basic connection bonding, multisource coding avoids redundant traffic while dramatically improving effective Network QoS. Wi-Fi and cellular links become a unified connectivity pool rather than mutually exclusive choices. The client assembles the experience from whichever paths are healthy at any given moment.
Physics remains hostile — but it is rarely hostile everywhere at once.
AI further amplifies this shift. Traditional streaming protocols are reactive by design. Quality drops after packets are lost. Buffers drain before adaptation begins. For real-time and immersive experiences, that response comes too late.
A cooperative system can observe conditions continuously, predict degradation, and adapt preemptively. Critical frames are rerouted before failure becomes visible. The experience does not stall or degrade — it simply continues.
The technology to do this exists today. The challenge now is not invention; it is adoption: moving cooperative delivery from standards and trials into repeatable, mass-market deployment.
Where Guarantees Matter — and Where They Don’t
Advocates of “good enough” media often argue that consumers will not pay for this level of precision. And for TikTok dance videos or Instagram streams watched on a bus, they are right.
But the growth engines of the next decade are not passive or disposable. They are high-consequence, real-time, and immersive experiences where failure is not a minor annoyance—it is a liability. These are the domains where guarantees become the product.
In the automotive cockpit, media becomes mixed-criticality. Entertainment and safety signals coexist on the same system. A collision warning cannot buffer behind a map update or a game download. Entertainment can degrade; safety cannot.
In live sports, latency is no longer a technical metric — it is a business metric. When fans learn about a touchdown from social media before seeing it on screen, value is destroyed. Determinism sells time.
In XR and spatial computing, the governing constraint is biological. Motion-to-photon latency and its variance determine whether an experience feels natural or induces nausea. There is no buffer in XR. Timing must be exact, every time.
Across these domains, the pattern is unmistakable. “Good enough” fails not because quality is too low, but because time is no longer negotiable. These are the markets where determinism moves from a technical aspiration to a commercial and experiential requirement—and where system-level cooperation becomes the only viable path forward.
Why Standards Decide Whether This Scales
Vertically integrated stacks can deliver exceptional experiences when one company controls the entire pipeline. That model works — but it does not scale across global ecosystems of creators, silicon vendors, OEMs, operators, and platforms.
History is clear: when industries hit a complexity wall, they standardize.
Wi-Fi did not achieve mass adoption through proprietary turbo modes. It scaled when interoperability became the baseline and innovation moved up the stack. Media delivery is approaching the same inflection point.
Deterministic, cooperative delivery cannot scale as a collection of proprietary silos. It requires shared assumptions, reference behavior, certification, and long-term stewardship. Standards turn fragile integrations into predictable markets. They allow creative intent and timing guarantees to survive the journey intact — regardless of who built each layer.
Without standards, cooperative delivery remains a premium feature. With standards, it becomes infrastructure.
Conclusion: The System Is the Product
The era of competing on cheaper bits is ending. The era of competing on guaranteed experience has begun.
Over the last decade, the industry rebuilt the nervous system — more deterministic networks, faster optics, better wireless. Now it must upgrade the signal itself.
The codec, the transport, and the player are no longer independent optimization problems. They are a single system, and they must be designed as one.
Value is migrating from components to architecture.
From efficiency to reliability.
From isolated optimization to cooperation.
The winners of the next era will not be those who compress bits most aggressively, but those who ensure experiences arrive intact, on time, and without compromise — even when the environment in between is hostile.

AI Didn’t Break Your Data Platform; It Exposed Your Data Debt
For the past two years, enterprise AI postmortems have sounded the same. A pilot stalls. Results look inconsistent. Trust erodes. The verdict follows quickly: the model is immature, the tools are unstable, the technology moved too fast.
That explanation is convenient. It is also wrong.
AI did not introduce fragility into enterprise data platforms. It exposed what was already there.Long before large models showed up, many platforms were held together by undocumented assumptions, fragile transformations, and ownership gaps everyone learned to work around. AI did not break those systems. It removed the ability to ignore their weaknesses.
What teams are facing is not an AI failure. It is a systems reckoning.
Data Debt Is Structural, Not Cosmetic
Data debt is often framed as bad quality or missing fields. That framing misses the point. The real debt is structural. It lives in pipelines no one fully owns, logic that exists only in people’s heads, and transformations that accumulated over years without a clear contract.
Traditional analytics could tolerate this. Dashboards aggregate. Reports smooth over inconsistencies. When something looks off, an analyst adjusts a filter or adds a footnote. Time absorbs the problem.
AI does not.
AI pipelines pull from multiple sources, assemble context, and produce outputs that appear authoritative. Every hidden assumption becomes an input. Every undocumented rule becomes a risk. Every unclear boundary becomes a debugging exercise with no obvious owner.
Consider a familiar enterprise pattern. A customer dimension evolves over a decade. Marketing owns part of it. Finance applies overrides. Operations enrich it downstream. No one owns it end to end. Queries reference it through layers of views. The system works because people know where it breaks.
Introduce an AI system that needs customer context in near real time. The cracks surface immediately. Conflicting attributes. Missing lineage. Output shifts no one can explain. The AI did not create the inconsistency. It forced it into the open.
This matters because AI compresses feedback loops. Issues that once took quarters to surface now appear in days. What used to be background noise becomes a blocking problem. Debt that was once survivable becomes operationally expensive.
This is a well-understood pattern in data platform maturity discussions: when assumptions aren’t explicit, systems fail under new latency, reliability, and trust requirements.
Lineage and Ownership = Operational Requirements
Trust is the currency of AI systems. Without it, outputs are questioned, bypassed, or quietly ignored. Trust does not come from model accuracy alone. It comes from traceability.
When an AI output is challenged, the first question is rarely about hyperparameters. It is about provenance. Where did this data come from. Why does it say this. What changed since yesterday.
Lineage answers those questions. Ownership makes the answers actionable.
This is not about governance theater or compliance checklists. It is about operational clarity. Who owns this dataset? What assumptions does it encode? Who signs off when it changes?
This is also where many enterprise AI efforts stall: trust breaks when teams can’t answer provenance questions consistently.
In practice, that means contracts, tests, and change management around critical datasets—not just documentation.
Dashboards could survive ambiguity because they were passive. AI systems are not. They summarize, recommend, and influence decisions in real time. That shift raises the bar.
A report could be wrong for weeks with limited impact. An AI recommendation can trigger action immediately. Confidence must extend beyond the output to the system that produced it.
Many platforms struggle here because clarity was deferred. Storage scaled. Compute scaled. Understanding did not. The result is a technically impressive platform that no one can fully explain. AI makes that state unsustainable.
Teams that treat lineage and ownership as first-class concerns move faster, not slower. They spend less time debating what the system is doing and more time improving it.
Cost Blowups Reveal Design Gaps
Another common complaint about AI is cost. Training runs are expensive. Inference adds up. Storage grows faster than planned. Budgets get burned.
The instinct is to blame the workload. The reality is less flattering.
AI workloads punish inefficiency. They amplify waste that already existed. Redundant datasets, unnecessary joins, over-retained history, and poorly scoped transformations were tolerable when they powered nightly reports. They become ruinous when they sit on the critical path of AI systems.
Poor data hygiene leads to runaway cost because the platform does more work than it needs to. It processes data that should have been archived. It enriches context that is never used. It recomputes logic that should have been materialized once.
Cost control is an architectural outcome, not a finance exercise. When engineers understand data flows end to end, they can design for efficiency. When they do not, cost becomes an external constraint imposed after the fact.
This is why cost governance has moved upstream into engineering practice: measure unit costs, instrument pipelines, and design to avoid waste.
Teams that scale AI treat efficiency as a design requirement. They ask hard questions early. What data is actually needed. What freshness is justified. What assumptions can be encoded once instead of recalculated repeatedly. That discipline pays off well beyond AI use cases.
The Counterargument, Taken Seriously
A common objection is that AI itself is too unstable for enterprise use. Models evolve. Outputs vary. The pace of change makes durable systems impossible.
There is truth here, but it is incomplete.
Teams with disciplined data foundations are scaling AI today. They are not chasing every new capability. They focus on reliability, clarity, and ownership. When models change, they adapt because their data layer is not a black box.
The difference is not talent or tooling. It is systems thinking. Organizations that treat data platforms as long-lived products rather than one-time projects have fewer surprises. They know what they own and where it breaks. AI becomes an extension of the platform, not a threat to it.
Blaming AI immaturity avoids a harder conversation. It is easier to say the technology is not ready than to admit the platform was never as solid as assumed.
Conclusion
AI did not break enterprise data platforms. It told the truth about them.
For years, many organizations optimized for output over understanding. They shipped faster than they documented. They scaled storage before ownership. They accepted ambiguity because it was convenient. AI removes that option.
This is not a failure story. It is an opportunity. AI acts as a forcing function that pushes data platforms toward maturity. It rewards clarity and penalizes shortcuts. It turns invisible debt into visible risk.
The path forward is not to pause AI adoption. It is to take data platforms seriously as long-term systems. Invest in ownership. Make lineage explicit. Design for efficiency. Treat context as infrastructure.
Teams that do this will find that AI does not destabilize their platforms. It strengthens them.

How Hedgehog Brings Hyperscaler Networking to Enterprise AI
Hedgehog CEO Marc Austin joins Data Insights to break down open-source, automated networking for AI clusters—cutting cost, avoiding lock-in, and keeping GPUs fed from training to inference.
.webp)
The Echo of Wi-Fi: Why the Optics Industry Feels Like Déjà Vu
There was a time in the late ‘90s when the first dot-com boom was underway, mobile phones were going mainstream, and personal computers were finally becoming portable. But the internet was still a physical destination. It was a place you went to, a connected desktop in a home, office, or internet café, not a parallel universe you could access on the go.
I started my career in the trenches, developing some of the industry’s first 802.11 (Wi-Fi) transceivers. Looking back, Wi-Fi wasn’t so much a technology breakthrough as it was an inevitable response to a shift in human behavior. We wanted to communicate. We wanted access to the riches of the internet. We wanted our computers. And we wanted them with us, all the time.
It was a chaotic, fragmented, loud and wildly innovative time. We had proprietary “Turbo Modes,” one-upmanship, conflicting standards, and dozens of startups and few “grown up” companies, claiming they owned the future. But eventually, and rapidly, an ecosystem developed that transformed Wi-Fi from a novelty into an essential utility, sitting beside water and electricity, within 20 years. There was an explosive catalyst, a gold rush, and an eventual consolidation around standards.
Today, as I watch the optics industry in 2026, I can’t help but feel the same electric hum in the air. The same fragmentation. The same confusion. The same catalytic force. The same gold-rush energy. The same inevitability that something is about to happen, must happen, to enable the latest seismic shift in human behavior.
If you squint your eyes, it almost looks like 2003 all over again…
When the Wi-Fi Ecosystem Learned to Grow the Pie Together
What’s often forgotten about early Wi-Fi is that its success was not inevitable. Wireless is a shared medium. There is no such thing as a private RF universe. Interference, broken roaming, competing beam forming mechanisms, and failed interoperability didn’t just hurt competitors, it damaged customer trust in the entire category. If Wi-Fi was unreliable, it wouldn’t matter who had the fastest radio. The market itself would be dead on arrival.
That realization changed behavior. Through a few painful stumbles, the industry learned that there had to be a common baseline, a set of rules everyone followed, to keep the air clean and the experience predictable. Differentiation still mattered, but it had to be built on top of a shared foundation, not at its expense.
Competitors worked together. Standards bodies matured. Interoperability test beds emerged. Certification programs enforced compliance and guardrails. Vendors argued fiercely, but within boundaries that preserved the viability of the ecosystem. It wasn’t altruism. It was survival. Grow the pie first, then fight like hell for your share of it.
This ecosystem balance only worked because the cast of characters was diverse, and complementary. There were large, established players acting as the adults in the room, setting expectations around enterprise reliability, security, and scale. There were aggressive startups injecting energy, new ideas, and technical breakthroughs that pushed the state of the art forward. And there was Intel.
Intel wanted to make mobile computing inevitable. Creating a new, fast-growing category for higher-margin mobile processors was simply good business. But Intel did something unprecedented: it put its own balance sheet behind the ecosystem. A $300 million Centrino marketing campaign, unheard of at the time, made Wi-Fi synonymous with mobility, reliability, and interoperability. It was a spark that turned momentum into a conflagration.
Intel wasn’t alone. Cisco built enterprise-grade wireless networks that IT could trust. Microsoft pulled wireless deep into the operating system, normalizing it for developers and users alike. Dell and other OEMs made Wi-Fi table stakes in mobile computing. The ecosystem had champions. It had shepherds. And it had plenty of unruly sheep. Together, that unlikely combination produced one of the most successful infrastructure transitions in modern technology history.
Wi-Fi didn’t win because one company dominated early. It won because enough powerful players decided, independently, and selfishly, that growing the pie together mattered more than grabbing the biggest slice first.
When Optics Stopped Being Predictable Plumbing
For a long time, optics was boring, in the best possible way. Optical networking was reliable, predictable, and largely invisible. Bandwidth increased on a steady cadence. Power budgets were understood. Distances were fixed. Traffic patterns were well behaved. As long as you followed the playbook, the system worked.
10G became 25G became 40G became 100G became 400G. Roadmaps were clear. Margins were thin but stable. Optics was foundational, but rarely strategic.
Then AI broke the playbook.
The rise of large language models, agentic systems, and massive multi-modal workloads are driving an insatiable demand for compute, that simply does not fit inside traditional data center assumptions. Training and inference push processing density, east–west bandwidth, and latency sensitivity into entirely uncharted territory.
Clusters no longer scale in a single dimension. They scale up, packing more compute into a rack. They scale out, spreading workloads across rows and halls. And increasingly, they scale across, connecting multiple data centers into a single logical system.
At each step, the network had to keep pace. Exceptionally expensive GPUs cannot sit idle waiting for data. As clusters stretch across racks, buildings, and campuses, the network stops being a background transport and becomes a gating factor for utilization, determinism, and overall system efficiency.
Then the industry hit a power wall.
The constraint is no longer real estate or fiber, it is megawatts. New data centers are being built where power is available, not where latency is optimal and convenient. And that power constraint applies to everything: compute, switching, cooling, and optics alike.
The result is a mandate optics has never faced before, and must now satisfy simultaneously:
1. Dramatically increase compute scale.
2. Deliver higher speed and tighter determinism so GPUs never wait.
3. Reduce power consumption per bit, per port, per rack, per data center.
That combination changes optics from predictable plumbing into a first-order architectural constraint.
Copper interconnects, once “good enough,” are becoming a barrier at scale. Signal integrity, power loss, and reach limits are no longer theoretical, they are operational. Co-packaged optics, long discussed in labs and roadmaps, are now moving into real deployments, bringing optics closer to switch silicon and reducing copper distances and power consumption. Pluggable optics no longer monopolize the design space. Optical switching is re-emerging not as an experiment, but as a necessity.
In this world, optics stops being plumbing. It becomes both the limiting factor and the enabling force of AI infrastructure.
The Return of Chaos (and Opportunity)
Just like early Wi-Fi, this shift triggers a burst of simultaneous, multi-vector innovation.
Startups attack every layer at once: new modulation schemes, novel laser technologies, co-packaged optics, disaggregated control planes, fiber automation, thermal management, and power-aware networking. Incumbents are forced to re-architect product lines that were stable for a decade. Conferences fill with competing visions, overlapping claims, and incompatible approaches.
It feels chaotic. Because it is. But once again, chaos is not a failure mode, it is a signal that the industry is very much alive.
And once again, chaos requires gravity. In the AI era, NVIDIA plays the role Intel once did. Again, not out of altruism, but out of self-interest. NVIDIA’s GPUs, interconnect requirements, and system architectures now define the shape of modern AI clusters. Their need for scale, efficiency, and determinism forces the entire optical ecosystem to evolve faster than it otherwise would. Like Intel with Centrino, NVIDIA is pushing the levers that expand the market, because doing so directly expands its own opportunity.
The hyperscalers are doing the same. Meta, Google, Microsoft, Amazon, and others are committing tens of billions of dollars to build AI infrastructure capable of supporting agentic workloads at planetary scale. They are willing to fund new architectures, absorb early inefficiencies, and accept real risk to break through existing limits.
Why the Optics Landscape Feels So Familiar
If this all feels strangely familiar, it should.
Fragmentation? Check. The optics industry today looks a lot like Wi-Fi did in the early 2000s; fragmented, noisy, and bursting with parallel innovation. Dozens of companies are attacking adjacent problems simultaneously: DSPs, lasers, co-packaged optics, thermal management, fiber automation, disaggregated control planes. No single approach has emerged as “the” answer, and that uncertainty is driving experimentation in every direction at once.
Intellectual chaos? Check. The intellectual chaos is unmistakable. Conferences are filled with competing visions and overlapping claims, with multiple companies promising order-of-magnitude breakthroughs through fundamentally different architectures. Wi-Fi went through the same debates, MIMO, MU-MIMO, interference with incumbent RF systems, number of streams, multiple versions of beamforming, proprietary turbo modes vs standards. None of those questions had clean answers at the time, and optics is no different today.
Massive funding inflows? Check. A gravitational pull toward consolidation? Absolutely.
Capital is flowing freely, another familiar signal. Investors and operators alike sense that optics is no longer incremental plumbing; it’s a breakout category with strategic importance. That gravitational pull inevitably leads toward consolidation. We saw this clearly with Marvell’s recent acquisition of Celestial.ai, a move that signals the era of standalone components is ending. Just as Wi-Fi eventually centered around a small number of dominant silicon platforms, optics will likely converge around a handful of dominant players who can integrate those disjointed innovations into a platform.
And most importantly: a forcing function? YES! Wi-Fi needed to cut the wire, then work in dense deployments, then enable low-power IoT, and now act more deterministically to power our agentic future.
Optics needs to make AI scale physically possible; within switches, across racks, across data centers, without collapsing the grid that feeds it.
When a market has a forcing function, it must evolve. There is no choice.
What Wi-Fi Can Teach Optics About the Road Ahead
We’ve seen this movie before, and Wi-Fi left behind a few hard-earned lessons that optics would be wise to absorb.
Lesson 1: Standards and Interoperability always win — even when it's messy.
Never bet against Ethernet and never bet against Wi-Fi. Proprietary performance advantages are tempting early on, but shared infrastructure lives or dies by common language. Great compromises in the days of 802.11g and 802.11n brought the industry together and left proprietary turbo modes as window dressing for the retail market. Coopetition flourished and the winners were those who embraced it. Optics will face the same tradeoffs, and the ecosystems that prioritize interoperability early will ultimately outlast those that don’t.
Lesson 2: The market rewards companies that grow the pie.
Intel didn’t sell access point silicon. Microsoft didn’t sell radios. Dell didn’t care which chipset won; they bought from everyone. What they all cared about was expanding the market itself. Their success came from making Wi-Fi inevitable, not exclusive. Optics needs its own version of that mindset.
Lesson 3: Simplification beats elegance.
Wi-Fi became ubiquitous not because it solved the RF problem perfectly, but because it made the technology easy for millions of people to deploy. Optics is approaching a similar inflection point. Operators aren’t asking for more clever architectures; they’re asking how to deploy across dozens of data centers, manage thermal and power budgets, automate fiber paths with fewer humans in the loop. Elegance helps, but simplification wins.
Lesson 4: The winners are ecosystem players.
The most successful Wi-Fi companies didn’t just ship chips; they built platforms. Reference designs, SDKs, certification programs, developer ecosystems, and trusted brands mattered as much as raw performance. Optics now has the same opportunity, but only if the industry thinks beyond feeds, speeds, and component optimization.
Where Optics Goes From Here
If the analogy holds, and I believe it does, then optics is entering a decade defined by startup energy, vendor consolidation, architectural standardization, and deep vertical integration. Complexity will be abstracted away. New platforms will emerge. The conversation will shift from components to systems, and eventually to experiences.
The companies that win won’t just be the fastest or the most clever. They’ll be the ones that make optics predictable, operable, and trustworthy at scale. They’ll lean into interoperability before the market forces it. They’ll treat power, cooling, and fiber as software problems. They’ll partner with kingmakers rather than trying to outmuscle them.
And most importantly, they won’t try to own the whole pie. They’ll grow it.
Because every major networking revolution, Ethernet, Wi-Fi, cloud, and now AI fabrics, follows the same arc: breakthrough, fragmentation, chaos, consolidation, and ubiquity. Optics is squarely in the fragmentation and chaos phase.
That’s not a bug. It’s the signal that the industry is alive again.
Conclusion: The Déjà Vu Is Real
When I sit in modern AI datacenters and look at the optical racks, I feel the same thing I felt holding a pre-standard 802.11g PCMCIA card in 2002:
“We don’t fully know what we’re building yet, but when we do, it will reshape the entire industry.”
Wi-Fi unlocked mobility. Optics will unlock AI at scale. And just like Wi-Fi, the winners won’t be the ones who optimize a component in isolation. They’ll be the ones who understand that ecosystems, not components, determine the future.

GlobalFoundries to Acquire Synopsys ARC Processor IP Business
In a move that signals a significant restructuring of the semiconductor IP landscape, Synopsys and GlobalFoundries (GF) today announced a definitive agreement for GF to acquire Synopsys’ Processor IP Solutions business. The deal, which includes the ARC processor family and related software development tools, marks a pivotal moment for both companies as they sharpen their focus on the burgeoning Physical AI opportunity.
The transaction, expected to close in the second half of calendar year 2026, will see Synopsys’ Processor IP portfolio—ARC-V™ (RISC-V) and ARC® CPU IP, DSP IP, Neural Network Processing Unit (NPU) IP, and related software development tools including ARC MetaWare Development Toolkits—move into the GlobalFoundries ecosystem. The transaction also includes Synopsys’ ASIP Designer™ and ASIP Programmer™ tools for automating the design and implementation of application-specific instruction-set processors (ASIPs).
GF’s announcement also calls out the included ARC product lines as ARC-V, ARC-Classic, ARC VPX-DSP, and ARC NPX NPU, and says that upon closing, these assets and expert teams will be integrated with MIPS, a GlobalFoundries company.
Synopsys: Shedding the Cores to Focus on the “Plumbing” of AI
For Synopsys, the divestiture looks like disciplined portfolio management. By offloading its processor business, Synopsys is doubling down on its leadership in interface and foundation IP.
“We are focusing our IP resources and roadmap to further our leadership in essential interface and foundation IP while winning new, high-value opportunities that advance our position as the leading provider of engineering solutions from silicon to systems,” said Sassine Ghazi, president and CEO of Synopsys.
This focus is more than just marketing speak. As AI chips become increasingly complex, the bottleneck is rarely the processor core alone; it’s the high-speed connectivity (PCIe, CXL, DDR) and the fundamental logic libraries that enable multi-die/chiplet architectures. Synopsys is positioning itself to be the indispensable provider of the “connective tissue” that powers AI from the cloud to the edge, while continuing to dominate the EDA software market where they optimize implementations for all processor ecosystems.
GlobalFoundries: Moving Up the Value Chain
For GlobalFoundries, this acquisition is an aggressive step toward becoming a platform provider rather than a pure-play foundry. By acquiring ARC and integrating it with MIPS, GF is building a more complete “Physical AI” stack.
Physical AI refers to the deployment of AI in the tangible world—wearables, robotics, automotive, and industrial IoT—where power efficiency and custom silicon are paramount. By owning the processor IP, GF can offer its customers more tightly integrated, end-to-end solutions, lowering the barrier to entry for companies that want to move quickly from concept to high-volume manufacturing.
“This acquisition doubles down on our commitment to advancing our leadership in Physical AI,” noted Tim Breen, CEO of GlobalFoundries. “By combining Synopsys’ ARC IP and MIPS technologies with GF’s advanced manufacturing capabilities, we are lowering the barrier for customer adoption.”
Transaction Details and Timeline
Assets transferred: The Synopsys Processor IP portfolio includes ARC-V™ (RISC-V) and ARC® CPU IP, DSP IP, NPU IP, related software development tools including ARC MetaWare Development Toolkits, plus ASIP Designer™ and ASIP Programmer™. GF additionally describes the included ARC product lines as ARC-V, ARC-Classic, ARC VPX-DSP, and ARC NPX NPU.
- Impact on Synopsys: Synopsys says the transaction is not material to its business and that terms are not being disclosed.
- Closure: Anticipated in the second half of calendar year 2026, subject to customary closing conditions including regulatory approvals.
- Continuity: Synopsys will retain and continue to grow its design IP portfolio spanning logic libraries, embedded memories, interface IP, security IP, and subsystems.
- Continuity for customers: Synopsys and GF say they will work together to ensure Processor IP customers are supported through the transition without disruption.
TechArena Take
The divestiture of Synopsys’ Processor IP Solutions business fits the pattern of the “New Synopsys” story arc: a company increasingly defining itself as an engineering-solutions platform from silicon to systems, especially after Synopsys completed its acquisition of Ansys in July 2025.
Layer on the NVIDIA partnership news from December 1, 2025—where NVIDIA announced an expanded strategic partnership with Synopsys and disclosed a $2 billion investment in Synopsys common stock (at a stated purchase price of $414.79 per share)—and the strategic emphasis on simulation, digital twins, and AI-accelerated engineering workflows becomes even clearer.
For GF, this is a “Foundry 2.0” play. In a world where specialized AI silicon is the new gold, being “just” a manufacturer isn’t enough. By owning the IP (ARC and MIPS) and packaging it with software tools, GF is positioning itself to deliver more “foundry-ready” platforms—particularly for physical AI use cases where power, latency, and tight integration matter.
The industry is watching closely. This deal consolidates ARC and MIPS under one roof. If GF can successfully integrate these teams and maintain the neutrality required to keep ARC customers comfortable through the transition, it will have carved out a serious niche in the Physical AI era.

AI Is Squeezing Storage Supply—and VAST Wants Your Flash
Over the past several weeks, escalating AI storage demand and lack of supply has begun to dominate tech headlines.
Industry coverage has pointed to enterprise HDD supply tightening sharply—Tom’s Hardware recently reported enterprise drives can be on backorder for up to two years, and it also noted HDD prices rose about 4% in Q4 2025, the biggest increase in eight quarters. Reuters reported in early December that AI-driven demand is contributing to a broader memory supply crunch, with manufacturers prioritizing higher-margin products and customers scrambling for allocation.
At the same time, the NAND market is flashing its own warning lights. TrendForce forecast that NAND Flash contract prices could rise 33–38% quarter-over-quarter in Q1 2026 as memory makers prioritize server and AI-related demand. And on the supplier side, Tom’s Hardware reported (citing Nomura) that SanDisk is expected to raise enterprise 3D NAND pricing for SSDs aggressively in Q1 2026—potentially more than doubling in some cases—tying the move to AI-driven storage demand and near-term supply pressure.
That backdrop matters for news out of VAST Data this week. In a briefing, the company framed the shortage as a market inflection point—and introduced a Flash Reclamation Program designed to repurpose NVMe SSDs already sitting inside customer environments, alongside a broader push around inference key-value (KV) cache persistence aligned with NVIDIA’s Inference Context Memory Storage (ICMS) platform direction.
In the briefing, VAST co-founder Jeff Denworth positioned the company as a meaningful consumer of enterprise flash via customer deployments, and framed the market as facing compounding constraints: HDD shortfalls pushing more demand into enterprise SSDs (especially QLC), plus a fresh wave of AI infrastructure requirements.
VAST’s Two Headline Moves
VAST says it will launch a Flash Reclamation Program designed to repurpose NVMe SSDs already sitting inside customer estates—including drives currently deployed behind other platforms—so customers can stretch existing media rather than wait on new allocations. In the Q&A, VAST was explicit that this can mean pulling SSDs from existing systems and redeploying them under VAST after rapid qualification.
Second, VAST argued that inference is about to generate a new class of storage demand as context moves from GPU memory into shared NVMe tiers, enabling faster reuse of prior context for long, multi-session workloads.
That second point maps closely to NVIDIA’s own platform messaging. NVIDIA has described ICMS as a BlueField-4-powered approach intended to extend inference context memory for multi-turn agentic AI and to support high-bandwidth sharing of KV cache across systems.
Meanwhile, the “HDD delays → more flash demand” narrative continues to circulate in the channel, with DigiTimes-linked reporting (and follow-on coverage) describing extended enterprise HDD lead times and increased interest in QLC alternatives.
TechArena Take
VAST’s messaging lands because it’s not trying to create a problem—it’s trying to name one that independent sources are already surfacing.
The most revealing part isn’t the performance claims. It’s the go-to-market posture. A “reclaim the flash you already own” program is a shortage-era motion: it assumes constrained allocation, long lead times, and customers willing to tolerate disruption to free up scarce media.
On the AI side, KV cache is quickly becoming the next battleground for storage architecture narratives. NVIDIA’s ICMS framing makes KV cache persistence feel inevitable for long-context, multi-turn agents, and it creates a new category of “storage that behaves like memory.” VAST is positioning itself as the software and data-services layer around that shift—where efficiency, protection, and lifecycle controls become part of the ICMS-era value prop, not an afterthought.
In other words: the shortage story is bigger than VAST, but VAST’s response is a useful signal. When infrastructure vendors start building programs around reuse and reclamation—not just new boxes—it’s a sign the market expects constraints to persist, not clear up in a quarter.

The Nervous System of AI: Why the “Best Effort” Era is Over
I remember the early days of Wi-Fi, developing some of the industry’s first 802.11a/b/g transceivers. Back then, the mission was singular and remarkably simple: cut the wire.
Wireless has always evolved around its biggest pain point. First speed, then density, then IoT. Every era shifts when a new problem becomes the one we can’t ignore.
In the early years, the entire industry was engaged in a breathless race to make the air look like Ethernet. We obsessed over modulation schemes and channel widths, fighting physics to push throughput from 2 Mbps to 11 Mbps to 54 Mbps, and eventually toward Gigabit performance. Companies stacked on proprietary “Turbo Modes” and pre-standard features to squeeze out every bit and position themselves competitively.
And we won. The speed gap closed. Wi-Fi didn’t just catch wired performance at the residential edge and the enterprise edge — in many places it surpassed it.
Once raw throughput was “good enough,” the priority shifted. We moved from chasing speed to chasing density:
Can we make this work in a packed stadium?
On a subway platform in Tokyo?
In a high-rise where 200 access points sit next to and on top of one another?
That era led us to borrow techniques from cellular: OFDMA, MU-MIMO, BSS Coloring — tools to solve the wireless “cocktail party problem,” the RF equivalent of a noisy room where many devices speak at once and the network must separate overlapping conversations.
Then came the third wave: the Internet of Things. Suddenly, the devices connecting to our networks weren’t just laptops and phones; they were sensors, cameras, thermostats, wearables, industrial controllers, and all kinds of headless endpoints no one wants to update until it’s too late. The number of “things” began to outpace the number of people.
We realized that hauling all that data back to the cloud was often wasteful, so we started pushing compute outward — toward gateways, access points, and edge nodes — processing data closer to where it was created. The mindset shifted from performance to outcomes. Sensor networks don’t require much bandwidth, and no one cares what protocol they are using; they care about how the data is being used to make their lives better.
Today, we are hitting a new inflection point — one that makes the previous shifts look incremental.
In many enterprise environments, human client growth is no longer the main scaling driver. The next explosion in networking isn’t coming from people watching Netflix or scrolling Instagram. It is coming from autonomous agents. And unlike people, AI agents do not forgive “best effort.”
To see why, imagine a modern fulfillment center. Not humans pushing carts, but a hive of hundreds of Autonomous Mobile Robots weaving past each other at speed. Each robot negotiates right-of-way with a central controller, with safety systems watching for conflicts — a single distributed organism connected by an invisible wireless tether.
If that tether stretches into a noticeable hiccup — tens of milliseconds in the wrong moment — the system doesn’t “buffer.” It stops. A momentary disruption becomes a full-aisle shutdown. This is where “best effort” becomes a business risk rather than a minor annoyance.
The New Consumer: Human vs. Machine
To understand why the network architecture must change, you have to understand the difference between a human user and an AI agent.
Humans are incredibly adaptive. If you are on a Teams call and the video freezes for 500 milliseconds, you might grimace and cry out to your deity of choice, but your brain fills in the gap. If a web page takes an extra second to load, you wait. We are built to tolerate variance. Our networks were designed around this tolerance; we built best-effort systems that prioritized maximum throughput over consistent timing.
AI agents (robots, autonomous logistics bots, digital twins, and XR interfaces) are not adaptive in the same way. They require precision.
If a warehouse robot loses reliable connectivity at the wrong moment, it doesn’t “buffer”; it performs a safety stop. If an XR experience slips into noticeable lag, the user gets disoriented, or nauseous (“clean up on aisle 3”). These “users” don’t care about peak speed. To an AI agent, performance isn’t measured in gigabits per second; it’s measured in bounded variance.
Determinism means engineering to strict upper bounds on latency, jitter, and packet loss, and then meeting those bounds every time. “Good” is no longer a high average throughput. “Good” is the mathematical guarantee that 99.9999% of packets will arrive within a fixed window (e.g., 10 ms), regardless of RF congestion, multipath, or compute/buffer delay.
We are moving from an era of bandwidth to an era of determinism.
Wireless as the AI Nervous System
If the modern data center — with its massive GPU clusters — is the brain of the AI revolution, the wireless edge is the nervous system.
A brain in a jar is useless. To function, intelligence needs sensory input from the physical world. It needs to know who is in the room, where the asset is, what the environmental context is, and what the expected action (intent) will be.
This is the new mandate for the wireless edge. We must pivot from building “dumb pipes” that simply move data to building a sensory fabric that feeds context and intent to the enterprise AI.
This shift requires three fundamental architectural changes.
- Determinism over throughput
We need to stop marketing “fast” and start engineering “predictable.” The industry is acknowledging this reality, and Wi-Fi 8 is shaping up to emphasize ultra-high reliability in hostile RF environments, not just another massive jump in peak PHY rate.
This is a tacit admission that the race for raw speed is no longer the primary battle. The future of wireless lies in scheduling the air with the same seriousness we apply to wired switching: prioritization, admission control, traffic classification, roaming behavior that doesn’t spike tail latency, and continuous measurement of what the network is actually delivering.
Whether via private 5G or reliability-focused Wi-Fi evolution, the network must support SLA-like behavior for latency-sensitive machine traffic. For network designers, this flips the planning model: instead of asking “How fast can we make it?” we now ask “What is the worst-case delay this robot, vehicle, or agent can survive?” Determinism becomes the budget we engineer around.
- Identity as the control plane
In a world of autonomous agents, the distinction between “Wi-Fi” and “cellular” is often a distraction. The agent doesn’t care about the protocol; it cares about the outcome. We need a unified identity layer that can abstract away the radio physics.
A security robot moving from the parking lot (5G) into a warehouse (Wi-Fi) shouldn’t experience a policy gap. The policy must follow the identity, not the port.
In practice, this means policies can no longer live primarily in VLANs or subnets. They must live with the identity itself — tied to a device, workload, or agent — and remain consistent as it roams across spectrum, transport, topology, and physical location.
- The network as an immune system (distributed zero trust)
When humans click on phishing links, we train them to be better. You cannot “train” an infected thermostat or a compromised sensor. As we flood our networks with headless devices, the attack surface expands exponentially.
Security can no longer be a perimeter overlay; it must be intrinsic to the fabric. In this model, the chain of trust starts at the edge. The access point stops being a passive pipe and becomes an enforcement point: identity-based segmentation, continuous verification, and rapid containment at the first hop.
Architecturally, the edge is no longer a passive on-ramp; it is the first line of defense that can shrink blast radius immediately and feed high-fidelity telemetry into centralized policy and response.
The Opportunity
We spent the last 20 years building networks that were excellent at delivering content to people. The next 20 years will be about building networks that deliver context from the physical world to AI models.
This is not just an upgrade cycle. It is a fundamental reimagining of why we build networks in the first place. The edge is no longer just about connectivity. It is the sensory interface for the AI era.
If you’re a network or infrastructure leader looking at this shift, the key question isn’t “how fast can the wireless network go?” The question is: can we support real-time, deterministic applications? Can we make policy follow identity across domains? Can we contain threats where they originate, not after they spread?
The technology to build this exists today. The “things” are already here. The agents are waking up.
We are done designing for human patience. Now, we must build the nervous system for machine precision. The 'Best Effort' era is over. The Deterministic era has begun.

How Rose-Hulman Modernized Its Data Center for Student Success
Rose-Hulman Institute of Technology shares how Azure Local, AVD, and GPU-powered infrastructure are transforming IT operations and enabling device-agnostic access to high-performance engineering software.

Synopsys Aims to Make SDV Journey Cheaper, Faster, Less Risky
At CES 2026, Synopsys is staking out a bigger role in automotive: not just enabling chip design or running point simulations, but virtualizing the end-to-end engineering workflow that software-defined vehicles (SDVs) require.
The timing is not subtle. Automotive teams are being asked to ship platform-like experiences on hardware that can’t behave like a smartphone supply chain. Electrification is rewriting architectures, autonomy is raising the bar on validation, and customers now expect the in-vehicle experience to improve after purchase via connected services and over-the-air updates. Synopsys puts a fine point on the economic pressure: profitability is increasingly driven by software, and traditional design-to-cost metrics can’t keep up with the scale of change.
What makes this announcement worth paying attention to is that Synopsys is framing virtualization as a business survival lever, not a technical preference. In the company’s telling, virtualizing vehicle electronics for design, integration, testing, and validation can reduce costs by 20–60% and accelerate time-to-market.
And that message lands differently given Synopsys’ evolving position in the ecosystem. The company is now integrating Ansys (deal completion was reported in July 2025) at a time when physics-based simulation and system-level verification are moving from “later stage” to “make-or-break early stage” in automotive programs. It’s also fresh off an expanded partnership with NVIDIA that included a $2B NVIDIA investment in Synopsys common stock, explicitly tied to AI and accelerated computing for engineering and design workflows.
In other words: Synopsys is building the narrative that the SDV era will be won by whoever can industrialize engineering itself.
The CES 2026 Message: Shift-Left Becomes the Default
Synopsys’ CES announcement opens with a clear premise: the industry’s biggest challenge is accelerating innovation “in the age of AI” while reducing cost and complexity. Then it repeats a theme we’re hearing more broadly across the SDV stack: virtualization needs to move left, earlier than it traditionally has, because late-stage validation is too slow and too expensive when the vehicle is becoming a continuously updated software platform.
Synopsys is also explicit about where it wants to sit: across “systems to silicon,” from system-level simulation to semiconductor design, enabling automakers and suppliers to virtualize silicon and software development, predict system performance, and optimize reliability.
The company anchors that strategy in three highlight areas.
1) Safety as a simulation workflow, not just a standard
Synopsys says it will support the Fédération Internationale de l’Automobile (FIA) to enhance single-seater safety standards, using design optimization and “predictively accurate digital human body models” to process thousands of parameters.
This matters beyond motorsport because it reflects a broader trend: safety requirements are expanding, and the industry needs high-fidelity methods that can scale. The old approach of iterating toward safety through physical testing alone is increasingly mismatched to compressed timelines and rising system complexity. Synopsys is positioning high-fidelity modeling and multiphysics simulation as the path to “more trials earlier,” not “more prototypes later.”
2) Sensor simulation moves closer to “real-world” conditions
The second highlight is the integration of Samsung’s ISOCELL Auto 1H1 automotive image sensor into Ansys AVxcelerate Sensors, enabling high-fidelity simulation under “real-life conditions” early in the design cycle, without hardware.
This is a concrete example of what “shift left” looks like when autonomy and ADAS are part of the vehicle’s value proposition. If your perception stack is built on sensors whose behavior changes across conditions (lighting, weather, motion blur, glare, temperature), pushing realistic modeling earlier can reduce the number of expensive, late-cycle surprises. It also enables software teams to work against something closer to real sensor characteristics well before hardware integration is stable.
In the news announcement, Samsung frames this as letting OEMs “virtually experience real-world driving conditions” with predictive accuracy long before hardware integration.
3) The biggest SDV lever: pre-silicon software and electronics digital twins
Perhaps the most strategically important part of the announcement is Synopsys’ continued push around virtualization for electronics digital twins, anchored by Virtualizer Developer Kits (VDKs). Synopsys claims engineers can begin software development months before silicon is available, achieve system bring-up within days of silicon availability, and accelerate vehicle time-to-market by up to 12 months.
That claim is one of those “up to” statements that always deserves interrogation. But even if the median value is smaller, the direction is the point: in SDV programs, schedule risk often concentrates at integration, and integration risk often concentrates at the intersection of software, silicon, and systems. Anything that pulls integration and validation forward can change program math.
Synopsys also ties this directly to continuous updates: the Arm-focused VDK is positioned as supporting multi-ECU, multi-vendor integration and CI/CD pipelines “for continuous updates throughout the vehicle lifecycle.”
From Tools to Ecosystems: Why the Partner List Matters
On the virtualization side, Synopsys calls out several partner-driven demonstrations and integrations:
Arm: Synopsys introduced a new VDK for Arm Zena Compute Subsystems, described as a standardized, safety-capable compute platform that can be used on-prem or in the cloud. Synopsys says this VDK provides a SOAFEE blueprint showcasing the OpenAD autonomous driving stack as a reference implementation.
IPG Automotive: Synopsys and IPG are demonstrating a multi-ECU prototype that integrates IPG CarMaker and Synopsys virtualization technologies via SIL Kit, with an explicit goal of establishing a continuous test strategy to improve software quality and reduce post-sale warranty costs.
SiMa.ai: Synopsys points to an integrated capability as part of a strategic collaboration, positioned as a blueprint for early virtual software development for AI-ready automotive SoCs used in ADAS and in-vehicle infotainment.
Then the company goes even more directly at the silicon platform layer:
NXP: Synopsys says it is expanding collaboration around VDKs supporting NXP’s new S32N7 family of high-performance computers for AI-powered vehicle cores.
Texas Instruments: Synopsys says TI is collaborating with Synopsys to provide a VDK for the TDA5 SoC family, enabling electronics digital twin capabilities that help engineers significantly accelerate time-to-market for SDVs. Synopsys says its Virtualizer VDKs can accelerate vehicle time-to-market by up to 12 months.
This partner list is telling because it mirrors the reality of SDVs: no OEM “controls” the full stack anymore. The hard problem is not deciding that SDVs are the future. The hard problem is getting suppliers, silicon vendors, tool providers, and software platforms to move with enough coherence that programs don’t stall at integration.
Synopsys is saying: we can be the connective tissue.
The bigger context: SDVs are forcing unlikely alliances
If you zoom out, the story here isn’t “Synopsys announced VDKs.” The story is that the SDV transition is pushing incumbents into uncomfortable collaboration — and also into fragmentation.
Robert Bielby captured this tension perfectly in a recent Voices of Innovation article, The Lamb Lays Down with the Lion to Avoid Being Eaten by the Wolf. He describes European OEM competitors collaborating on an open-source shared software platform for EVs as a response to competitive pressure from China’s EV momentum, while warning that these alliances are hard to sustain because “platform” boundaries blur fast: what’s commodity plumbing versus brand-defining differentiation?
Bielby also points out the overlapping landscape of efforts like SOAFEE and the Autonomous Vehicle Computing Consortium (AVCC), and how difficult it is for the industry to cleanly articulate how each differs.
This is where Synopsys’ CES positioning becomes more than marketing. The future of SDVs is not just about better software. It’s about a repeatable engineering operating model that can survive multi-vendor reality. Virtual prototypes, electronics digital twins, continuous test strategies, and CI/CD pipelines are not nice-to-have abstractions. They’re what make cross-company collaboration possible without collapsing under schedule pressure.
And Synopsys is building a thesis that it can deliver that layer — especially now, with Ansys in the fold and NVIDIA as a major partner and investor in accelerating engineering workflows.
The Friction of Consolidation: Not a One-Horse Race
While Synopsys is positioning itself as the connective tissue of the SDV era, its path is not without significant hurdles and aggressive competition. The very consolidation that makes Synopsys a powerhouse has also put it in the crosshairs of global regulators. To secure approval for the Ansys merger in 2025, Synopsys was forced by the EU and UK to divest key assets in optical solutions and power analysis software to preserve market choice. Analysts remain watchful of how seamless the integration of Ansys’ physics engines into Synopsys’ silicon tools will truly be, as cross-domain interoperability often suffers in the wake of massive corporate integrations.
Furthermore, Synopsys is facing a clash of the titans at CES 2026. Two major forces are challenging their narrative:
- The Rival Stacks: Siemens EDA is aggressively countering with its own PAVE360 Automotive digital twin platform. Like Synopsys, Siemens has integrated its stack with Arm’s Zena compute subsystems and is pitching a cloud-based, "off-the-shelf" digital twin that targets the exact same “shift-left” pain points. Meanwhile, Cadence Design Systems is doubling down on physical AI with its Millennium M1 and M2000 supercomputing platforms, focusing on high-fidelity multiphysics and CFD simulations that compete directly with the Ansys-enhanced portion of Synopsys’ portfolio.
- The Open-Source Alternative: Not every OEM is eager to buy into a proprietary, vertically integrated “one-stop-shop.” The Eclipse SDV community is moving toward its SCORE 1.0 release in 2026, advocating for an open, standardized architecture. This movement aims to prevent the "vendor lock-in" that a Synopsys-Ansys ecosystem might represent, allowing automakers to swap tools and suppliers without being tethered to a single EDA giant’s roadmap.
For OEMs, the choice isn’t just about if to virtualize, but whether to do so within the “walled garden” of an industry giant like Synopsys or through a more fragmented, open-standard approach.
The TechArena Take
The SDV conversation often gets stuck at the top of the stack: operating systems, middleware, autonomy frameworks, user experience. Those are real differentiators. But the industry’s most urgent constraint is the road to SDVs: the cost and time of validation, integration, and system bring-up as vehicle architectures become more centralized, more software-defined, and more AI-driven.
Synopsys asserts that virtualization is the enabling move that changes the economics. It’s not just about faster simulation. It’s about a software-first engineering model that makes earlier integration viable, reduces late-cycle risk, and supports continuous updates across the vehicle lifecycle.
The question is not whether virtualization becomes central. It already is. The question is which vendors can turn it into an industry-grade operating model that OEMs and suppliers can adopt at scale across fragmented platforms, shifting standards, and a competitive landscape that is forcing unlikely alliances.


Intelligence Everywhere: Defining the Era of Edge and Physical AI
Deploying the future: At CES 2026, the Arm ecosystem is delivering AI from the cloud to the front lines—powering mobility, robotics, and personal computing with fast, efficient, on-device intelligence.

2026 Predictions: A Year of Human and Machine Revolution
Looking back on my 2025 predictions made me reflect on all that we’ve seen in the tech landscape in 2025: the massive silicon shakeup capped by last week’s Groq news, the rise of agentic computing demonstrated by actual practitioner advancement (see our interview with Walmart).
Reflecting also reminded me of what we haven’t seen yet: an edge explosion (more on this later), or a major AI corporate scandal.
As we turn the page look forward through 2026, my focus is on changes related to infrastructure and AI advancement and the human response to the changing relationships between machines and society. While I still think we are in early innings of the AI era, we are getting to the point of this arc where long term challenges are taking form, and we are starting to see how society is taking in this disruptive change, or rallying against it.
Without further ado, I offer my predictions for 2026:
1) We will see massive adoption of AI inference across the compute continuum from cloud to edge, and a new era of distributed autonomous computing will take hold.
Inference will be delivered based on economic efficiency, driving smaller model jobs to the edge at the point of data origin where efficiency of workload delivery will be the primary focus. For more complex inference, we will see highly tuned inference engines in the cloud deliver performance optimized results.
All will be delivered with bespoke silicon designed for the job at hand, allowing for silicon heterogeneity to continue to thrive in infrastructure deployments. This will be delivered by enterprise and their value chain partners with AI investment starting its slow climb of economic return.
2) AI oversight of machines will become critical in an agentic era.
We all saw the headlines during the fall of 2025: the massive outages at AWS and Microsoft, and how these outages rocked business. The truth is, the foundations of cloud architectures were built for a different generation of computing, and new forms of compute including agentic models with complex and lengthy workflow, are requiring some advancement of stack development that goes to the foundations of system state management.
True composable infrastructure – across compute, storage and network – will be required to provide agent control of workflow completion, and this means looking at the telemetry and management foundations of platforms to give better data to management suites. If you’re thinking… Allyson, we did this a decade ago… think again.
3) The conversations on data privacy and AI control will heat up, led by EU efforts to provide some thought to how AI models access data, how data is protected in this process, and who owns any semblance of IP when IP forms the foundation of model wisdom.
While I do believe the genie is somewhat out of the bottle on this topic already… a public backlash on what is human creation will drive conversations and action well beyond Silicon Valley. This will be driven, I think, by an AI advancement that will produce a fear backlash to the technology that we haven’t seen yet.
4) Brain drain will enter center stage in scientific computing circles as government contracts favor vector-based computing investment advancing AI over more traditional forms of compute needed for many areas of scientific modeling and research.
Think of things like airflow predictions to land planes or advanced climate modeling – studies that require calculation precision. With government grants drying up in some parts of the world (like the US) for this computing, scientists are seeking new shores to advance their research, leaving us with existential questions about the value of science in society.
5) We will see a massive advancement in quantum.
Maybe this last prediction is what I want to see, but with the gathering momentum of quantum compute, I believe we are in for a disruptive moment in creation of sustainable quantum workload delivery. With it, the potential to disrupt human advancement on knowledge well beyond the boundaries of traditional computing.
Buckle up. This year promises an exciting landscape for compute and human advancement. This article wraps the TechArena predictions series, and if you didn't check out the predictions in total, revisit the series here. While not all of these predictions are likely to come true, you can trust TechArena’s voices of innovation to bring you center stage for those that do while also shining a light on those innovations guaranteed to take us by surprise.

Predictions for 2026: Three Forces Disrupting Vehicle Development
It’s hard to believe that we are on cusp of a new year where, here again, I am looking into my crystal ball to predict the 3 major trends that I believe will meaningfully affect the automotive industry. To be clear, these predictions aren’t thoughts that I have simply pulled out of thin air but reflect my observations of events that have transpired and that I expect will see significant traction in the future.
If you’ve been tracking the automotive industry lately, you’ve probably noticed some turmoil. This isn’t a cyclical downturn; it’s a fundamental rewiring of how cars are conceived, built, and sold. While this doesn’t affect the overall trends that I shared in last year’s predictions, I believe that we are in the midst of witnessing three transformative trends that will separate tomorrow’s leaders from today’s laggards:
(1) AI-driven product development compressing design cycles by 60-70% while revolutionizing how we certify safety;
(2) a widening software-defined vehicle divide where clean-sheet manufacturers sprint ahead while incumbent original equipment manufacturers (OEMs) trip over their own legacy architectures; and
(3) incentive withdrawal triggering a temporary hybrid resurgence, yet failing to halt the fundamental electric vehicle (EV) cost-crossover momentum.
Trend 1: AI-Driven Product Development – Shrinking Design Cycles from Years to Months
Designing a car used to require three to five years of rigorous, sequential work. Those timeframes are starting to become a thing of the past. Today, leading manufacturers are deploying generative design algorithms that generate thousands of engineering-validated component concepts in hours—a process that used to require months of human iteration. BMW’s AI systems crunch millions of parameters simultaneously, optimizing crash safety, weight reduction, and manufacturing feasibility all at once. It’s not just faster; it’s fundamentally different. These algorithms explore design possibilities that would never occur to human engineers—like organic, biomimetic chassis structures that cut material usage by 40% while improving crash performance.
Safety compliance—the traditional bottleneck that required endless physical prototypes and crash tests—is getting a complete makeover through AI-powered virtual validation. Machine learning models trained on decades of crash data and regulatory requirements now predict compliance outcomes with 95%+ accuracy before the first prototype is even built.
Additionally, it will be the norm for AI to be employed in functional safety certification, particularly ASIL compliance under ISO 26262. What once demanded months of tedious traceability mapping and documentation review is now orchestrated by agentic AI systems that provide 24/7 compliance monitoring, automatically generating technical requirements and linking them to architecture and test cases.
When Euro NCAP (new car acceptance procedure) introduced new vulnerable road user protocols in 2023, AI-equipped manufacturers certified compliance months ahead of competitors still chained to physical testing cycles.
The real game-changer? AI creates a continuous improvement loop where vehicles evolve post-launch through over-the-air updates informed by real-world performance data. Auto OEMs like Tesla and ADAS chip suppliers like Mobileye are great examples of this approach, using its fleet as a distributed sensor network that feeds billions of miles of driving data back into design algorithms. The competitive moat isn’t just engineering expertise anymore—it’s the sophistication of AI training data and computational infrastructure. Early adopters are already achieving 50% reductions in development costs while launching vehicles that are simultaneously safer, more efficient, and more responsive to emerging customer needs and regulatory demands.
Trend 2: The SDV Architecture Divide – Incumbent OEMs Stumble as Clean-Sheet Competitors Sprint Ahead
The promise of software-defined vehicles (SDVs), where hardware stays stable while features continuously evolve through over-the-air (OTA) updates, has created an existential crisis for automakers who’ve spent decades perfecting the exact opposite model. While Tesla and Chinese manufacturers like BYD push new functions weekly via OTA updates, incumbent OEMs remain shackled to three-to-five-year hardware refresh cycles that mirror their old development processes.
This isn’t just a technology gap; it’s a fundamental architectural disadvantage rooted in decades of supplier-dependent, siloed development. Clean-sheet manufacturers design computing architectures as integrated systems from day one, selecting centralized processors with two to three times headroom for future growth. Incumbents, by contrast, attempt to orchestrate SDV platforms across a fragmented ecosystem where individual Tier-1 suppliers own proprietary software stacks—creating a “Frankenstein architecture” where integration becomes the primary engineering challenge rather than innovation.
Recent industry events have brutally validated this structural handicap. Volvo’s recent announcement that they must provide physical hardware upgrades for the EX90—because its processing architecture became overwhelmed by escalating advanced driver assistance system (ADAS) and connectivity demands—perfectly illustrates the incumbent predicament. Having designed a “software-defined” platform with insufficient compute headroom, Volvo now faces the nightmare scenario: costly retrofits and dealer service visits that contradict the very premise of SDV flexibility. This stems directly from legacy thinking that optimizes hardware for launch-day requirements rather than a decade of capability growth.
Ford’s cancellation of its “Lightning” SDV platform tells a similar story of ecosystem collapse: after three years and hundreds of millions invested, the company conceded it simply could not orchestrate the 40+ software suppliers needed to create a unified, updateable architecture. The complexity of synchronizing partners with competing commercial interests, disparate code bases, and incompatible security frameworks proved insurmountable—particularly when each supplier sought to protect its intellectual property rather than cede control to a centralized OEM platform.
The market is bifurcating into haves and have-nots at a heightened pace. Clean-sheet players achieve not just faster feature deployment but fundamentally different business models: they capture software-driven revenue streams, improve vehicle performance post-purchase, and build direct customer relationships through continuous value delivery.
Meanwhile, incumbent OEMs face a brutal choice: absorb massive write-downs to completely re-architect their platforms or surrender the software layer to tech giants like Qualcomm or NVIDIA, effectively becoming hardware integrators in their own products. The estimated three-to-four-year delay in SDV deployment creates a compounding disadvantage: while viable SDV based vehicles refine their self-driving algorithms across millions of vehicles, traditional OEMs must wait for next-generation architectures before they can even collect comparable data.
Trend 3: Incentive Withdrawal Triggers Tactical Retreat to Hybrids, Yet EV Momentum Proves Unstoppable
The global EV incentive landscape is undergoing a dramatic unwinding that directly threatens the business case for electric vehicle development in Western markets. Germany’s abrupt cancellation of its €4,500 EV subsidy in December 2023 triggered an immediate 16% plunge in EV sales and forced Volkswagen, Mercedes-Benz, and BMW to freeze or delay multiple EV programs mid-development. The UK, having ended its plug-in grant in 2022, saw EV market share stagnate at 16% while hybrid sales grew 27% year-over-year. In the US, while federal IRA credits remain technically available through 2032, political headwinds are tangible: Republican-led states are blocking charging infrastructure funding, tightening eligibility requirements, and creating regulatory uncertainty that freezes OEM capital allocation. Ford’s $12 billion EV investment pause and GM’s delayed Ultium platform rollout aren’t strategic pivots; they’re direct responses to the removal of subsidies that made those programs financially viable.
The immediate beneficiary will be the hybrid, which incumbent OEMs are rapidly repositioning as the “rational bridge technology.” Toyota’s aggressive hybrid push—projecting 40% of its US sales will be hybrids by 2026—exploits this policy window. With no charging infrastructure dependency, lower price premiums, and immediate fuel economy benefits, hybrids offer OEMs a politically safe, capital-efficient compliance path. OEMs including Stellantis are following suit, retooling its electrification roadmap to emphasize plug-in hybrid electric vehicles (PHEV) in Europe and conventional hybrids in North America, essentially ceding the pure EV market to Tesla and Chinese imports for the next three to four years.
When $7,500 in tax credits evaporate, a $45,000 EV becomes a $52,500 psychological proposition, while a $35,000 hybrid remains exactly that. The engineering resources being diverted from pure EV programs to optimize next-generation hybrid powertrains represent a massive opportunity cost that extends the combustion engine’s lifespan and delays the very economies of scale EVs need to achieve true cost parity.
However, declaring an EV slowdown is to mistake tactical headwinds for strategic defeat. The momentum is simply shifting to geographies and segments where pure economics, not subsidies, drive adoption. China’s EV market grew 37% in 2024 despite negligible consumer incentives, powered instead by BYD and Geely delivering 300-mile range vehicles below $20,000. In the US, fleet electrification is accelerating regardless: Amazon’s Rivian rollout, FedEx’s EV delivery mandate, and Hertz’s continued EV expansion prove total cost of ownership advantages are real for high-utilization vehicles. Battery costs have dropped significantly since 2010 and continue declining at 8-10% annually, making the cost-crossover point inevitable.
The regulatory pressure hasn’t vanished. California’s ACC II mandate requiring 100% zero-emission vehicles by 2035 still stands, and the EU’s 2035 combustion ban remains in force. The “EV slowdown” narrative is a Western-centric illusion: globally, EV sales will hit 18 million units in 2025, up from 14 million in 2024. The real story isn’t retreat: it’s bifurcation, where incumbent OEMs, hobbled by capacity constraints and political risk, yield the mass market to nimbler competitors while fighting rearguard actions with hybrid technology.
Strategic Implications: The Great Bifurcation
These three trends don’t merely challenge the automotive industry. They actively dismantle it, creating an outcome where winners accelerate away from losers with compounding advantages. Successful companies will navigate this landscape by taking these three critical strategic shifts:
1. Transform Development into a Computational Advantage: AI-driven design isn’t a productivity tool; it’s the new basis of competition. OEMs must invest in extensive data gathering and AI infrastructure now or surrender engineering leadership to tech giants.
2. Architect for Software Velocity: The SDV transition demands immediate consolidation of software control. Incumbent OEMs must reduce supplier partners and accept near-term margin compression to own their architectures or permanently cede the customer relationship to ecosystem orchestrators.
3. Decouple EV Strategy from Western Policy Cycles: The incentive rollback is masking the ultimate long-term shift to permanent electrification. Winners are shifting R&D to China-aligned markets and fleet segments where the economics already favor EVs, treating Western consumer subsidies as nice-to-have rather than essential.
The companies that thrive won’t be those with the best internal combustion engines or the most efficient legacy factories. They’ll be the ones that recognize automotive manufacturing has become a data and software business that happens to produce vehicles.

How PEAK:AiO Turns Commodity Servers Into AI Rocket Ships
By delivering performance with one-sixth the hardware footprint of competitors, the software-defined storage startup aims to make AI experimentation affordable at scale.
Organizations building out AI infrastructure have rapidly matured from struggling to understand GPU requirements to demanding scalable, cost-effective solutions that can grow with their ambitions. At the recent OCP Global Summit, I spoke with Roger Cummings, CEO of PEAK:AiO, and Solidigm’s Jeniece Wnorowski about how one company is tackling the infrastructure challenges that emerge as AI moves into production-scale deployments.
Performance Without Infrastructure Sprawl
PEAK:AiO’s original breakthrough was software-defined AI storage that transforms commodity servers into high-performance infrastructure. “Our secret sauce very early was getting line-speed performance on a single server,” Roger said, thereby maximizing performance in the smallest possible footprint. This approach turns an ordinary server “into a rocket ship for AI” and helps organizations avoid massive deployments that consume excessive power, cooling, and rack space.
The efficiency gains are dramatic. Roger explained that competitors typically require 12 to 15 nodes to match the performance PEAK:AiO delivers with just one-sixth the infrastructure. Enabled by its close partnership with Solidigm, this density advantage translates directly into lower operational costs for power, thermal management, and physical space—critical factors as data centers face growing energy constraints.
Open-Source File System for Scale
Single-server performance solved the first wave of challenges, but today’s expanding AI applications demand the ability to scale across distributed file systems. The market is littered with proprietary solutions, so PEAK:AiO took a different path: in collaboration with Los Alamos National Laboratory, it developed an open-source parallel network file system (pNFS) built specifically for AI workloads.
Going open source aligns with industry standards and customer demands for simplicity and flexibility. Roger emphasized that the new pNFS solution “will match the performance of storage as well as the scale of the file system that people need today.” The company uses a modular framework that automatically recognizes new nodes as they’re added, delivering linear scaling for both capacity and performance. This architecture dramatically lowers the cost of experimentation and failure—an essential consideration for teams exploring new AI use cases. As Roger put it, “It doesn’t have to be cost-prohibitive to take risks and build innovation.”
From Centralized Training to Distributed Intelligence
PEAK:AiO’s value proposition has evolved along with the AI market itself. While large-scale training clusters once dominated the conversation, inference workloads—both in centralized facilities and at the edge—are now the primary growth driver. The company’s high-performance, scalable platform is ideally suited for both.
Roger also highlighted rising interest in federated learning, where intelligence is captured as close as possible to the data source before being rolled up into master models. PEAK:AiO’s infrastructure naturally supports these distributed architectures by enabling fast data capture and processing wherever the data is generated.
Building Success Through Workload Intelligence
Looking ahead, Roger said, “We need less infrastructure and more success—and I think we’re a great partner to achieve that.” Future innovations from PEAK:AiO, developed in partnership with Solidigm, will create richer memory and storage tiers with deeper intelligence about AI workload patterns. This will allow automated, policy-driven movement of workloads to the optimal tier, further improving both performance and cost efficiency.
TechArena Take
PEAK:AiO’s trajectory shows how infrastructure providers are evolving to meet AI’s real-world scaling challenges. Its focus on extreme efficiency, modular open-source architectures, and workload-aware optimization directly addresses the constraints of power, space, and budget while delivering the performance AI demands. As deployments shift from centralized training to distributed inference and federated learning, solutions that combine density with operational simplicity will become increasingly indispensable.
Learn more about PEAK:AiO’s infrastructure solutions at https://peak-aio.com or connect with the team to explore how their open-source approach can accelerate your AI initiatives.

RackRenew Turns Decommissioned OCP Hardware into Ready Capacity
During #OCPSummit25, Jeniece Wnorowski of Solidigm and I caught up with Jelle Slenters of RackRenew on how the firm converts retired OCP-compliant racks, servers, switches, power shelves and more into validated rack-level systems, complete with provenance, burn-in, and a joint certification label.
Why Remanufacturing is Having a Moment
The cloud era taught us to think in fleets. The AI era is forcing us to think in megawatts. In between those realities sits an enormous pool of high-quality, standards-based gear that ages out of hyperscale production far faster than it ages out of usefulness. RackRenew’s thesis is simple: if we standardize the processes for take-back, test, refurbish, and certify—at scale—we can turn retired systems into ready-to-run capacity for the next wave of adopters.
That’s not a niche. As Jelle put it, the total addressable opportunity is in the “hundreds of millions,” and if we truly nail the collaboration across the industry, the upside is “beyond calculation.” The value comes from process: documented, repeatable, and reliable.
Standards are the Scaffolding
OCP is the right place to be talking about this because standards reduce entropy. Common form factors, power and management specs, and known failure modes mean you can design remanufacturing flows that aren’t bespoke for every asset. When you remove variance, you remove cost and time. When you add shared protocols, you add trust.
Trust is the Currency
Enter the OEMs and platform providers. The opportunity is to co-design take-back and recert flows for entire OCP building blocks—racks, servers, switches, power shelves, and harnessing—not just components. That means shared diagnostics, firmware baselines, power/thermal tests, and a joint certification label that signals: remanufactured, validated, and backed by a warranty. That’s what moves circular gear from “nice idea” to procurement-approved infrastructure.
Where the Demand Shows Up First
Two near-term landing zones stood out in our conversation:
- Fast-growing operators: Clouds, co-locators, and service providers that need to stand up capacity quickly—full racks, network fabrics, and power shelves—without long lead times or greenfield budgets.
- GPU inference and bare-metal providers: Standing up GPU clusters isn’t just GPUs; it’s the rack, the fabric, the power path. Dropping in certified OCP rack-level assemblies lets teams scale faster while keeping performance envelopes predictable.
If we get the ecosystem right, customers get predictable outcomes. And predictable outcomes are the only way circularity shows up in the production SOW.
Circularity With a P&L
I love a good sustainability story, but the reason this matters goes beyond sustainability into economics. In an era of equipment scarcity and grid constraints, circular supply unlocks capacity faster and cheaper. That means shorter time to deploy, lower embodied carbon, and better capex efficiency. And because OCP standards reduce integration costs, the savings aren’t swamped by engineering overhead.
The Collaboration Blueprint
Jelle’s outline for how this scales:
- Co-develop take-back protocols with OEMs and hyperscalers.
- Align on software tools, test plans, and recertification criteria.
- Ship with a joint label and warranty that enterprise buyers trust.
- Route eligible material into remanufacturing streams and place it directly into new, standards-compliant builds.
Do that across storage, compute, networking, and power, and the “hundreds of millions” TAM looks conservative.
Quality and Reliability
Reliability comes from grading and process: rack-level power and thermal validation, network link integrity checks, server health screening, and repeatable test plans. The result is predictable service-level objectives and clear workload matching—without over-indexing on any single subsystem.
TechArena Take
Circularity wins when it delivers new-grade outcomes. The end user shouldn’t have to adjust workloads or expectations because a rack is remanufactured. OCP standards make that possible at scale. The next step is trust infrastructure—joint labels, shared test artifacts, and warranties. RackRenew’s rack-level, certified approach makes circular capacity a practical default for new deployments, unlocking savings, faster turn-ups, and lower embodied carbon.
Learn more about RackRenew at their website.
Watch the podcast

5 Data Infrastructure Shifts That Will Define Enterprise AI in 2026
Enterprises spent the past two years experimenting with generative AI and building successful proofs of concept. These early efforts delivered real value, yet they also revealed deeper architectural challenges that many organizations had not fully anticipated. As AI adoption grew, teams faced rising storage costs, slow refresh cycles, limited lineage visibility, fragmented governance, and new operational risks from automated agents.
Leaders are beginning to understand that long-term AI success depends less on the choice of model and more on the strength of the data foundation beneath it. The next phase of AI maturity will be shaped by how well organizations modernize their data platforms to support higher volumes, real-time insights, and greater transparency.
In 2026, five data infrastructure shifts will have a significant impact on which enterprises scale AI effectively and which ones remain stuck in pilot mode.
1. AI Will Stress the Data Layer Before It Stresses Compute
Early AI conversations focused heavily on GPUs, inference performance, and model architecture. As adoption accelerates, a new pressure point is becoming clear. The data layer is reaching its limits first.
Continuous AI workloads generate repeated embedding cycles, large vector indexes, multiple versions of the same data, and expanding volumes of metadata. Storage spending is increasing faster than compute spending for many organizations, particularly in retrieval-heavy and personalization workloads. These patterns highlight that existing architectures were not designed for always-on AI pipelines.
Organizations that invested early in unified lakehouse designs, lifecycle automation, and efficient tiering will enter 2026 in a stronger position. Others will need to prioritize data layer modernization to support AI at scale.
2. Agentic AI Will Require the Addition of a Guardrails Layer
Agentic systems are emerging as a practical way to automate tasks such as case updates, triage, content generation, and workflow coordination. These systems reduce manual work and improve response times, but they also introduce new risks related to data quality and operational integrity.
In 2026, enterprises will begin to introduce a dedicated guardrails layer that governs how agents interact with data. This will include checks before an agent writes to a system, detailed logs of all automated actions, controlled environments for testing new behaviors, rate controls to prevent runaway loops, and data contracts that clearly define what an agent is allowed to do.
Organizations that implement this structure early will adopt agentic workflows responsibly and with confidence. Those that deploy agents without guardrails will face operational issues that slow progress.
3. Real-Time Context Will Replace Overnight Batches for High-Value AI
AI systems achieve stronger results when they receive recent behavior, live events, and session-level context. As a result, the need for real-time data will continue to grow in 2026.
During 2025, many organizations observed that daily data refresh cycles were not sufficient for fraud detection, operational intelligence, or personalized digital experiences. In response, more teams are moving toward event-driven architecture and streaming pipelines that deliver fresh information directly into AI systems.
This shift will create wider adoption of continuous ingestion, closer connections between feature stores and streaming systems, and a reduced reliance on overnight batch jobs. Even partial modernization toward real-time data will lead to noticeable improvements in AI accuracy and responsiveness.
4. AI Governance Will Become a Core Part of the Data Platform
Executives, regulators, and internal risk teams are asking deeper questions about how AI systems operate. These questions focus on lineage, model inputs, data quality, access control, and the ability to review how decisions were made.
In 2026, governance will move from a manual review process to an integrated part of the data platform. Organizations will introduce automated lineage capture, consistent dataset and model documentation, versioning of training data and embeddings, policy-aware ETL pipelines, and comprehensive logs of how AI and agents interact with sensitive data.
Teams that embed governance directly into engineering workflows will scale AI programs more efficiently and with fewer audit challenges.
5. Efficiency and Sustainability Will Become Key AI Metrics
AI workloads drive significant energy consumption and storage growth. As reporting expectations evolve, organizations will begin measuring AI systems by efficiency as well as performance.
This will create new expectations around storage footprint per AI system, energy considerations for model training and inference, clear lifecycle policies for data and embeddings, and thoughtful workload placement in regions with cleaner energy profiles. Well-designed pipelines will reduce cost, support sustainability goals, and prepare enterprises for emerging reporting requirements.
Over time, efficiency will become a differentiator in how organizations deliver AI responsibly.
Looking Forward
The year ahead will be an important moment in the evolution of enterprise AI. Organizations that succeed will be the ones that strengthen their data foundations and build platforms that support real-time intelligence, responsible automation, and transparent governance.
AI may begin with models, but it reaches its full potential only when the data ecosystem beneath it is ready. The enterprises that invest in these foundations today will be positioned to lead the next wave of intelligent systems in 2026 and beyond.