
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.




















.webp)
Arm Steps into the Silicon Spotlight with AGI CPU
In a strategic move that alters its long-standing business model, Arm this week unveiled the Arm AGI CPU, its first-ever production silicon product designed for data center AI infrastructure.
While the company has spent 35 years providing the blueprints for others to build upon, the AGI CPU represents Arm’s first direct entry into the commercial silicon market.
Developed in collaboration with Meta and enabled by Synopsys’ full-stack design portfolio, the AGI CPU is aimed at a burgeoning category of agentic AI workloads. These tasks, which involve AI models that reason, plan, and execute tasks autonomously, require high levels of scalar performance and memory throughput.
The Design and Verification Framework
Bringing a 136-core, 3nm processor to market as a first-time silicon vendor required a comprehensive design infrastructure. Arm utilized Synopsys’ end-to-end portfolio, spanning electronic design automation (EDA), silicon-proven interface IP, and hardware-assisted verification (HAV).
The technical workflow leveraged Synopsys’ EDA solutions to manage the complexity of advanced process nodes. These tools supported synthesis, power integrity analysis, and signoff timing, which were necessary to meet the performance-per-watt targets specified for next-generation AI environments.
To manage data movement, Arm integrated Synopsys’ interface IP solutions. These components act as the critical communication links within the SoC, facilitating high-speed data transfer between the CPU cores and external memory or accelerators. By using pre-validated IP, Arm aimed to reduce the inherent risks associated with first-pass silicon.
Verification played a central role in the development timeline. Using the Synopsys ZeBu Server 5 emulation system and HAPS prototyping platforms, Arm’s engineering teams were able to validate system functionality and software compatibility months before the physical chips returned from the foundry. This “shift-left” strategy is a standard industry practice to ensure that hardware and software are ready for deployment simultaneously.
Perspectives from the Partnership
Mohamed Awad, executive vice president of the Cloud AI Business Unit at Arm, noted the collaborative nature of the project.
“The Arm AGI CPU reflects the strength of our SoC design and the effectiveness of our collaboration with Synopsys,” he said. “Their design, IP, and verification solutions supported the development and validation of our breakthrough performance-per-watt chip for next-generation AI infrastructure.”
Technical Specifications and Market Positioning
The AGI CPU features up to 136 Arm Neoverse V3 cores per socket, operating within a 300-watt thermal design power (TDP). Built on TSMC’s 3nm process, the chip utilizes a dual-chiplet architecture. It supports 12 channels of DDR5 memory at speeds up to 8800 MT/s, providing approximately 825 GB/s of aggregate bandwidth. For I/O, the processor includes 96 lanes of PCIe Gen 6 and native CXL 3.0 support for memory expansion.
Arm’s internal data suggests that the AGI CPU can provide a 2x increase in performance-per-rack compared to current x86 platforms. By targeting “agentic” workloads, Arm is positioning itself to handle the coordination and data-orchestration tasks that sit alongside dedicated AI accelerators like GPUs.
The TechArena Take
Arm’s shift from an IP architect to a merchant silicon provider is technically impressive, but it creates a delicate situation with its existing licensees. Companies like NVIDIA, AMD, and Intel, who all license Arm IP, now find themselves competing directly with their technology provider in the data center. Arm will need to manage these relationships carefully to avoid appearing to favor its own silicon over the IP it sells to others.
The 300W TDP for a 136-core part is a clear attempt to challenge x86 dominance in power-constrained data centers. In an era where power availability is the primary bottleneck for AI scaling, Arm’s decision to focus on performance-per-watt is a pragmatic entry strategy. However, the true test will be real-world software optimization and how effectively the AGI CPU handles the “unstructured” nature of agentic AI compared to established general-purpose processors.
Forward-Looking Branding
The naming of the AGI CPU is a bold marketing move. While the chip is designed to support the infrastructure for autonomous AI agents, the term AGI (Artificial General Intelligence) remains a theoretical milestone in the research community. By tethering its first chip to the most hyped acronym in tech, Arm is signaling its long-term intent, though the industry will likely judge the silicon on its IPC and latency metrics rather than its nomenclature.
Synopsys as the Industry Glue
This launch reinforces Synopsys’ position as the necessary scaffolding for the custom silicon era. Whether it is a hyperscaler like Meta or a traditional IP house like Arm, the move toward specialized silicon is increasingly dependent on a unified full-stack design flow. For Synopsys, enabling a first-time silicon vendor to hit 3nm targets is a strong proof-of-concept for their “HAV-to-Silicon” methodology.

Globeholder AI Unveils Thinking Lab for High-Stakes Decisions
This morning in Paris and Riyadh, Globeholder AI officially pulled back the curtain on its Thinking Lab, a platform that signals a fundamental shift in the AI trajectory. While the tech world has spent the last few years obsessed with the creative (and often hallucinatory) capabilities of large language models (LLMs), Globeholder is betting on a different flavor of intelligence: Type-2 Reasoning for the physical world.
Beyond the Text: The Case for Physical Grounding
The core thesis of Globeholder, led by co-founders Milene Göknur Jubin, PhD, and Eren Ünlü, PhD, is refreshingly blunt: "The world is not made of text."
Most AI systems today rely on fast pattern recognition, what cognitive scientists call Type-1 reasoning. These systems excel at predicting the next word in a sentence, but they stumble when asked to authorize a $2.1 billion investment in North Sea offshore wind farms. Why? Because energy systems, infrastructure networks, and climate patterns aren’t linguistic constructs; they are governed by physics, regulation, and logistical constraints.
Globeholder’s Thinking Lab is designed to bridge this gap by acting as a "sovereign, computational software environment" where AI agents operate like scientific teams. Rather than providing a probabilistic guess, the platform deconstructs complex questions into physical components, runs simulations, and stress-tests assumptions.
The Architecture of "Type-2" Intelligence
From a deep tech perspective, the Thinking Lab’s architecture is its most compelling feature. Built on a modular, partner-enabled framework, it functions as an operating system for physical-world intelligence.
Key technical pillars include:
- Scientific AI Agents: Operating within autonomous laboratories, these agents generate hypotheses and analyze observational and simulation data.
- Planetary Representation Layer: This layer integrates satellite imagery, geospatial data, and geo-transformer architectures to create a "world model."
- Multi-Signal Data Fusion: The engine combines observational, simulation, and operational data to deliver insights grounded in reality.
The platform’s 6-step workflow, moving from question decomposition to auditable decision delivery, aims to replace the months-long manual analysis typically performed by high-priced consulting firms with transparent, empirical answers delivered in minutes.
A Heavy-Hitting Ecosystem
Globeholder isn’t going at this alone. The startup is part of the NVIDIA Inception program and has deeply integrated its tech with NVIDIA’s Earth-2 and Cosmos models for large-scale weather and climate modeling. On the infrastructure side, the platform is deployed on AWS, ensuring the performance and resilience required for what they call "sovereign-grade decision-making."
TechArena Take
The most striking revelation in the Thinking Lab release isn’t the AI itself, but how it intends to dismantle the traditional "trust-by-proxy" model of strategic consulting.
Globeholder’s competitive differentiation makes a compelling case for why the current status quo is failing high-stakes industries:
- The Velocity Gap: While traditional consultants require six months to synthesize a report, and LLMs provide answers in seconds, Globeholder operates in the "minutes" sweet spot. This suggests a move away from static, manual updates toward real-time learning that can keep pace with volatile physical systems.
- From Visualization to Investigation: Most traditional GIS (Geographic Information Systems) are limited to maps only, offering visual data but lacking deep reasoning. Globeholder shifts the focus from simple spatial visualization to "Type-2" investigative reasoning grounded in the physical world.
- The Death of the Hallucination: LLMs are notorious for pattern matching and hallucinations because they lack empirical grounding. By enforcing evidence-bound chains and a full audit trail, Globeholder provides the glass box transparency that regulated industries, like energy and finance, require to move beyond text-based predictions.
- Cross-Domain Synthesis: Perhaps the most significant advantage is the ability to perform cross-domain synthesis. Traditional methods often trap data in single-domain silos. Thinking Lab is designed to reason across atmospheric science, infrastructure fragility, and fiscal consequences simultaneously.

Scaling Innovation into Enterprise Growth with Lakecia Gunter
Following this week's launch of the TechArena Advisory, we are excited to highlight the exceptional operators who are now bringing C-suite-grade strategic intelligence within reach of organizations at every stage of growth. While TechArena’s foundation is built on media and tech domain marketing, the Advisory represents our commitment to providing a high-impact alternative to expensive traditional consultants. We believe that in an era of rapid disruption, organizations don’t just need advice, they need the strategic blueprints of those who have already scaled multi-billion-dollar businesses.
To help our audience get to know the experts behind the Advisory, we are launching “5 Fast Facts,” a twice-weekly Q&A series. Our first featured advisor is Lakecia Gunter, an enterprise growth architect with a career defined by leading global teams and mastering the intersection of technology and revenue. Below, Lakecia shares her perspective on the widening gap between tech ambition and business execution.
Q1: What has changed in the tech landscape that made the Advisory a priority for you?
We’re at a moment where technology disruption is moving faster than most organizations can operationalize. AI, platform ecosystems, and digital infrastructure are redefining how companies compete, but many leaders are realizing that adopting technology and scaling it into enterprise growth are two very different things.
I see a widening gap across industries between technology ambition and business execution. Companies are investing heavily in AI and digital capabilities, but many are still figuring out how to connect those investments to revenue growth, ecosystem expansion, and long-term competitive advantage.
After decades of leading global teams responsible for multi-billion-dollar businesses, partner ecosystems, and product platforms, I’ve seen firsthand how technology becomes growth, or fails to.
This moment makes advisory work a priority because leaders need more than technical insight. They need guidance from operators who understand how to translate innovation into enterprise scale, revenue expansion, and lasting market leadership.
Q2: What does your experience bring to this moment?
My experience sits at the intersection of technology innovation and enterprise growth.
Throughout my career, I’ve led global organizations responsible for multi-billion-dollar revenue streams, large partner ecosystems, and enterprise transformation initiatives. At Microsoft, I helped lead strategy and technical engagement for one of the world’s largest partner ecosystems. Earlier roles included direct P&L responsibility for global business units and helping scale new technology platforms into global markets.
What this brings to the moment is the perspective of an enterprise growth architect, someone who understands how technology strategy, revenue models, partner ecosystems, and organizational alignment all work together.
My superpower is helping leadership teams turn emerging technology opportunities into scalable business growth. That means aligning strategy, ecosystems, and operating models so innovation doesn’t stay in pilot mode—it drives real market impact.
Q3: What challenges are business leaders facing that align with your practice areas?
Many business leaders today are navigating a difficult balancing act: investing aggressively in new technologies while ensuring those investments translate into real enterprise value.
Three challenges consistently surface in my work.
The first is AI and digital transformation execution. Organizations are experimenting with AI, but many struggle to operationalize it for measurable growth or operational efficiency.
The second is ecosystem monetization. Innovation increasingly happens through platforms and partnerships, yet many companies have not fully developed the strategies required to activate partner ecosystems as engines of growth.
The third is aligning technology investment with revenue outcomes. Digital transformation programs often focus on tools and infrastructure without clearly tying them to market expansion, customer value, or competitive differentiation.
My work helps leadership teams connect these dots, aligning technology strategy, partner ecosystems, and operating models to unlock scalable enterprise growth.
Q4: Are there key areas that you see most pertinent right now?
Three areas stand out as particularly critical for technology and business leaders today.
The first is AI strategy and governance. As AI moves into core business operations, organizations must balance speed of innovation with responsible deployment, security, and regulatory oversight.
The second is platform and ecosystem strategy. The most successful companies today are not building in isolation, they are architecting ecosystems. Leaders who understand how to activate partners, developers, and platforms will scale innovation far faster than those operating alone.
The third is enterprise growth architecture—ensuring that technology investments are tied to clear revenue models, market expansion opportunities, and long-term strategic positioning.
Organizations that master these three disciplines will be the ones that convert technological disruption into sustained competitive advantage.
Q5: What are the outcomes you’re targeting to drive?
My work centers on one core objective: helping organizations turn technology disruption into enterprise growth.
First, I work with leadership teams to build clear growth architectures, linking AI strategy, platform investments, and ecosystem partnerships directly to revenue expansion and market opportunity.
Second, I help organizations activate partner ecosystems as growth multipliers. When companies synchronize the right partners, platforms, and developer communities, they dramatically accelerate innovation and customer reach.
Third, I support leaders in creating operating models that scale transformation, ensuring that new technologies move beyond pilot programs into enterprise-wide impact.
Ultimately, the goal is simple: help companies move from experimentation to execution, ensuring investments in AI and digital platforms translate into measurable growth, stronger market positioning, and long-term competitive advantage.

Beyond the Prompt: The Rise of Context Engineering
Last year, a company deployed an internal AI assistant to help employees navigate thousands of internal documents. The system worked beautifully in testing. Then a product manager asked a simple question about the company's policy for handling customer data in Europe.
The assistant confidently returned an answer citing an internal policy document.
There was only one problem. The document had been replaced six months earlier. The AI wasn’t hallucinating. It was reasoning correctly. But on the wrong context.
This is becoming one of the most common failure modes in enterprise AI. Not because models are weak, but because the information surrounding them is poorly engineered. In other words, the biggest problem in enterprise AI is no longer the model. It’s the context.
And solving that problem is giving rise to a new discipline that many organizations didn’t plan for: context engineering.
The Real Bottleneck in Enterprise AI
For the past two years, the AI conversation has revolved around model capability: Which model is larger? Which model is faster? Which model performs best on benchmarks?
But once organizations begin deploying AI inside real systems, they quickly discover something uncomfortable: Most enterprise AI failures are not model failures. They are context failures.
Models are powerful reasoning engines, but they are fundamentally blind to the organizations they operate within. They do not understand internal documentation, product terminology, operational workflows, or governance policies unless that information is explicitly provided to them. And that information rarely exists in one place. It is scattered across data lakes, SaaS platforms, documentation systems, and operational databases. Retrieving the right knowledge at the right moment is not a trivial problem. It is an infrastructure problem.
From Prompt Engineering to Context Engineering
The first wave of generative AI adoption emphasized prompt engineering. Teams experimented with prompt templates, formatting tricks, and system instructions to improve model outputs. While prompts matter, they are ultimately just instructions.
The quality of an AI system’s response depends far more on what the model sees than on how the question is phrased. Enterprise AI systems increasingly rely on pipelines that retrieve and assemble relevant knowledge before a model generates its response.
This architecture typically involves:
- retrieving documents or records from enterprise systems
- ranking and filtering relevant information
- enforcing access policies
- injecting the resulting context into the model prompt
The shift from crafting prompts to assembling context is the foundation of context engineering.
Why Context Is Harder Than It Looks
Most prototypes hide the true difficulty of context management. A small document corpus is embedded into a vector database. Retrieval works well. The AI assistant appears intelligent. But enterprise deployments introduce realities that prototypes ignore, such as:
Freshness: Knowledge changes constantly. If embeddings are not refreshed regularly, AI systems begin reasoning on outdated information.
Permissions: Enterprise data is rarely universally accessible. Context pipelines must enforce access controls before retrieving sensitive information.
Semantic inconsistency: Different systems often describe the same concepts in different ways. Retrieval pipelines must reconcile these differences.
Traceability: Organizations must know where an AI-generated answer originated, especially in regulated industries.
These challenges are not failures of the model. They are failures of context infrastructure. And they are becoming the defining challenge of enterprise AI.
The Architecture of Context Pipelines
To solve these problems, enterprises are quietly building a new layer of infrastructure designed to assemble context for AI systems.
At a high level, the architecture looks something like this:
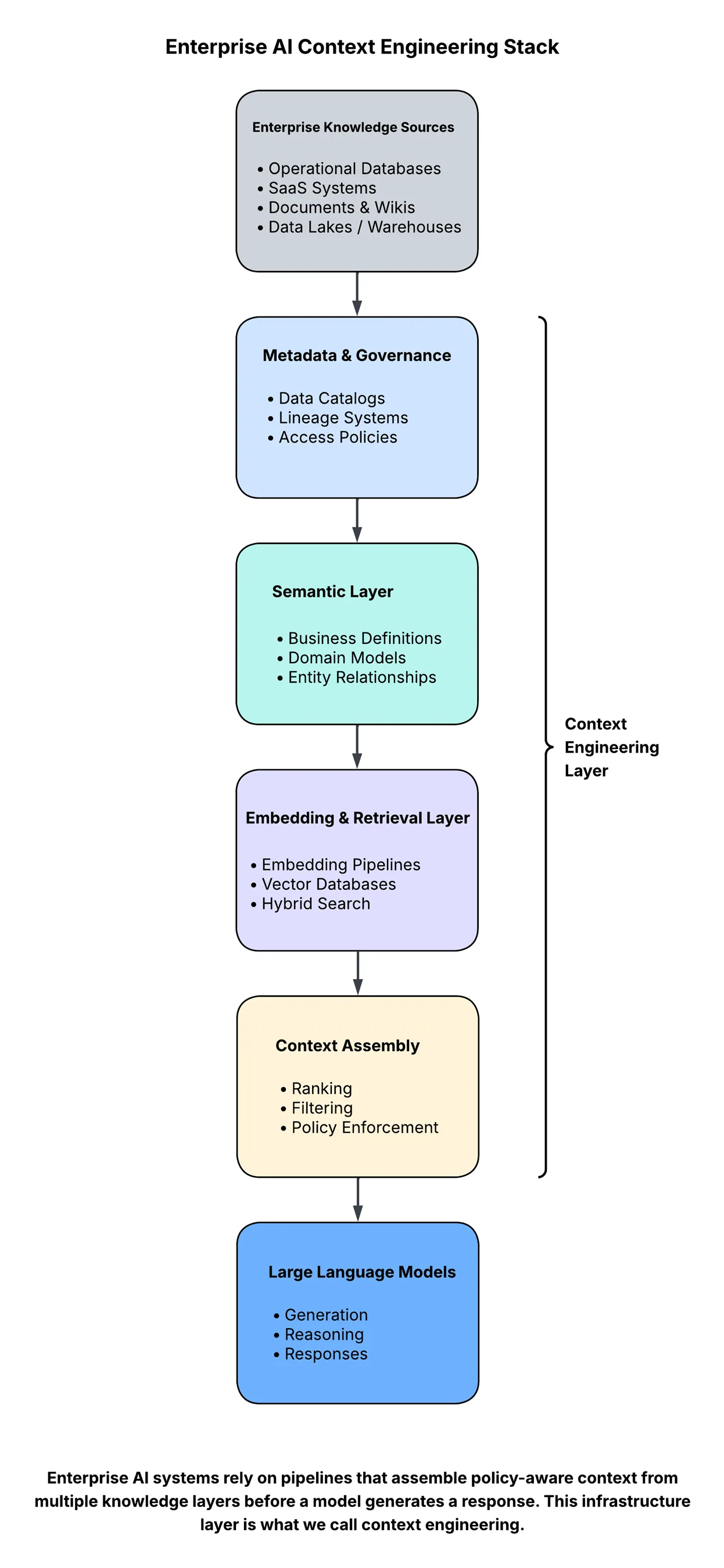
Every layer introduces challenges that look suspiciously familiar to data engineering teams:
- schema evolution
- metadata management
- governance enforcement
- observability and monitoring
- pipeline reliability
In other words, the infrastructure supporting AI applications increasingly resembles the infrastructure powering modern data platforms.
Why Your Data Team Is Now Your AI Team
One of the more surprising consequences of this shift is how it changes organizational roles. Many companies began their AI journeys assuming the key hires would be machine learning engineers or prompt engineers.
But as deployments mature, organizations are discovering something else. The teams solving the hardest problems in AI are often data platform teams.
Why? Because the quality of an AI system’s answers depends heavily on how well enterprise knowledge is structured, governed, and delivered at runtime.
This requires capabilities, such as:
- building reliable data pipelines
- managing metadata and lineage
- maintaining embedding refresh pipelines
- enforcing data governance policies
- monitoring knowledge freshness and retrieval quality
These are not new problems. They are data engineering problems that are now appearing inside AI systems, which leads to a somewhat uncomfortable observation: Many enterprises are spending millions optimizing model selection while investing almost nothing in the infrastructure that determines what the model actually sees.
The Emergence of Context Platforms
Most enterprise data platforms were designed for human consumption. Dashboards, data catalogs, and analytics systems assume a human analyst interpreting the results.
AI systems operate differently. They require knowledge that is structured, policy-aware, and retrievable in milliseconds. This shift is pushing organizations toward what might be described as context platforms, infrastructure designed specifically to deliver curated knowledge to AI systems.
These platforms combine elements of:
- data lakes and lakehouses
- metadata and lineage systems
- semantic layers
- vector retrieval infrastructure
- governance and policy engines
Together, these components form the operational backbone of reliable AI systems.
The Next Competitive Advantage in AI
Most organizations will eventually have access to similar models. The real differentiator will not be model access. It will be context quality.
Organizations that engineer context effectively will build AI systems that are:
- more accurate
- more explainable
- aligned with enterprise policies
- capable of evolving with the business
Organizations that neglect this layer will continue to experience AI systems that appear intelligent in demos but behave unpredictably in production.
The Infrastructure Beneath Intelligence
Artificial intelligence often appears to operate at the level of reasoning and language. But beneath every reliable AI system lies something less glamorous: pipelines, metadata systems, governance frameworks, and retrieval infrastructure.
In other words, intelligence at scale still depends on infrastructure. The companies that understand this shift earliest will build AI systems that work. Everyone else will keep searching for better models to solve a problem that was never about the model in the first place.

Where AI Inference Hits the Memory Wall
ZeroPoint’s Nilesh Shah explores why data movement, compression, and memory bandwidth now shape AI inference performance, and where heterogeneous systems and quantum may fit next.

TechArena Launches Advisory Practice Led by Former AWS, Intel, & Microsoft C-Suite Executives
PORTLAND, OR & NEW YORK, NY – March 24, 2026 – TechArena announced the formation of a new Advisory practice today, adding former c-suite and executive operators from Intel, AWS, Microsoft, Micron, Flex, and Altera to TechArena's leadership. Advisors bring deep expertise across cloud, AI, data center, and edge computing, with a track record of defining foundational technology, scaling routes to market, and driving business growth through leadership positions across silicon, infrastructure and cloud service leaders. Collectively, they have built $10+ billion businesses, navigated complex value chains, and ushered in major technology inflections including cloud computing,5G networks, and AI data center services.
This announcement, made during the Xcelerated Compute Show in New York, comes as a response to the existential challenges businesses face in navigating today’s accelerated technology landscape as operators race to deploy trillions of dollars of capital equipment to fuel AI’s advancement. Organizations are moving faster through more uncertainty than at any point in history. Traditional consulting models weren’t designed for this. Outside-in frameworks with no clear integration path simply don’t hold up under that kind of pressure. The Advisory practice brings operator experience from the world’s largest technology companies to help solve the most pressing challenges facing industry leaders today.
The Advisory joins TechArena’s existing practices focused on marketing collaboration and media publications. Launched in 2022 under Allyson Klein’s leadership, TechArena has featured and collaborated with over 100 leading technology companies as they seek to claim market advantage in the fast-paced AI landscape.
“Every element of technology innovation is under pressure to accelerate, from silicon design cycles to standards definition and data center buildouts. In this landscape, traditional consultancy models cannot keep pace with business challenges,” said Allyson Klein, founder and CEO of TechArena.“The Advisors aren’t prognosticating on the industry, their leadership helped build it. I’m thrilled to collaborate with this world class team to bring disruptive value to our clients.”
“Having a trusted advisor who can step in immediately assess the situation, and turn potential into real business value is critical,” said Jeni Barovian, co-founder Advisor of TechArena. “TechArena Advisory is exactly the kind of capability I wish I’d had in earlier executive roles—someone who’s been in your seat, understands the challenges, and can quickly add value and drive results.”
The Advisory practice will engage across the full range of challenges facing tech leaders today in achieving disproportionate value in this historic era. The Advisory leverages its collective depth, knowledge, and experience on challenges extending across product and portfolio strategy, market positioning and ecosystem and architecture bets to go to market and revenue acceleration, competitive narrative development, and financial, governance and investor confidence management. Given advisor experience in leading world class organizations, TechArena also expects clients to leverage the team’s talent to help improve organizational readiness and inject best practices for leadership development.
Together, these focus areas will serve as a catalyst for business growth and resilience in today’s competitive landscape. That impact is already resonating with early clients.
“TechArena Advisory’s collaboration with my organization demonstrated the unique value of deep operating experience, combined with a commitment to understanding our specific challenges,” said Alexis Crowell, Global CMO & GM of the Americas, Axelera AI. “They took time to research more about my company, our position in the market and helped us frame a key market opportunity and also delivered an action plan and supported execution to drive it forward.”
Founding Advisors include:
Raejeanne Skillern: Raejeanne brings silicon-to-service expertise to the Advisory practice, including having led the cloud computing transformation at Intel (NASDAQ: INTC), growing the business unit to over $10 billion in revenue for the company, re-positioning the Cloud, Enterprise, and Communications business at Flex (NASDAQ:FLEX) becoming the leading growth driver for the firm, and most recently served as Chief Marketing Officer of Amazon Web Services (NASDAQ: AMZN), the world’s largest cloud service provider. Raejeanne’s practice areas extend from market strategy to portfolio position and routes to market. She has led large scale organizations including driving culture and change management as well as being an advocate for leadership development. In addition to her Advisory work, Raejeanne currently serves as a member of the board of directors of Jabil (NYSE:JBL) and previously served on the board of directors of Lattice Semiconductor (NASDAQ:LSCC).
Lakecia Gunter: Lakecia brings a distinctive combination of enterprise growth leadership, ecosystem strategy, and board governance expertise to the Advisory practice. As former Chief Technology Officer of Microsoft’s (NASDAQ:MSFT) Global Partner Solutions organization, she operated at the center of one of the world’s largest partner ecosystems—driving multi-billion-dollar revenue growth, scaling global routes-to-market, and enabling partners to monetize AI-powered solutions. Her experience spans technology and commercial leadership, with a track record of connecting product innovation to revenue acceleration across global markets. She has led transformations at Microsoft and Intel, aligning platform strategy, partner ecosystems, and go-to-market execution to unlock growth in cloud, AI, and datacenter environments. Lakecia serves as an independent director at IDEX Corporation (NYSE: IEX), board advisor to Responsive.io, contributes to the Georgia Tech Advisory Board, and hosts the ROAR with Lakecia Gunter podcast.
Jeni Barovian: Jeni’s deep technology expertise was built through roles across product P&L leadership of Intel’s network and edge products, product management and strategy of Intel’s data center and AI silicon and software group. She most recently oversaw Altera’s business development across cloud, communications, and embedded markets, navigating the foundation of Altera as an independent entity and closure of private equity investment. She has served on the boards of directors of the Open Compute Project Foundation and Telecommunications Industry Association. In addition to her Advisory practice, Jeni is an advocate for education and serves on the Boards of Directors of the Case Alumni Foundation and Arizona Academic Decathlon Association.
Dana Bos: Dana's experience navigating organizational transformation across a dynamic industry portfolio includes a decade of leading an independent consultancy practice at Bos Solutions. Her deep expertise across sectors including technology, healthcare, biotechnology, and non-profit organizations provides a unique perspective on the changing organizational landscape created by AI integration into the enterprise. In addition to her Advisory practice, Dana is the co-host of the Maestro Mindset podcast with Rose Schooler, where they share their perspectives on leading and managing high-performance organizations from two complementary vantage points, the business leader and the organizational effectiveness expert.
Laura St. John: Laura’s deep finance and strategic leadership experience has created disproportionate growth for startups and Fortune 500 companies. At Intel, she instrumental in driving financial strategy for $25 billion in transformative strategic transactions with Apollo, UMC, and Brookfield, serving in board and leadership roles supporting execution and value creation. Her expertise spans corporate development, P&L management, FP&A, and post-merger integration, providing technology leaders with strategic and operational insight as they scale, pursue partnerships, and navigate complex transactions. Laura is also Co-Founder of MisaLabs.ai, simplifying AI inference deployment with modular building blocks and enjoying wearing the many hats required by her nascent startup.
Allyson Klein: Allyson’s vast industry marketing acumen was built leading marketing and communications for Micron (NYSE: MU) and datacenter and edge marketing for Intel. Her skill with mapping strategy to actionable impact has been the foundation of TechArena’s collaboration with tech sector clients since its foundation in 2022. Her work has been recognized by multiple Stevie, dot comm, and Women Tech awards. Earlier this year, she was named Tech Female Founder of the Year by the Global Business Tech Awards. Allyson has served as a professor at Portland State University’s business school, teaching undergraduate students the joys of entrepreneurism. In addition to her Advisory practice, Allyson is founder and CEO of TechArena and the host of the In the Arena podcast.
More information about TechArena’s business practice portfolio can be found on its website.

CESQ’s Maison du Quantique: Accelerating Europe’s Quantum Vision
Quantum computing is often discussed as a monolithic global race, but the real breakthroughs are happening in the trenches of regional innovation hubs, which often aim to bridge applied research and development (R&D) and industrial applications. One such focal point is MaQuEst — la Maison du Quantique Grand Est (the House of Quantum of the Grand Est region) — located in Strasbourg, France, which is quietly positioning itself as a vital node in the French and the European quantum networks.
MaQuEst is a three-year project of the European Center for Quantum Sciences (CESQ), publicly funded by the Region and the HQI (France Hybrid Quantum) initiative to develop and foster the local hybrid quantum computing ecosystem, accelerate technology transfer and quantum industry adoption through industrial use cases, and disseminate the results of the research and development programs. MaQuEst is one of the five Maisons du Quantique, currently present in France. It is aimed at development of quantum and hydride compute applications in its region and benefits from scientific and industrial cooperation with its German, Swiss, and other European partners.
The European Center for Quantum Sciences (CESQ) is a transnational quantum research and education hub of the University of Strasbourg and the CNRS (National Center for Scientific Research).
From March 23–28, 2026, CESQ will host Quantum Week 2026, a gathering of researchers, policy-makers, decision-makers from the industry, startups, and venture and entrepreneurial communities. Each day has a dedicated theme: the week starts with a policy-makers and diversity day, follows by a hackathon where postgradual students will solve real-life challenges using quantum algorithms, than a career day covering professional opportunities and openings in science and industry, followed by the industry day for decision-makers and entrepreneurs and closing with a public day, where people of all ages, including children, are invited to explore what quantum is. The event promises to establish a holistic view on the current state of the quantum ecosystem and launch discussions between science and industry. It aims to bridge the gap between theoretical physics and benchmarks of existing quantum hardware and software, and it strives to drive industrial application in diverse fields as finance and banking, defense and space, chemistry, cloud and data, and many more.
At TechArena, we’ve long argued that the future of the data center isn’t just about more silicon; it’s about a fundamental shift in how we process information. France has positioned itself as a vanguard in this revolution, backed by a €1.8 billion national strategy and a collaborative spirit that is uniquely European. This isn’t just about national pride; it’s about a bold, multi-geo perspective that recognizes that the complexity of quantum challenges requires a diversity of thought and infrastructure.
Central to this ecosystem is Maison du Quantique, a hub designed to accelerate the transition from “quantum curious” to “quantum ready.”
“While we see the increasing number of quantum events, our Quantum Week 2026 is not just another quantum conference. It’s a platform for a gathering of national and European scientific and industrial key players in quantum. It’s also a roadmap for the industrial and entrepreneurial ecosystem for exploration of quantum and hybrid computing and eventual integration of quantum applications and systems into their existing technological, operational, and economic models,” said Lesya Dymyd, business development lead at CESQ. Her work at Maison du Quantique focuses on driving quantum industrial applications and development of use cases across different markets, fostering the hybrid future where quantum units and classical HPC (high-performance computing) work in tandem.
Dymyd’s perspective is critical for our audience: she understands that for quantum to succeed, it must of course reach a certain level of technological maturity. At the same time, it must solve real-world problems in areas like in chemistry, defense, finance, cybersecurity, machine learning, and many others.
“The immediate mid- and long-term goals for quantum applications are to drive scientific discoveries and breakthroughs where classical computing meets its limits. As a result, it must create new economic value and drive competitiveness through innovation by development of new applications, reinvention of businesses, and creation of new markets.”
The upcoming event in Strasbourg serves as a testament to the “Strasbourg Vision,” a commitment to innovation, technology transfer, and startup creation. By bringing together international researchers from Fraunhofer, University of Freiburg, and Interreg partners; industry giants like Thales (defense and aerospace), Merck (chemicals and pharmaceuticals), Euro-Information (banking and finance), and Scaleway (cloud and data) ; and quantum startups like Pasqal, QPerfect, and Invision Imaging, that will join by La French Tech and Bpifrance, stakeholders and investors in the French entrepreneurial ecosystem. Quantum Week 2026 is where the “second quantum revolution” finds its industrial footing.
The need for a multi-geo perspective has never been more urgent. While North America and China dominate headlines and make significant public investments in the domain, the European approach, exemplified by the partnership between France and other European nations, prioritizes an open, collaborative value chain. This model ensures that the innovations developed in labs like CESQ aren’t just scientific curiosities but can be transformed into industrial use cases and one day could become scalable technologies capable of redefining the global tech landscape.
We will be following the developments in MaQuEst closely. In an era where compute is the most valuable resource on earth, understanding the quantum shift isn’t just an option, but a business imperative.
Stay tuned to TechArena.ai for insightful contributions from Lesya Dymyd as she helps our community navigate the horizon of quantum impact.
To learn more about CESQ and the hybrid future of quantum and HPC, check out this podcast.

NVIDIA Launches Its Computing Platform for the Age of Agentic AI
“Finally, AI is able to do productive work. And therefore, the inflection point of inference has arrived.”
Yesterday, Jensen Huang made a forceful argument that the evolution of generative AI has reached a new stage. After years focused on model training and advancement, the time has come for AI to contribute through real, measurable work.
“AI now has to think. In order to think, it has to inference. AI now has to do. In order to do, it has to inference. AI has to read. In order to do so, it has to inference. It has to reason. It has to inference.”
To support the age of inference, NVIDIA used its keynote to present its usual dizzying array of announcements and demonstrations (including, this year, a robot Olaf from Disney’s Frozen). For us, two new launches stood out among the set: the Vera CPU, the world’s first processor purpose-built for agentic AI workloads, and the BlueField-4 STX storage architecture, a modular reference design built to keep context memory fast, accessible, and efficient at rack scale. Together, they form the foundational compute and storage layers of the Vera Rubin platform.
The CPU Is No Longer Just Supporting the Model
The Vera CPU features 88 custom NVIDIA-designed Olympus cores and a second-generation low-power memory subsystem built on LPDDR5X, delivering up to 1.2 TB/s of bandwidth — twice the bandwidth at half the power of general-purpose CPUs. The headline performance claim is twice the efficiency and 50% faster than traditional rack-scale CPUs.
But the more strategic claim is about what the CPU is now being asked to do. As agentic AI advances, it is coordinating tool calls, orchestrating multi-step reasoning workflows, and running the inference scaffolding that keeps the whole system coherent. As Huang put it: “The CPU is no longer simply supporting the model; it’s driving it.”
NVIDIA also announced a new Vera CPU rack integrating 256 liquid-cooled Vera CPUs capable of sustaining more than 22,500 concurrent CPU environments, each running independently at full performance. For AI factories runing tens of thousands of simultaneous agent instances, that density is a significant operational advantage. Vera is in full production and will be available from partners in the second half of 2026.
Why the Storage Stack Had to Change Too
The Vera CPU story cannot be told without the BlueField-4 STX announcement, because the two are designed to address the same challenge with agentic AI moving into action.
General-purpose storage infrastructure was never designed with agentic AI in mind, and the performance gap becomes apparent the moment an agent has to retrieve context across long, multi-step reasoning chains. As context grows, traditional storage and data paths can slow AI inference and reduce GPU utilization. In production agentic systems, every retrieval from a slow storage tier adds latency to a reasoning chain that may already span hundreds of steps.
STX addresses this with, with NVIDIA saying it can achieve up to five times more tokens per second compared with traditional storage, four times higher energy efficiency, and two times faster data ingestion. The architecture centers on the new NVIDIA CMX context memory storage platform, a high-performance layer that expands GPU memory for scalable inference. Under the hood, BlueField-4 STX leverages a new BlueField-4 processor that combines the NVIDIA Vera CPU with the ConnectX-9 SuperNIC, along with Spectrum-X Ethernet networking, NVIDIA DOCA, and NVIDIA AI Enterprise software.
The TechArena Take
NVIDIA arrived at GTC 2026 with something more consequential than a chip announcement. It arrived with an argument: that the infrastructure built for large-scale model training is not the infrastructure needed to run AI that reasons, plans, and acts continuously.
The Vera CPU is designed to close the gap between CPU architecture and what agentic orchestration actually demands. STX addresses the storage latency problem that has been quietly degrading inference performance in production deployments. The announced partner list is wide, the timelines are near-term, and the roadmap extends further still, with the next Feynman architecture already scoped to advance every pillar of the AI factory: compute, memory, storage, networking, and security.
When Huang says the inflection point of inference has arrived, Vera and STX are the infrastructure answer to that claim. AI that thinks, reads, reasons, and acts continuously demands an infrastructure stack built specifically for that workload. The announcements this week show NVIDIA is already building for that demand.

Innovaccer’s Tapan Shah on Scaling Healthcare AI Safely
AI architect Tapan Shah joins the Data Insights podcast to discuss scaling AI in healthcare, governance, AI agents, and how technology can improve patient outcomes and reduce provider burnout.

Synopsys Converge 2026: From Silicon to Systems
Converge 2026 became the first real stage for the new Synopsys.
That message came through clearly as the company used its first major post-acquisition gathering to argue that the future of engineering will no longer be built in silos. In the AI era, the old boundaries between chip design, software development, system simulation, packaging, and physical behavior are collapsing. In their place is a more connected engineering stack built to handle what Synopsys President and CEO Sassine Ghazi called “the era of pervasive intelligence where AI is infused everywhere.”
Ghazi called 2026 “the year one of the new company,” a line that framed Converge as the first full public expression of what the Synopsys-Ansys combination is supposed to mean in practice. The company is still very much talking about EDA, verification, and IP, but it is now making a larger claim: that it can help customers engineer the next generation of intelligent systems from silicon to systems.
This is no longer just a story about designing chips faster. It is a story about building products that are increasingly software defined, physically complex, AI-enabled, and deeply dependent on coordination across multiple engineering domains.
Ghazi gave that vision a memorable turn of phrase when he said that as physical AI advances, “bits will inhabit and command the atoms.” It sounds dramatic, but it neatly captured the company’s larger point. The next wave of intelligent systems will not live only in data centers or on phones. They will increasingly operate in the physical world, which means engineering teams have to account for much more than logic, layout, and software alone. They have to account for thermals, mechanical stress, power delivery, signal integrity, materials, reliability, and environment, often all at once.
That broader shift was echoed in Synopsys’ technical keynote by Shankar Krishnamoorthy, the company’s chief product development officer, who described the market pressure now bearing down on silicon teams.
“The clock of our semiconductor industry has changed,” he said. “We are now on a one-year clock.”
In AI infrastructure, he argued, there is “absolutely no way to compromise” across performance, velocity, and quality. Teams are expected to deliver generation-over-generation gains faster than Moore’s Law can naturally provide, while also shipping increasingly complex devices that have to work right the first time.
Why AI is Forcing Engineering to Converge
.webp)
One of the most valuable sessions of the day came from the executive panel moderated by Allyson Klein, where leaders from across industries put real-world texture behind Synopsys’ argument. Their examples made clear that the pressure to converge engineering disciplines is already here.
If there was one repeated theme across the panel, it was the need to move learning earlier in the process. Todd Citron put it simply:
“A lot of this is about moving things left,” he said.
He described the shift not just as a matter of performance optimization, but as a way to bring lifecycle considerations into the design process much sooner.
“Not just optimizing the design for performance,” he said, “but being able to optimize the design over the life cycle by virtue of having that digital twin.”
That idea came up again and again. Panelists described a world in which software updates, new model architectures, and customer expectations are all moving too fast for traditional handoffs between engineering disciplines. Ravi Subramanian, the company’s chief product management officer, boiled it down to three drivers: products are becoming software defined and therefore “have to be silicon powered,” the pace of innovation is accelerating, and the historical “build it, test it, break it” model is simply too expensive and too slow.
Where the Silicon-to-Systems Case Got Real
One of the sharpest observations came when Subramanian recalled a customer telling him, “I don’t have shift, I have no more left to shift.”
Everyone in engineering wants to “shift left,” but the panel made clear that doing so at scale is not just a tooling problem. It is a people problem, a workflow problem, and a modeling problem. Companies may understand the need to simulate more, validate earlier, and co-design across domains, but many are still building the capability required to make that practical.
“Shift left” Meets Real-World Limits
That tension was especially clear in the discussion of multiphysics. Synopsys spent much of the event arguing that effects once treated as downstream concerns now have to be considered much earlier in the process, especially in AI superchips and advanced packaging. The panel gave that argument some real-world proof.
“We’re going from building a one-story house now to building a multi-story tower,” Subramanian said, referring to the chip industry’s move toward stacked and heterogeneous systems.
In autonomous vehicles, Mercedes-Benz VP of R&D Sundararajan Ramalingam described the challenge as even broader.
“Autonomous driving is one of the most complex systems that we have within the automotive,” he said.
He ticked through optic physics, thermal physics, sonar physics, electromagnetism, and voltage fluctuations, then cut to the heart of the matter:
“There is no way on the planet that we will be able to test it on the road against all corner cases,” he said.
Jean Boufarhat, VP and head of silicon, Reality Labs at Meta, brought the same point into consumer hardware. Building smart glasses, he said, means working across “material science,” “optical and display integration,” sensor technologies, audio, hearing, cameras, and battery constraints, all inside a form factor that a person would actually want to wear all day. In that context, co-design stops sounding like strategy jargon and starts sounding like survival.
Multiphysics Moves to the Front of the Process
Perhaps the strongest moment of the panel came from a concrete automotive story. Ramalingam described how a radar system had performed correctly in supplier testing and again in development vehicles. Everything looked release-ready. Then, late in the process, teams started seeing false braking events. Software was the first suspect. After deeper analysis, the issue turned out not to be the code at all, but a vehicle variant with metallic paint in a specific bumper design. The metallic particles were interfering with the radar’s behavior in ways that had not appeared earlier.
“Why could not we catch this in simulation?” he said.
That question landed harder than any product slide because it made the stakes obvious. It was not a theoretical argument for better tools. It was a real example of why modern systems have to be modeled more completely and much earlier. In a software-defined product, a physical material choice can quietly undermine sensor performance, trigger software-level consequences, and create a customer-facing problem late in the release cycle. That is the kind of systems problem Synopsys is trying to position itself around.
Its flagship answer at Converge was Multiphysics Fusion, the biggest technical story of the event. Ghazi described the value of the technology as “going from an over-designing to co-designing.” Krishnamoorthy went further, explaining that Synopsys is natively integrating engines for IR drop, thermal, and stress analysis into design and signoff tools like Fusion Compiler, PrimeTime, PrimeClosure, and 3DIC Compiler. The point is not merely to add more analysis. It is to pull that analysis into the mainline design loop earlier enough to reduce late-stage iteration, excess guard bands, and unnecessary performance or power sacrifices.
Krishnamoorthy described the benefit plainly.
“Much, much fewer iterations at the very end of the flow,” he said. He also argued that tighter native integration helps save PPA “because you are not margining so much in your design.” That matters in a market where advanced packaging, HBM integration, and system-level constraints are becoming central to AI infrastructure. Intel reinforced the point in a video appearance, saying, “Multi-physics analysis is critical to enabling advanced packaging,” especially as thermal, structural, and electromagnetic effects become more dominant in the angstrom era.
Digital Twins Expand Beyond the Physical Product
Converge’s second major product thread, the Electronic Digital Twin Platform, also aligned closely with what panelists discussed. Synopsys is trying to expand the meaning of a digital twin beyond the structure of a product and the environment around it. As Ghazi put it, modern products increasingly need a digital twin of the electronics, too.
For automotive in particular, the company described the platform as “the operating system that you need in order to design a digital twin for an autonomous vehicle.”
That is a bold framing, but the logic is clear. If software-defined products are going to evolve after shipment, and if system behavior increasingly depends on interaction among electronics, code, physical constraints, and environmental conditions, then development teams need something more than isolated simulations and physical benches. They need a platform that lets partners, silicon models, software-in-the-loop systems, and test environments come together in a reusable way.
The discussion of iteration and lifecycle learning gave that idea more weight. Citron argued that a digital twin can help teams optimize not only for performance, but also for sustainment and maintainability over time. In industries where products remain in the field for years, that becomes a strategic advantage, not just a design convenience.
Verification has to Evolve with the Workload
Verification was another area where Synopsys tried to stretch beyond a conventional EDA story. Across the keynotes, the company repeatedly described the burden of validating AI-era silicon and systems, with Krishnamoorthy estimating that teams may need “quadrillion” verification or validation cycles to gain enough confidence in increasingly complex software and hardware stacks. Synopsys’ answer is software-defined hardware-assisted verification: improving capacity, performance, and debugging through software innovation layered onto HAV systems, rather than relying only on hardware refreshes.
The most forward-looking part of Converge may have been the discussion around AI and engineering workflows. Synopsys has clearly moved beyond talking about AI only as an optimizer or assistant. Its road map now centers on more agentic workflows, and its executives used the event to argue that the next step is not just smarter tools, but a different operating model for engineering teams.
That theme surfaced forcefully on Allyson’s panel. Boufarhat described the shift as moving from “human in the loop” to “a person on the loop, an orchestrator rather than somebody who is actually tinkering and building every step along the way.”
Citron pushed the conversation deeper. If machines can iterate much faster than humans, he asked, then what becomes the role of the person, and “what does good look like?” That is a bigger question than it first appears. It suggests that engineering value may increasingly shift from manually executing every step to defining objectives, judging outcomes, and orchestrating more automated flows.
Subramanian added another layer.
“AI can’t be spoken about without the data strategy in the company,” he said.
Synopsys can build agents, assistants, and orchestration frameworks, but companies still need the underlying data, relationships, and institutional knowledge that make those systems useful. Without that foundation, AI becomes a demo. With it, AI starts to change how engineering work actually gets done.
The Bigger Test for the New Synopsys
The panelists were not naïve about the challenge. They talked about training, intuition, and the risk that earlier-career engineers may not develop deep systems judgment if more work is automated too early. They talked about needing deterministic tools in regulated domains like automotive. They talked about the need for courage in adopting workflows that will inevitably change roles and expectations.
That last point echoed Subramanian’s closing thought:
“Everything will happen faster than we think it’ll happen, and everything will be more disruptive,” he said.
Synopsys came to the event with a large portfolio story to tell, talking about Multiphysics Fusion, digital twins, software-defined verification, interface IP, AI-assisted design, and agentic workflows. But the real takeaway was not the number of announcements. It was the coherence of the larger argument. Synopsys is betting that AI-era products will force engineering teams to work across silicon, software, physics, and systems much earlier and much more tightly than before.
The pressure is already visible in autonomous driving, aerospace, consumer devices, and AI silicon. The challenge now is not just whether the tools exist. It is whether organizations can build the people, data strategies, and workflows needed to use them well.
That is the real opportunity, and the real test, for the new Synopsys.

The Orbital Cloud: You Have No Idea What’s Possible
In July 2022, Dominion Energy paused new data center connections in Northern Virginia’s Loudoun County - the grid couldn’t keep up. They’ve since resumed with reduced capacity, but the constraint is clear: data center demand jumped from 33 GW to 47 GW in less than a year, and the utility is scrambling with $50 billion in infrastructure upgrades.
This is “Data Center Alley” - 70% of the world's internet traffic flows through here. And it’s hitting limits. Dublin rejected a Google data center in August 2024 that would consume more electricity than all the city's homes combined. Singapore lifted its data center moratorium in 2022 but with strict sustainability requirements - approvals remain scarce. The pattern is global: data centers are growing faster than Earth can power them.
The bottleneck isn’t silicon anymore. NVIDIA’s Blackwell GB200 GPUs consume up to 1,200 watts per chip and require liquid cooling. At those power densities, facilities need entirely new electrical and cooling infrastructure just to turn them on.
By 2030, data centers will consume 10-12% of global electricity. That’s not a projection. That's physics meeting exponential demand.
The Conversation That Changed Everything
At Davos in January 2026, Elon Musk said something that made the room go quiet.
“The lowest cost place to put AI will be space. And that’ll be true within two years, maybe three at the latest.”
Not eventually. Not someday. Two years.
Six days later, SpaceX filed with the FCC. The application requested approval for up to 1 million satellites - not for internet, but for data centers. The filing called it "a first step towards becoming a Kardashev Type II civilization."
Musk posted on X: "I thought we'd start small and work our way up."
Jeff Bezos had been saying it quieter for years. Blue Origin's long-term goal isn't just space tourism - it's moving all heavy industry off Earth. “If you want a whole solar system full of people,” Bezos said in November 2024, “you need gigawatt-scale data center capacity in space.”
The billionaires aren't fantasizing. They’re solving a bottleneck that threatens to choke the AI revolution.
Why Space Actually Works
Here’s what changes when you leave Earth:
Solar panels in orbit receive 1,361 watts per square meter, 24/7. No night. No clouds. No winter. A data center on Earth might get 6-8 hours of equivalent sunlight daily - if it's sunny.
Heat rejection becomes trivial. Point a radiator at space - at 3 Kelvin, nearly absolute zero - and watch physics handle the cooling. No chillers. No water. No 40% power overhead just to keep servers from melting.
And launch costs? They've collapsed. What cost $20,000 per kilogram a decade ago now runs $2,700 on Falcon 9. Starship is targeting $100/kg. At that price, launching a 20-ton data center module costs $2 million - less than building equivalent capacity on Earth.
The physics always worked. Now the economics do too.
It's Already Happening
In November 2025, a startup called Starcloud - backed by Y Combinator and NVIDIA - launched a satellite carrying an H100 GPU. The first AI-optimized processor in orbit. It’s up there right now, running Google's Gemma language model, proving the concept works.
Google isn’t waiting either. Project Suncatcher launches in 2027 - two satellites carrying custom TPU chips that already survived five years of simulated radiation in a particle accelerator. Sundar Pichai's vision: 81-satellite clusters communicating at 1.6 terabits per second via laser links. “This will be normal within a decade,” Pichai said.
Lumen Orbit is building 20-ton modules with 500-kilowatt solar arrays. Axiom Space is launching station modules with data center capacity. Thales Alenia Space is developing "Secure Data in Space" for the European Space Agency.
The race isn’t starting. It started.
The Engineering No One’s Talking About
But here’s what the press releases don't tell you:
Nobody knows if robots can reliably repair a $50 million satellite when a $200 component fails. Nobody’s proven that commercial processors can survive years of cosmic ray bombardment with just error correction - or if we need expensive radiation-hardened chips. Nobody's built megawatt-scale radiator panels that deploy reliably in vacuum.
And then there are Silent Data Errors - when radiation corrupts data without triggering any error detection. These are “silent-enough on Earth but in orbit, bombarded by cosmic rays? They won’t be silent. They’ll be catastrophic.
The questions are specific and brutal:
- How many square meters of radiator per kilowatt of GPU processing?
- Can you cool a 50kW rack without air or water?
- What happens when a solar particle event fries half your memory?
- At what exact launch cost does space become cheaper than Earth?
These aren’t solved problems. They’re active engineering challenges that will determine if the Orbital Cloud becomes infrastructure or vaporware.
What's Coming
Over the next 12 articles, I’m going deep on the engineering, the real barriers between billion-dollar announcements and working data centers in orbit.
1. The Terrestrial Bottleneck - Why Earth's infrastructure can't scale with AI demand.
2. Engineering the Vacuum - Cooling megawatt GPU clusters without air or water.
3. The Robotic Workforce - Autonomous repair when humans can't reach your hardware.
4. Radiation Hardening - Surviving cosmic rays, solar particles, and Silent Data Errors that won't stay silent.
5. Orbital Edge Computing - Why processing data in orbit beats downlinking to Earth.
6. High-Yield Solar - Deployable arrays, eclipse management, power per kilogram.
7. Legal Frontiers - Data sovereignty beyond Earth's jurisdiction.
8. The Starship Effect - Launch economics: at what $/kg does space actually win?
9. Laser Backbones - Inter-satellite optical links building the Orbital Cloud.
10. Circular Sustainability - Recycling orbital hardware, avoiding e-waste 500km up.
11. Real-time Telemetry - Monitoring constellations with AI anomaly detection at scale.
12. The Multi-Planetary Cloud - Lunar data centers, Mars infrastructure, interplanetary internet.
Each article examines what’s different in space, what’s harder, and what becomes possible when you remove Earth’s constraints.
You Have No Idea What's Possible
As a certain goddess of death once said: “You have no idea what's possible.”
SpaceX filed for 1 million satellites. Google launches in 2027. An H100 is already orbiting above you.
The Orbital Cloud isn’t science fiction. It’s engineering happening now, and the engineering is everything.
Next: Part 1: The Terrestrial Bottleneck

AI Infra Summit Steps into the Arena to Ignite the Industry
TechArena is proud to announce its role as a media partner for the AI Infra Summit, the full-stack AI and ML infrastructure event bringing together hardware providers, hyperscalers, and enterprise practitioners under one roof. This September, 8,000 of the industry’s leading builders, buyers, and decision makers will gather for the summit at the Santa Clara Convention Center—and TechArena will be there with them, in the room and on the platform.
This partnership is a natural one. In nine years, the AI Infra Summit, run by Kisaco Research, has grown from a niche event into a hub for the industry: a meaningful, technical event where the conversations that happen between sessions are as valuable as the ones on stage. TechArena was founded on exactly that instinct: that the most important insights in technology happen when practitioners and innovators have a space to share their ideas. The AI Infra community is our community.
What This Partnership Means in Practice
Starting this spring, TechArena will integrate AI Infra Summit content and coverage into our editorial calendar and work directly with the event’s exhibitors and sponsors to amplify the discussions that they’ll be driving in Santa Clara. That means pre-event content that builds awareness and drives the right conversations before attendees ever arrive, real-time coverage from the floor, and post-event distribution that keeps the ideas in motion.
AI infrastructure is the foundational layer on which everything else gets built, and the pace of investment, vendor selection, and architectural decision-making has never been faster. The AI Infra Summit draws companies representing every layer of the stack alongside hyperscaler attendees and enterprise practitioners actively evaluating vendors and budgeting for infrastructure upgrades.
Events like AI Infra Summit are where that decision making gets accelerated. TechArena exists to make sure those conversations don’t stop when the badges come off.
Free Tickets and Discounts from TechArena
As part of our partnership, we’re pleased to offer benefits to our TechArena followers who want to join the conversation in Santa Clara this fall:
- Free expo tickets (valued at $447) are available to qualified individuals working within the AI infrastructure field. Apply for free expo tickets.
- A registration discount is available for full access and VIP tickets. Quote TECHARENA15 on the registration page to save 15%.
What’s Next
Look for TechArena editorial coverage of AI Infra Summit in the months ahead. We’ll be publishing practitioner-focused content, spotlighting the innovations that will be on the expo floor, and giving our community early visibility into what’s shaping up to be one of the most consequential gatherings in the AI infrastructure calendar.
If you’re exhibiting at the AI Infra Summit and want to talk about how TechArena can help amplify your presence, reach out directly. There’s no boilerplate here: every engagement starts with a conversation.
We’ll see you in Santa Clara.

2026 AI M&A: The Great Shift from Models to Infrastructure
As Q1 2026 winds down, the AI industry is undergoing a turbulent structural realignment, pivoting from a race for smarter models to a desperate land grab for the power, pipes, and provenance that make them functional.
If the last two years were defined by the “Model Wars,” as enterprises sprinted to produce the most capable large language model (LLM), 2026 is emerging as the year of vertical integration and middleware dominance.
The era of experimental pilots is over. Major tech incumbents and specialized neoclouds are no longer just buying intelligence; they are acquiring the infrastructure required to turn that intelligence into a functional enterprise operating system.
2026 AI Acquisition & Funding Tracker

Analysis: The Three Pillars of 2026 M&A
1. The Rise of Sovereign AI (Nscale & Future-tech)
The concept of Sovereign AI has moved from a policy aspiration to a massive commercial driver. With the UK and Canada actively funding domestic AI stacks, neoclouds like Nscale are seeing record valuations. Nscale’s $2 billion Series C is fueled by its ability to build AI factories that comply with local data residency laws, a mission bolstered by its 2025 acquisition of Future-tech, which gave it the in-house engineering muscle to design facilities faster than traditional hyperscalers.
2. The Orbital Escape (The SpaceX/xAI Merger)
Perhaps the most audacious deal in tech history, the merger of SpaceX and xAI values the combined entity at $1.25 trillion. The strategic rationale is purely physical: terrestrial data centers are hitting power grid limits. By merging with SpaceX, xAI aims to move massive training and inference workloads to orbital, solar-powered data centers, effectively leveraging the infinite square footage of outer space. (Stay tuned for a series about data centers in space from TechArena Voice of Innovation Niv Sundharam).
3. The Social Infrastructure of Agency: Meta Acquires Moltbook
The shift from isolated chatbots to social participants was cemented today, with Meta’s confirmed acquisition of Moltbook. Moltbook is an AI-agent social network designed specifically for autonomous systems to interact, share context, and coordinate tasks. By folding founders Matt Schlicht and Ben Parr into Meta’s AI division, the company is securing the social layer of the agentic era. This move signals that the next phase of competition isn’t just about how smart an agent is, but how effectively it can collaborate within a broader network.
The TechArena Take
We are witnessing the industrialization of intelligence.
For the past two years, the industry has been focused on the brain (the LLM); today, the focus has shifted to the nervous system and the skeleton. The rush to acquire middleware giants like Confluent and safety frameworks like Promptfoo proves that the “model moat” has evaporated.
In its place, a new barrier to entry is forming: architectural integration. Companies that can seamlessly connect real-time data to autonomous agents while maintaining a “moat of trust” will dominate the second half of this decade. For startups, the integration gap has expanded; if your product only identifies an AI problem without possessing the infrastructure to fix or govern it in real-time, you are an acquisition target, not a platform.

Betterworks: Turning AI Hype Into Enterprise SaaS at Scale
Maher Hanafi of Betterworks joins TechArena Data Insights to discuss AI in enterprise SaaS, why many AI proof-of-concepts fail, and how engineering leaders can successfully move AI into production.

Solving the Internet’s Single Point of Failure: CDN Resilience
Cloud expert Venkata Gopi Kolla joins Allyson Klein to discuss the CDN "single point of failure" and a new IETF protocol for sub-second edge recovery and AI correctness. A must-listen for infrastructure leads.

How Hedgehog Brings Hyperscaler Agility to Any AI Infrastructure
As organizations build private AI clouds to control costs and protect their data, they face a familiar dilemma: the trade-off between performance and operational simplicity. Hyperscalers (like AWS or Google) have both, but only because they have armies of engineers to build custom software that tames their hardware.
My recent conversation with Solidigm's Jeniece Wnorowski and Marc Austin, CEO and co-founder of Hedgehog, revealed how enterprises can now access that same "Hyperscaler Agility"—without the army of engineers.
The key? Decoupling the control plane from the hardware.
The Hyperscaler Playbook for Everyone
Hedgehog’s mission centers on enabling enterprises, government agencies, and neoclouds to “network like a hyperscaler.” This means moving beyond rigid trade-offs. Instead of being forced to choose between the stability of validated reference architectures or the flexibility of open standards, Hedgehog allows organizations to leverage both, orchestrated by a single software platform.
This approach offers a massive strategic advantage: Supply Chain Resilience.
As Marc explained, a diversified hardware strategy is critical for risk management. “If you have a supply shock—like a global pandemic or a trade war—that can limit your ability to scale because supply becomes constrained,” he noted. “You can’t add capacity to your network when you need to.”
By running open-source software on OCP standards-based servers, organizations can acquire equipment from whichever vendor offers the best price and availability at that moment. And because Hedgehog’s control plane is hardware-agnostic, it can eventually extend this same flexibility to other high-performance reference architectures, ensuring that the software experience remains consistent regardless of the underlying silicon.
Automating the "Network Appliance"
Hardware diversity is only half the battle; the other half is operational speed. Hedgehog delivers all the software needed to automatically install, configure, and operate AI networks as a turnkey "appliance." This eliminates weeks of manual configuration work by network architects.
More importantly, it democratizes access. By providing a Virtual Private Cloud (VPC) service, Hedgehog allows enterprise users or neocloud tenants to operate within a private, secure segment—consuming on-premise AI infrastructure with the same self-service ease they expect from a public cloud provider.
Real-World Agility: Zipline & FarmGPU
The power of this "Universal Control Plane" is evident in how customers are using it to bypass traditional infrastructure bottlenecks.
Zipline, an automated drone delivery company, utilized Hedgehog to build a private cloud that cut infrastructure costs by 70% while keeping their delivery data secure. The critical win wasn't just the hardware savings—it was the operational model. They managed the deployment with their existing DevOps team, without hiring specialized network engineers, because Hedgehog abstracted the physical switching complexity into simple software commands.
In the high-performance arena, FarmGPU (operating the Solidigm AI Central Lab) used Hedgehog to orchestrate an 800G fabric for AI training. Independent testing by SemiAnalysis highlighted that Hedgehog’s software-defined congestion management maximized bandwidth and GPU utilization.
This proves a vital point for the future of AI: The software you use to manage the network matters just as much as the wire itself.
Solving the "Gateway Problem"
Agility isn't just about the switch fabric; it's about how data enters the building. FarmGPU faced a challenge familiar to many AI operators: ingesting terabytes of training data through a limited enterprise firewall.
Legacy solutions required expensive, proprietary hardware routers. Hedgehog’s software-defined gateway turns standard x86 servers into high-performance routers. This effectively brings the functionality of a public cloud "Transit Gateway" on-premise, allowing secure, multi-tenant segmentation for AI workloads.
The TechArena Take
Hedgehog is redefining the role of the network in the AI stack. By focusing on a hardware-agnostic control plane, they are ensuring that the "Brain" of the network (the automation) is distinct from the "Body" (the switch).
This is the architecture of the future. It gives enterprises the ultimate luxury: Choice. It allows IT leaders to select the best hardware for their specific workload—optimizing for cost, performance, or supply chain availability—while maintaining a consistent, automated operating experience across the entire fleet.
For organizations that view data as their competitive moat, this ability to unify diverse infrastructure under one automated standard is the key to scaling AI.

Particle Physics Powers Quantum Computing’s Future at Fermilab
In the race for advancing technology, time, funding, and attention are often dedicated to immediately monetizable applications. While industry roadmaps certainly drive technological advancement, basic science, which forwards our fundamental understanding of the universe, can create breakthrough findings with wide-reaching applications and effects.
My recent conversation with Silvia Zorzetti from Fermilab and Solidigm’s Jeniece Wnorowski revealed how such research into the convergence of high-energy physics and quantum technology is creating outstanding developments for quantum computing.
From Colliders to Qubits
As a U.S. particle accelerator laboratory, Fermilab has spent decades perfecting superconducting cavities that accelerate particle beams to near light speed. Through years of study, researchers at the lab have identified several sources of noise that can make these superconducting cavities less efficient, and they have worked to eliminate those sources of loss.
In 2017, researchers began studying these same cavities at the quantum level. As Silvia explained, at this single photon level, the energy is much lower, which means there are new potential sources of loss compared to the higher energy levels. “We can focus on the basic science and the basic understanding of those mechanisms,” Silvia explained.
At the same time, Fermilab is finding ways to transform superconducting cavities to be efficient for quantum computing. By placing qubits inside the cavities, Fermilab has achieved 20 milliseconds of coherence. That coherence time represents a critical advance in the typical rapid decay time of quantum information. “And we know that it is possible to achieve more coherence,” Silvia said.
Quantum Computing’s Sweet Spot
Quantum computers won’t replace classical computers for all tasks. The technology excels at specific problems, including the Shor algorithm for prime number factorization and Grover’s algorithm, a quantum algorithm for unstructured search. As the threats to digital security grow, the Shor algorithm is of extreme interest because of its efficient ability to factorize prime numbers, a process that is very important for cryptography. “This means that we can have systems that are very secure because they cannot be broken by someone else with a more advanced cryptography system, let’s say an alien, because here on Earth, we all have to comply with the quantum mechanics rule,” she explained.
Beyond these practical applications, quantum computing excels for quantum simulations for field theories, which involve many interacting components. “We have these huge many body problems in which there are so many entities. We know how to describe them if they are alone,” Silvia explained. “But then when they start to interact to each other, it becomes a very complex model. So, we know that quantum computing is very good for those kinds of applications.”
Roadmap Challenges
While quantum computing has seen great progress, challenges remain to realizing its full potential. Silvia identified two types of hurdles to be overcome: “engineering problems,” where technical challenges are understood and need to be addressed, and problems where more fundamental research is required.
“Those are mainly between the interconnects,” she said. “The interconnects are needed for scaling quantum computing…and in particular, interconnects with very low losses.” Quantum information is a weak signal, so research to find solutions that will prevent the loss of this information remains a priority.
Quantum error correction presents another major hurdle. Quantum states are inherently fragile, and errors can arise in quantum information due to decoherence and other issues. The community is developing algorithmic techniques that make computations more robust to noise, while simultaneously working on hardware improvements.
The Promise of Quantum Sensing
The environmental sensitivity that creates problems for quantum computing is actually an advantage for quantum sensing, which is already delivering results. Fermilab is leveraging this sensitivity to detect dark matter, dark photons, and axions. It is also studying radiation, like the gamma ray, to understand better how these affect quantum computers, and how quantum computers could be built that are robust to radiation.
The TechArena Take
Fermilab’s approach to quantum computing demonstrates how domain expertise from one field can catalyze breakthrough innovations in another. By leveraging decades of superconducting cavity development for particle accelerators, the laboratory has achieved amazing quantum coherence times. The pursuit of fundamental knowledge about how materials behave at the quantum level has yielded practical breakthroughs that are now accelerating the entire field forward.
For those interested in learning more, Fermilab hosts regular symposiums and outreach programs, including their Quantum 101 track designed for non-experts. Learn more about Fermilab’s quantum research at fnal.gov.

The Future of Software Development: From Mechanics to Meaning
Software development has matured over the years but fundamentally still comes down to beating your head against the wall while figuring out the art of giving directions to a machine that, at its foundation, “speaks” in on and off switches. The computers powering NASA in the race to the moon required punch cards that were literal stacks of paper fed into a machine, where the presence or absence of a hole represented a code translated into an electrical signal. A deck of punch cards represented a program. Later, programmers became experts in binary code and firmware until the introduction of high-level language compilers. Ironically, compilers and increasingly higher levels of programming languages led some to predict the demise of the art of software programming itself.
Since December 2025, there has been a lot of marketing and PR from AI model companies that "software engineering is dead" because of their internal experience in consuming their own AI tools for writing software. While researching that statement, I confirmed that the same AI model companies continue to post healthy numbers of job openings on their career sites for software engineering roles. How can both of these things be true? I believe the answer can be found going back into the history of computing, where many dire predictions were made about the disappearance of engineering and management jobs - yet today those professions continue to evolve and grow.
The User Interface – Open Claw
We were overdue for a major update in how humans interact with machines, given the maturity of web-based design. Punch cards gave way to compilers and command lines, then to the GUI and web interfaces, and later to mobile. Each progression was revolutionary compared to how interaction worked in the prior generation. For example, web design and search engine optimization were refactored once mobile phone interfaces and app stores began to dominate customer experiences.
The original GenAI chatbots were seamless because web interfaces and mobile computers were already ubiquitous. But they weren’t the breakthrough that brought us closer to the dream of harnessing computing to help with nagging, annoying tasks. Interfacing with and harnessing the computer continued to be the nagging, annoying task, requiring proficiency in rote learning and grinding through lines of code.
Apple has a long history of shaking up the computing industry through breakthroughs in how we interact with devices—from the first Apple computer with a graphical user interface to the iPod, iPhone, and beyond. Open Claw represents a breakthrough because operating it does not depend on the old modes of human–computer interaction that chatbots required. There are many downsides related to security and vulnerabilities, but that isn’t the point. For meaningful differentiation in software solutions, finding ways to interact with users the way they want—rather than the way software developers envision—will be sustainable differentiation.
There are opportunities for an Open Claw–like corporate offering that includes lifecycle management, auditing, and governance-as-code, with built-in FinOps to ensure there are no unpleasant budgeting surprises from token usage.
Mechanics vs. Meaningful Differentiation
For the last 15 years, discussion forums like Reddit and Blind have been packed with prospective developers looking for the recipe for the fastest path into one of the “FAANG” companies. How many Big Tech parents pushed their kids into coding and robotics clubs to set them up for a career in SaaS? The goal often seems to be: get in, suck it up, work at a relentless pace, watch your stock go up, cash out, and move to the next rung.
As long as companies needed armies of developers to work in a production line—one that LeetCode could prepare you for—the assembly line from code camp to university to long-term employment at a large software company ran smoothly. GenAI and coding tools have been rattling these markets, and I’ve lost count of the social media influencers who have preached, “You won’t be replaced by AI; you’ll be replaced by someone using it,” especially to software developers over the last three years.
To those who believe that learning the mechanics of AI coding tools faster than the other 90% of equally panicked peers is the path to safety—as if it’s another “ace interviews at Google” course—here’s the reality: your use of AI tools is not a sustainable differentiator between long-term employment and becoming a bartender. CEOs—many of whose admins still print emails for them to read—may tell you that using AI tools is the goal and that you should start working with them or else. Tool usage and leverage are not sustainable differentiators, even if they serve as a short-term sifting mechanism.
Speed in the mechanics or methods of producing software is now a baseline, but it does nothing to explain why that work is worth doing in the first place. Software development has a long history of ever-higher levels of abstraction that demand more compute power but deliver better scale, faster feature development, and improved debugging. The increased efficiency of how humans direct machines isn’t interesting to anyone outside the tech industry unless it materially improves business outcomes for customers.
Yes, learn AI coding tools—they are the next level of abstraction in a long history of attempts to relieve developer frustration from grinding out lines of code. But for your own sake, learn them while working on problems that matter, and do it in a maintainable, enterprise-ready way.
Think Like an Owner - Make/ Buy/ Differentiate
There are so many AI tools and applications competing for business and there are equal numbers of non-developers working with coding tools. For software engineers who have ideas but no experience doing market research, there are now ready made research support systems from multiple vendors to help vet and verify the market opportunity for your idea. The fact that you do not have to pitch the idea through management to ensure a 100 person coding team gets assigned to develop the first version is both freedom and frightening. You are no longer held back by business analysis - just your decision on what to make or buy and how you take it to market. For non technical business owners who have AI products pitched to you nearly round the clock, focus on where you want your business to be unique and where you want to offload mechanics that are for you a chore or cost that is a necessity.
While there are many decision frameworks around when to make or buy AI, AI agents, AI management platforms and AI applications, very few of the frameworks look at how to balance ease of use with long term supplier oversight and management. The decision is not just a technology skill question but needs to focus on whether your supplier will change access to their technology or whether the supplier has to change pricing models because their board or shareholders demand margin improvements. Talking to small and large enterprises, I find that the focus is on technology sustainability for mid to large companies who have access to technical skills - but perhaps more focus is needed on FinOps for AI where autonomous agents are being scaled. At smaller companies I advise, I find that the decisions start from a financial lens but could use structured thinking around long term differentiation - where does the owner or leader need to own or retain a key capability to set their business apart in the minds of their customers.
The next few articles in the series will walk through at a deeper level some of the decision tradeoffs, strategic questions and frameworks I have used to drive clarity for major decisions customers and partners have faced.

Scaling Multilingual GenAI with Ishween Kaur
Ishween Kaur, Generative AI Lead at Salesforce, shares practical lessons on building multilingual AI systems, closing language gaps, and scaling with trust and real-world feedback.

The New Enterprise AI Runtime: What Really Runs Beneath the Model
Enterprise AI conversations still revolve around models. Benchmarks, context windows, and release cycles dominate the discussion.
But inside production environments, the real shift is happening elsewhere.
The competitive advantage in enterprise AI is moving away from model selection and toward the runtime architecture that surrounds it.
Once AI leaves the demo environment and enters core workflows, it must be governed, monitored, cost-controlled, and made resilient. That is not a model problem. It is an operational one.
From Pipelines to Context Engines
Traditional enterprise systems were built around deterministic pipelines. Data moved from source to warehouse to dashboard. Outputs were reproducible. Monitoring focused on throughput and uptime.
AI systems depend on something different: dynamic context.
Large language models (LLMs) rely on embeddings, retrieval layers, policy documents, customer history, and transactional signals that are often refreshed on tight cycles. When that context degrades, output quality degrades.
In production deployments, many perceived model quality issues are actually context failures:
- Stale embeddings
- Incomplete retrieval scopes
- Delayed ingestion cycles
- Missing domain ownership
The architecture therefore shifts from static data pipelines to context engines. These systems are designed around freshness service level agreements (SLAs), versioned vector stores, and controlled retrieval boundaries.
The model generates the answer. The context determines its reliability.
From Access Control to Behavioral Guardrails
Earlier governance models focused on who could access a system. AI introduces a different challenge: how the system behaves once accessed.
Outputs are probabilistic. Prompts vary. Users experiment. Sensitive data can surface in unexpected ways.
Modern AI runtimes increasingly include:
- Prompt filtering layers
- Output moderation services
- Personally identifiable information (PII) redaction pipelines
- Policy-aware orchestration logic
- Token ceilings by business unit
Consider a financial services copilot assisting relationship managers. A user asks for a client summary. The model has access to customer relationship management (CRM) notes, transaction data, and compliance documentation.
Without behavioral guardrails, the system could:
- Surface internal risk ratings not meant for disclosure
- Generate speculative language about client suitability
- Exceed approved advisory language
The runtime must intercept, evaluate, and shape responses before delivery.
Governance is no longer static access enforcement. It becomes active runtime mediation.
From Predictable Infrastructure Spend to Usage Volatility
Traditional infrastructure cost planning followed relatively stable patterns. Workloads were forecastable. Capacity was provisioned accordingly.
AI inference introduces volatility.
Token consumption fluctuates based on prompt size. Adoption spikes increase inference load. Copilots embedded into daily workflows can quietly multiply request volumes.
Enterprises are responding by embedding cost awareness into the runtime layer:
- Model routing, using lightweight models for simple queries and premium models for complex reasoning
- Response caching strategies
- Tiered inference placement, internal endpoints versus external application programming interfaces (APIs)
- Real-time token dashboards
- Cost attribution per workflow
Without runtime-level cost instrumentation, AI initiatives can scale faster than financial oversight.
In this environment, cost architecture is structural.
From System Health to Decision Health
Traditional observability focuses on infrastructure metrics such as central processing unit (CPU) utilization, memory pressure, and latency.
AI systems require something more nuanced. A model can respond quickly and consistently while producing degraded or risky decisions. Decision health expands observability into the quality and impact of AI outputs.
In practice, this includes monitoring:
- Output drift over time
- Confidence scoring thresholds
- Hallucination frequency patterns
- Fallback invocation rates
- User correction frequency
- Escalation triggers to human review
If an AI assistant’s recommendations are increasingly overridden by users, the system may be technically healthy but operationally degrading. A rise in fallback activations may signal retrieval gaps or tightening policy enforcement.
AI systems are not just infrastructure components. They are decision amplifiers. Observability must reflect that reality.
A Production Pattern Is Emerging
Across industries, a common architecture is taking shape beneath enterprise AI deployments. Organizations are building structured data backbones, versioned embedding layers, policy-aware orchestration engines, guardrail services that mediate outputs, integrated cost monitoring tied directly to request routing, and decision-level observability with full audit trails.
The visible model can change. The runtime scaffolding persists.
Over time, the reliability, governance posture, and economic efficiency of that runtime determine whether AI systems become trusted infrastructure or remain isolated pilots.
The Real Differentiator
Models will continue to evolve. Benchmarks will continue to shift.
Inside enterprise environments, models are becoming modular components.
The durable advantage lies in the architecture that governs them. The runtime manages context freshness, enforces policy, instruments cost, and monitors decision integrity.
Enterprise AI is no longer just a capability layer. It is an operational layer.
As with every operational layer before it, organizations that engineer it with discipline, not enthusiasm, will outperform those that treat it as novelty.
The future of enterprise AI will not be defined by who selects the best model.
It will be defined by who builds the most resilient system around it.

VAST Data Accelerates Agentic AI at VAST Forward 2026
At VAST Forward 2026, VAST Data expanded the view of its ambitions for its AI operating system. The company dropped five major announcements in a single day: new agentic AI capabilities, a fully accelerated hardware stack built with NVIDIA, a global infrastructure control plane, a video intelligence partnership, and a formalized partner ecosystem. Taken together, they represent a vision of what enterprise AI infrastructure looks like when it stops being a collection of components and starts behaving like a unified, intelligent system.
Building the Thinking Machine: PolicyEngine and TuningEngine
The marquee announcement was the unveiling of two new capabilities of the VAST AI Operating System, VAST Data PolicyEngine and VAST Data TuningEngine. These two new services, slated for release by end of 2026, are designed to work in tandem inside the VAST DataEngine to create what the company calls a “thinking machine” — a system that doesn’t just execute AI pipelines but governs them, evaluates them, and improves on them automatically.
PolicyEngine functions as an inline enforcement layer for agentic workflows, applying fine-grained, tamper-proof controls on what agents can access, what tools they can invoke, and how they communicate with other agents. TuningEngine captures outcomes from those workflows and feeds them into fine-tuning pipelines using methods like LoRA, supervised fine tuning, and reinforcement learning, automatically generating candidate models for evaluation and deployment.
The result is a closed operational loop: observe, act, evaluate, improve. VAST co-founder Jeff Denworth framed it plainly: “Just as people are always learning, so should tomorrow’s applications.” For enterprises trying to deploy AI in regulated or mission-critical environments, the combination of zero-trust governance and automated model improvement in a single platform is a major step toward trusted, autonomous systems.
NVIDIA Collaboration Puts Acceleration Inside the Stack
The software story gets hardware muscle through an expanding collaboration with NVIDIA with an end-to-end, fully CUDA-accelerated AI data stack. The companies introduced CNode-X, a new class of NVIDIA-Certified servers that run the VAST AI Operating System directly on GPU-powered infrastructure. The deeper integration embeds NVIDIA libraries—cuVS for vector search, cuDF-based SQL acceleration via an engine called Sirius, and support for NVIDIA’s Context Memory Storage (CMX) platform—directly into VAST’s core data services.
The goal is to eliminate the fragmented stack problem: separate storage, database, and AI compute tiers that slow enterprise AI pipelines from pilot to production and add operational complexity at every seam. In doing so, it clears the path for agentic AI-enabled workloads to fulfill their promised potential. “CNode-X is CUDA-accelerated at every layer to give AI agents persistent memory so they can work on complex problems over days or weeks, and eventually years, without forgetting—opening the world to the next frontier of AI,” said NVIDIA Founder and CEO Jensen Huang.
CNode-X will come to market through OEM partners, including Cisco and Supermicro, giving enterprises a path to GPU-accelerated VAST infrastructure through vendors they already buy from.
Polaris Solves the Multi-Cloud Management Mess
VAST also announced Polaris, a global control plane purpose-built to provision, operate, and orchestrate distributed AI infrastructure across public cloud, neocloud, and on-premises environments. As AI pipelines span regions and providers between data collection, training, and inference, Polaris offers a centralized service delivery that converts disparate infrastructure instances into one operational environment.
Polaris is built on a Kubernetes-based architecture with a lightweight agent on every VAST node and operates as an intent-driven management layer. Administrators define the desired state of infrastructure, and Polaris coordinates the cloud-native services and VAST software to get there and keep it there. It supports cloud service provider partners, sovereign deployments, and multi-site, multi-cluster configurations under centralized management. It is available as part of VAST cloud deployments.
Video Intelligence Gets a Sovereign Deployment Path with TwelveLabs
VAST’s announced partnership with TwelveLabs, which develops video foundation models, introduced a partnership to help organizations extend video intelligence beyond public cloud deployments. Through the collaboration, the companies will support demand for deploying advanced video intelligence closer to where the data originates and is governed. The pitch is squarely at enterprises and government agencies sitting on massive video archives that can’t or won’t push data to a hyperscaler: media companies, financial services firms running surveillance-based fraud detection, and public sector agencies where data sovereignty is non-negotiable. TwelveLabs gains a deployment path into on-prem and neocloud environments, and VAST gains a compelling vertical use case to anchor its platform story.
Cosmos Gets a Real Partner Program
Finally, VAST formalized its Cosmos partner ecosystem into a unified global partner program, consolidating resellers, system integrators, independent software vendors, cloud providers, and advisory partners under a single framework with structured onboarding, tiered benefits, deal registration, and a centralized partner portal. Cosmos offers a clear engagement model for each partner type, from hardware platform partners validating architectures to consulting firms running deployment practices. H2O.ai and WWT are among the early participants.
The TechArena Take
Today’s announcements represent the most concrete evidence yet that VAST is building out its “thinking machine” vision a coherent, layered way, and is doing so with the right partners. The strategic logic is sound: if AI pipelines are becoming continuous, always-on systems, then the infrastructure layer needs to behave like an operating system—governing, learning, and adapting in real time. PolicyEngine, TuningEngine, and Polaris are all designed to elevate the company’s AI OS position.
Meanwhile, its work with TwelveLabs, the formalization of its partner ecosystem, and the CNode-X collaboration with NVIDIA demonstrate that VAST is assembling a coalition to maximize its reach and impact. Each partnership extends VAST’s reach into a different part of the enterprise buying process, including technical validation, vertical use cases, and channel distribution. Together, they suggest a company that understands the AI OS can’t succeed alone.

Brookfield Bets on Sovereign AI With Radiant and Ori Deal
Brookfield Asset Management has officially launched Radiant, a vertically integrated AI infrastructure company, through its acquisition of Ori Industries, a UK-based distributed AI cloud provider. The announcement marks the transition of Radiant from concept to active operations and signals a significant bet in the AI infrastructure space.
Radiant enters the market as one of the first bets from Brookfield’s AI Infrastructure Fund (BAIIF), which itself serves as the anchor for a broader $100 billion investment program. Financial terms of the Ori acquisition were not disclosed.
What Radiant Actually Is
As it launches, Radiant is targeting the delivery of high-performance, purpose-built AI compute to sovereign governments, telecom providers, and select large enterprises under long-term contracts.
Radiant will expand on Ori’s existing integrated AI Cloud assets, which operate out of more than 20 data centers around the world. The new infrastructure will be built on the NVIDIA DSX reference design, NVIDIA’s blueprint for what it calls AI factories, making Radiant an NVIDIA Cloud Partner. That designation matters because NVIDIA’s DSX architecture, which is designed to be Vera Rubin–ready, provides a standardized, scalable foundation for high-throughput AI workloads.
Alongside the long-term contract business, Radiant will continue to operate the Ori Global AI Cloud, a GPU-as-a-Service platform Ori built over seven years, for customers that need on-demand capacity and rapid deployment.
Brookfield’s head of AI infrastructure, Sikander Rashid, described the model plainly: “I think of it as a leasing business.” Radiant structures contracts to lock in revenue across the estimated five-year useful life of a chip cluster, with investment-grade customers committed to pay regardless of utilization. Brookfield has been explicit that it will not be taking on technology obsolescence risk in this model.
Energy as a First Principle
One differentiator Radiant is emphasizing is vertical integration that extends all the way to energy. AI compute is an energy consumption problem, and Brookfield’s existing portfolio includes power utilities and renewable generation assets.
Radiant’s ability to pair data center operations directly with behind-the-meter power generation represents a structural cost and reliability advantage. In a blog published with Radiant’s launch, Head of Product João Coelho noted, “Our behind-the-meter model co-locates AI Factories directly with massive-scale hydro, wind, solar, or nuclear generation. This is not an optimization of the datacenter; it is a re-architecture of the entire supply chain.”
Sovereignty as a Business Model
A growing number of national governments require that AI workloads processed on their behalf remain within their borders, and Radiant is explicitly positioning itself to meet that demand. Its sovereign framework is designed to go beyond simply deploying compute in-country.
As Radiant CMO Jonathan Symonds said, “Compute sovereignty depends on ownership of the supply chain: land, power, and capital.” Radiant plans to address all of these elements.
In terms of the technology, that means air-gapped control planes, hardware-rooted security, and single-tenant bare metal configurations that ensure sensitive datasets and model weights remain invisible to external parties, including Radiant’s own engineers. Open-weight model architectures are supported to reduce dependence on any single vendor’s proprietary stack.
The capital structure reinforces the sovereign pitch. Radiant argues that most AI infrastructure has been financed with short-term, high-cost capital—venture equity or private credit carrying hurdle rates around 20%—which creates incentive structures poorly suited to the stable, long-duration assets that national AI programs require. By financing at infrastructure-grade rates of approximately 5%, Radiant contends it can offer sovereigns compute offtake contracts of 3, 5, or 10 years with predictable, hedgeable pricing.
The TechArena Take
The launch of Radiant is a meaningful development in AI infrastructure. Sovereign governments and large enterprises increasingly want AI compute that is predictable in cost, physically located in-country, and not delivered by a US hyperscaler carrying geopolitical and data residency complications.
Radiant is designed precisely for that buyer. With long-term contract structures, NVIDIA-validated architecture, and the energy integration to underpin reliable operations, Brookfield has assembled a credible stack.
The risk, as with any infrastructure-scale bet, lies in execution timing. AI chip generations turn over quickly, demand patterns from sovereign customers are still maturing, and $100 billion programs are easier to announce than to deploy. Brookfield’s contractual approach—locking customers into full payment regardless of utilization—reduces its downside but will require winning and maintaining the confidence of investment-grade counterparties in a competitive market.
Still, the resource moat is significant. Very few organizations can bring Brookfield’s combination of infrastructure experience, energy assets, and long-duration capital to bear on a compute leasing business. If the sovereign AI infrastructure market develops the way Brookfield is betting it will, Radiant will be well-positioned. Technology leaders evaluating AI infrastructure partnerships should pay close attention to what Radiant builds in its first 18 months of operation. As of today, the proof of concept is underway.

Quantum Threats Meet the Connected Car
Back in November 2024, I wrote a blog which discussed the implications of cybersecurity in automotive. In that blog, I outlined some of the efforts and frameworks that have been established to address this evolving field as it applied to automotive while highlighting the ISO 21434 cybersecurity framework.
With the advent of quantum computing, which promises to bring to deliver far greater computing performance than previously imagined, existing cybersecurity solutions are expected to be at risk once Cryptographically Relevant Quantum Computer (CRQC) become available. While a CRQC is not widely expected before 2029, the importance of recognizing and addressing this new form of cybersecurity attack today cannot be overstated. As an update to my previous blog, it seemed appropriate to explore the potential impact of Post Quantum Cryptography (PQC) on next-generation vehicles and the approaches and considerations that must be taken to address this looming threat.
From Connected Cars to Cryptographic Risk

While automotive OEMs race to deploy Software Defined Vehicles (SDV) with sophisticated connectivity, artificial intelligence (AI), and Over-the-Air (OTA) update capabilities, quantum computing, once confined to research laboratories, is rapidly approaching commercial viability, and with it comes the harsh reality of cryptographic obsolescence. Post Quantum Cryptography (PQC) represents the industry's attempt to address this looming threat, yet its implementation presents challenges as complex as the vehicles it aims to protect. For an industry already grappling with ISO 21434 compliance and the expanding attack surface of connected cars, the transition to quantum resistant security cannot be an afterthought.
PQC refers to a new generation of cryptographic algorithms that were designed to withstand attacks from both classical and quantum computers. Public key systems currently in use such as RSA and ECC (Elliptic Curve Cryptography), which have been effective to date, are based upon the premise that the available computing resources were insufficient to crack these codes. With the arrival of CRQC, today’s public key systems are expected to be readily cracked, fully compromising today’s security infrastructure.
Unlike current public key systems such as RSA and ECC which rely on mathematical problems that quantum computers can solve exponentially faster, PQC algorithms are built upon hard mathematical problems that are believed to remain difficult to solve even for quantum systems. These include lattice-based cryptography, hash-based signatures, and multivariate polynomial equations. The National Institute of Standards and Technology (NIST) has begun standardizing these algorithms, with CRYSTALS-Kyber for key encapsulation and CRYSTALS-Dilithium for digital signatures emerging as primary candidates. As a quick explanation, the key exchange mechanism can be considered a “secret encoder and decoder ring” that is used to encrypt and decrypt the message, whereas digital signature ensures that the encrypted messages are coming from a trusted, known source. For automotive systems, the transition to PQC isn't merely an upgrade, it's a fundamental architectural transformation.
Harvest Now, Decrypt Later: Why Timing Matters
The urgency to address this looming problem stems from a phenomenon security professionals call “harvest now, decrypt later.” Adversaries with access to quantum capabilities in the future could capture encrypted vehicle communications today and store them for decryption once quantum supremacy arrives. Given that vehicles remain operational for 15 to 20 years, data transmitted through V2X communications, OTA update channels, and telematics systems in 2024 could be vulnerable to retrospective decryption in 2035. The automotive supply chain compounds this risk; cryptographic vulnerabilities in Tier 2 or Tier 3 components may not manifest until years after deployment, creating liability exposure that extends across decades and multiple ownership transfers.
The attack surface for quantum-enabled threats mirrors and magnifies existing automotive vulnerabilities. Consider the Common Exposure Library identified in current threat modeling: WiFi, cellular connections, Bluetooth, TPMS (tire pressure monitoring systems), OBD-II (on board diagnostic) ports, USB interfaces, EV charging infrastructure, and V2X communications. Each of these vectors currently relies on cryptographic protocols that quantum computers will eventually compromise. V2X communications, particularly, present an acute concern; these systems depend on low-latency cryptographic handshakes between vehicles and infrastructure to prevent collisions and coordinate traffic flow. The computational overhead of PQC algorithms, often requiring larger key sizes and more processing cycles, threatens to introduce latency that could degrade safety-critical response times.
OTA Updates and Signature Trust
Over-the-Air updates, already identified as high-risk vectors for malware injection, face compound quantum threats. The digital signatures that authenticate OTA packages historically have employed traditional ECDSA or RSA schemes which will be vulnerable to quantum attacks. A malicious actor with future quantum capabilities could forge signatures for malicious firmware updates, effectively weaponizing the vehicle’s own maintenance infrastructure. The Software-Defined Vehicle architecture, with its billion lines of code and continuous update cycles, requires cryptographic agility—the ability to rotate algorithms without hardware replacement. Yet current automotive ECUs were designed with static cryptographic implementations, often burned into hardware security modules with decade-long lifecycles.
The intersection of Functional Safety (ISO 26262) and cybersecurity (ISO 21434) will become particularly challenging in the PQC transition. Safety-critical systems such as steering control, braking, and ADAS depend on predictable, high-speed timing and deterministic behavior. Many PQC candidates, while mathematically robust, exhibit variable, and extended execution times or impose system level requirements that could violate existing safety elements. Lattice-based algorithms, for instance, because of their inherent extended computational needs, can require memory allocations that may trigger watchdog timers or interfere with real-time operating systems. Additionally, the extended computational time associated with these calculations may lead to exceeding the FTTI (Fault Tolerant Time Interval) of the vehicle, which is effectively the deadline that the system must beat once a fault is detected to prevent an accident. Furthermore, the threat agent risk assessment (TARA) processes mandated by ISO 21434 must now incorporate quantum-capable adversaries—nation-state actors with access to cryptanalytic quantum resources or organized criminal groups leasing quantum computing time through cloud services. In short, a lot of complexity now must be added to address critical threats.
The Hardware Reality Inside the Vehicle
Hardware constraints in general present formidable barriers to PQC deployment. Automotive microcontrollers, selected for cost efficiency and environmental resilience rather than computational headroom, often lack the memory and processing capabilities to execute post-quantum algorithms efficiently. A typical vehicle contains dozens of ECUs ranging from 32-bit microcontrollers with kilobytes of RAM to sophisticated infotainment processors and highly complex ADAS SoCs. Retrofitting PQC across this heterogeneous landscape requires either hardware replacement, which is prohibitively expensive (not viable) for vehicles already in service, or careful algorithm selection that balances security margins against resource constraints. Hybrid approaches, combining classical and post-quantum algorithms during transition periods, effectively double the cryptographic overhead.
Supply chain complexity amplifies these challenges. Automotive components source semiconductors from global foundries, incorporate software from hundreds of vendors, and integrate cryptographic modules from specialized providers. Coordinating a PQC transition requires synchronization across this ecosystem; OEMs must specify quantum-resistant requirements, chip vendors must implement hardware acceleration for lattice operations, and software suppliers must refactor cryptographic libraries. The “should strongly consider” language of ISO 21434, while providing flexibility, may prove insufficient to drive the coordinated industry response that PQC demands. Unlike the Jeep Cherokee vulnerability, which prompted immediate patches, the quantum threat offers no dramatic demonstration—only mathematical certainty of future compromise.
Data Privacy: The Archive Problem
The data privacy implications extend beyond vehicle control into the personal information ecosystem now embedded in modern automobiles. Biometric authentication data, payment credentials for EV charging, location histories, and occupant behavior patterns encrypted with current standards may persist in vehicle storage, cloud backups, and third-party databases for decades. Quantum-enabled decryption of this archive would expose not just current owners but entire household networks connected through vehicle telematics. A Nov. 2024 podcast that I participated in provided some real insights into the EV charging infrastructure security that are also very relevant and perhaps overlooked. Charging network operators must simultaneously protect real-time transaction integrity and ensure that historical charging patterns remain confidential against future quantum analysis.
Designing for Crypto-Agility Now
Addressing these challenges requires immediate architectural decisions with long-term consequences. Automotive cybersecurity teams must begin crypto-agility engineering; designing systems where cryptographic algorithms can be updated without hardware replacement, where certificate chains support algorithm diversity, and where secure boot processes can accommodate evolving signature schemes.
Algorithm diversity, in my opinion, is an admission to the fact that there is a real concern that the lattice-based algorithms may be cracked down the road, so alternative algorithms based on different math, Hamming and Hashing, are available. That said, an algorithm that was proposed by NIST for digital signage, which was deemed uncrackable after many years of review, was cracked within weeks of introduction using a relatively low-end microprocessor. In short, because CRQC are currently not available, there is no guarantee that PQC algorithms cannot be cracked leading to architectures that would require extreme amounts of agility and flexibility.
In summary, the transition to PQC cannot follow the automotive industry’s traditional model of generational updates; it must occur as a continuous capability evolution. As vehicles become software-defined platforms with connectivity lifespans exceeding their mechanical longevity, post-quantum readiness becomes not merely a security feature but a fundamental requirement for market viability.
.webp)
Allyson Klein Named 2026 Female Founder of the Year
TechArena Founder and Principal Allyson Klein was named Female Founder of the Year today at the 2026 Global Business Tech Awards in London.
Judged by an independent panel of leading technology experts, the awards honor companies and individuals whose work has added measurable, tangible value across customer experience, business management, data intelligence, and emerging innovation.
“I founded TechArena to find a voice for the bold innovation driven by creators across the tech landscape,” Allyson said. “Since its inception, our platform has fostered a community of leadership from the world’s tech titans to the next wave of visionary startups. Our collaborations with inventors and market makers from across the value chain have accelerated IT strategy for navigating the inception of the AI era. This recognition is about the fantastic team we’ve built at TechArena, the choice collectively to dedicate our career aspirations to the north star of collaborative innovation, and all of the brilliant people who have shared their stories.”
A Silicon Valley Kid Who Never Lost the Wonder
Allyson grew up in Silicon Valley during the birth of semiconductors, in a home where technology wasn't abstract; it was dinner table conversation. Her father was an international marketing executive; her mother worked as a nurse for chip plants, bringing home stories about the intricate chemical processes behind the magic of fabrication. By the time Allyson spotted a glowing green Apple computer screen at a friend's house, she was already primed to find it mesmerizing.
Allyson spent 22 years at Intel, where her work went far beyond marketing individual products. She helped build ecosystems, crafted foundational industry narratives, and created initiatives that brought companies together around shared tech visions. She built the foundations of industry engagement that ushered in data center virtualization, cloud computing, 5G networks, and artificial intelligence. Her marketing strategy helped grow a $20 billion dollar business for the company and unquestioned leadership in the industry.
In 2009, when her boss told her to "go figure out social media," one of Allyson's two resulting recommendations was to start a podcast. Chip Chat launched as a weekly show and ran for 754 episodes, reaching over 20 million listeners and winning numerous industry awards. The insight behind it was simple but powerful: the best conversations about technology were happening in tech cafeterias, not in board rooms. Engineers came alive when given permission to talk about what they’d invented, and how they felt when their visions came to life.
After Intel, Allyson led global marketing and communications at Micron, overseeing everything from CHIPS Act messaging to COVID-19 communications. But by 2022, something was missing.
“I missed creating content. I missed telling stories,” she said. “Those things gave me unique joy that leading massive marketing organizations never could.”
Building TechArena
TechArena was founded on the premise that the industry’s pace of innovation had fundamentally shifted, and conversations on the sidelines weren’t as valuable as direct access to inventors. This drove a conviction that the most important voices in technology aren’t always the loudest ones, and that insider knowledge creates a different kind of journalism. As Allyson puts it, “Most tech journalists don't have the background of living inside tech companies. At TechArena, we understand the shorthand.” That perspective has attracted an impressive range of guests and clients: the platform has featured companies representing more than $9 trillion in market cap, alongside 84 founders and CEOs of emerging tech startups who’ve shared their stories with TechArena’s audience of IT and cloud architects and infrastructure operations teams.
Every piece of TechArena content includes what the team calls the “TechArena take,” an opinion grounded in genuine insider experience. It’s a deliberate editorial choice that sets the platform apart.
What This Recognition Means
The Female Founder of the Year designation carries particular weight in an industry that still has significant ground to cover in terms of representation at the founding and leadership level. For the technology community TechArena serves, this award affirms that building something substantive, durable, and editorially credible is work worth recognizing. The community TechArena has built can strive farther and move faster in part because of the connections that they build together in the arena.
Allyson’s outlook on where technology is headed is characteristically optimistic. When cloud computing arrived, she recalls, the industry feared it would collapse the server market. Instead, new applications proliferated, new businesses were born, and human ingenuity found new expression. She sees AI the same way.
“Humans are going to have a renaissance in terms of what they can do based on AI innovation,” she said, “and while we re-calibrate on where intelligence is created between humans and machines, human to human interaction becomes even more essential and valued.” And she intends for TechArena to be there to tell those stories.
Congratulations, Allyson
The entire TechArena team extends our heartfelt congratulations on this well-deserved honor. It is a reflection of every interview conducted, every story pursued, and every voice given space to be heard. We look forward to continuing to build something worthy of this recognition.
To learn more about Allyson Klein and explore her work, visit techarena.ai/innovator/allyson-klein.