
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















Bloor Group CEO Eric Kavanagh's 2025 enterprise AI Predictions
In this episode, Eric Kavanagh anticipates AI's evolving role in enterprise for 2025. He explores practical applications, the challenges of generative AI, future advancements in co-pilots and agents, and more.

.webp)
Life’s Only Constant is Change: Impacts of the VMware Acquisition
Broadcom completed the $69 billion acquisition of VMware on November 22, 2023. In the one year since Broadcom’s acquisition of VMware, we’ve seen drastic pricing and packaging changes, a new channel strategy, as well as the restructuring of the internal and external community.
It makes you wonder, how have these changes affected IT strategy? And are there any examples of past acquisitions that can help us make sense of the changes? The Oracle acquisition of Sun Microsystems is a great place to look for lessons.
Sun’s acquisition by Oracle and its aftermath:
Sun Microsystems, founded in 1982, shares many similarities with VMware, particularly in their vibrant user communities. Sun's community, known as Big Admin, was highly informative, even though it was a bit intimidating to baby sysadmins like me. Sun's flagship event for Java developers was JavaOne.
Sun also played a pivotal role in laying the groundwork for today's cloud computing. At the forefront of UNIX adoption, Sun's SPARC hardware featured their successful early RISC processors. The Solaris software system, tailored for Sun hardware, was renowned for its stability and security. Sun introduced the world to the Java programming language, NFS, and the first building blocks of containers, unveiling the first container system, Solaris Zones, in 2004.
However, despite their early successes in the workstation market, Sun struggled to survive the burst of the dot-com bubble in 2000. As a sysadmin during that period, I saw our users (astrophysicists) favor x86 architecture and Linux for faster processing over SPARC architecture. Sun faced tough competition from vendors running open-source Linux on x86 systems.
In 2009, Oracle acquired Sun Microsystems for $7.4 billion, gaining access to their hardware, operating system, and the Java codebase. This acquisition also marked the loss of the Big Admin community.
Doesn’t that sound familiar?
Broadcom's Revenue Goals and Strategic Shifts:
Prior to the acquisition, Broadcom announced their goal for 70% of Annual Recurring Revenue to come from 600 key customers in highly regulated industries. To achieve this, Broadcom implemented several strategic pricing and packaging changes.
Initially, they shifted from offering perpetual licenses to software subscriptions. They forced adoption by removing support for existing licensing. Next, they streamlined VMware's 8,000 SKUs down to four core offerings:
- VMware Cloud Foundation
- VMware vSphere Foundation
- VMware Standard
- VMware Essentials
Broadcom also revamped VMware's partner go-to-market strategy, requiring existing VMware partners to receive invitations to become Broadcom partners. Additionally, VMware transitioned approximately 2,000 top accounts from the channel to direct management, aligning with Broadcom’s broader strategy.
By focusing on a smaller customer base, Broadcom can significantly reduce sales and marketing expenses. This has led to substantial workforce reductions at VMware, including an estimated 30% cut in recent weeks. The 2024 VMworld conference was notably smaller, prompting speculation about its future.
Broadcom's VMware Acquisition and Its Impact on IT Infrastructure:
The Broadcom acquisition marks a significant transition in IT infrastructure management. Previously, VMware was the go-to hypervisor for IT infrastructure, offering predictability despite not being the most affordable choice. Companies could predict their expenses, and VMware's expansive ecosystem of supported products—ranging from hardware and security to backups and encryption—was a foundational element for countless organizations. Many built their IT ecosystems on VMware vSphere, never expecting that relying on top-tier virtualization technology would lead to vendor lock-in.
However, Broadcom's changes to licensing have introduced unexpected and considerable price hikes, with IT organizations now bracing for at least a 100% increase in costs. As one analyst put it, these changes seem like an "effort to divorce the customer."
This places companies in a challenging position, as replacing VMware as a hypervisor is no simple task. Even larger enterprises are feeling the strain. For instance, AT&T sued Broadcom for altering support contracts, aware of the difficulties involved in migrating to an alternative hypervisor.
However, this scenario also opens opportunities for competition.
Emerging Opportunities for Competitors in the Hypervisor Market:
For decades, VMware has led the server virtualization market. In 2020, the total addressable market for server virtualization was valued at $7.1 billion, with projections to reach $10.8 billion by 2027, underscoring virtualization's critical role in the architecture of cloud computing.
However, Broadcom's assertive strategy and increasing costs have created opportunities for competitors. Microsoft and Nutanix offer rival hypervisors, and they are building extensive partner ecosystems. Scale Computing's hyperconverged infrastructure (HCI) system directly challenges VMware Cloud Foundation. Google Cloud has been actively pursuing VMware's customer base.
Conclusion:
The completion of Broadcom's acquisition of VMware has brought significant changes over the past year. The shift from perpetual licenses to software subscriptions, the reduction of VMware's SKUs to four core offerings, and the restructuring of the partner go-to-market strategy have all been pivotal moves.
These changes have led to substantial VMware workforce reductions and a notable increase in costs for IT organizations. However, they have also opened up opportunities for competitors in the hypervisor market, such as Microsoft, Nutanix, and Scale Computing.
Looking ahead, VMware's journey under Broadcom will likely be characterized by a concentrated effort to capitalize on its core offerings and deepen relationships with its top-tier customer base. While this strategy offers potential for streamlined operations and focused innovation, it also presents challenges in maintaining broad community support and flexibility for customers.
In fifteen years, people may forget how critical VMware was to IT infrastructure operations, much as people have forgotten the contributions of Sun Microsystems. vSphere and vCenter may be a distant memory to most people as the IT landscape continues to evolve. Perhaps that is the lesson in the Broadcom acquisition of VMware: the only constant in life is change.

Robots That Play Music By Ear & Other Highlights from SC24
The Supercomputing (SC24) conference in Atlanta brought together some of the brightest minds in high-performance computing (HPC) to discuss some of the biggest challenges facing our planet.
After spending four days among the roughly 17,000, highly enthusiastic technologists gathered here, three highlights stand out in my mind.
- Human-Robot Teaming: Georgia Tech’s Robot Band
Georgia Tech stole the show on opening night in the exhibit hall with a band performance that featured students playing instruments alongside a robot that plays the xylophone “by ear.” What struck me about the performance was not only the sheer joy it elicited, but the teaming of humans and robots – a topic that is one of many at the forefront of engineering research in academia today.
As the sound of Mr. Brightside (and several other hit songs) rung out from the Georgia Tech booth, crowds gathered with smartphones held high to get footage the delightful spectacle.
The robot, which is shaped like an arm, “listens” to music and plays along in real time.
“We have this robot that was put together by one of our school of music faculty – and it’s amazing because it can listen to what it’s hearing and then can play music that accompanies whatever it’s listening to,” said Professor David Sherrill of Georgia Tech. “It’s using AI techniques to do this.”
- Quantum Computing’s Potential to Solve the ‘Viscosity of the Universe’
During the opening night panel, experts took center stage to discuss the ability of HPC to revolutionize industries and shape the future, delving into four arenas where HPC has made transformative impacts: scientific discovery, engineering for societal benefit, arts and entertainment, and workforce development.
Panelists showcased how HPC underpins advancements in sustainable aviation, realistic visual effects in films, astrophysics simulations, and quantum computing – emphasizing its capacity to manage complex, multi-faceted problems.
Panelist Silvia Zorzetti of Fermilab – an expert in quantum computing – likened the field to an artist’s toolkit, where instead of paintbrushes, scientists wield qubits to explore the fabric of reality. Unlike classical computing, quantum computers excel at simulating quantum phenomena — problems governed by the principles of quantum mechanics. Hybrid quantum computation, which is a synergy between classical and quantum computing, represents the future of the field, Silvia said.
Quantum computing helps to better understand nature and is particularly well-suited to solving molecular energy calculations, particle interactions, and quantum field simulations, Silvia explained. And liquid can be considered a quantum field.
“Now, something very cool happened and it was discovered by the Nobel laureate, that the liquids, the viscosity of the liquids have a certain minimum,” Silvia said. “So, you cannot have any liquid that has lower viscosity than some value. This value depends on the Planck constant. So this means that the liquids, which we can also call ‘fields,’ are quantized, just like the energy. And so now, if we put together the relativity and the quantum mechanics, we have what we call the quantum field theory.
“Now, why do we care? Because now the universe can also be described as a liquid, basically.”
The evolution of the universe, described through quantum mechanics and relativity, is an area where quantum computing shines, Silvia noted. Simulating the viscosity of the universe’s "liquid-like" state post-Big Bang could unlock answers to fundamental questions about cosmic evolution.
Quantum computing also has implications for national security and secure communitations because it offers unparalleled security through quantum channels, ensuring that intercepted data becomes meaningless without proper quantum keys, Silvia said. Quantum-enhanced predictive models could improve everything from weather forecasting to financial risk analysis, merging quantum simulations with classical HPC.
- NASA: Uncovering the Secrets of the Universe
Dr. Nicola Fox, associate administrator for NASA's Science Mission Directorate, delivered a the SC24 keynote, highlighting the agency’s science mission, technological advancements, and inspiring exploration. With a focus on NASA’s commitment to explore the unknown and innovate for humanity, Dr. Fox emphasized three core themes: protecting life on Earth, searching for life elsewhere, and uncovering the universe's secrets.
She outlined the pivotal role of supercomputing in NASA's achievements, including processing vast datasets and advancing AI to accelerate scientific discovery. Dr. Fox cited missions like Voyager 1 and 2, which expanded our knowledge of the solar system and continue to explore interstellar space. She celebrated the integration of AI and machine learning, showcased by the PRISM geospatial model and other large-scale AI initiatives aimed at analyzing Earth's atmosphere, monitoring wildfires, and predicting weather patterns.
Highlighting the International Space Station’s (ISS) unique research platform, Dr. Fox described groundbreaking advancements in medicine, clean water technology, and agriculture, all driven by experiments in microgravity. These contributions extend beyond space, improving life on Earth and aiding future missions, including NASA’s Moon-to-Mars objectives under the Artemis program.
Dr. Fox also celebrated the James Webb Space Telescope’s (JWST) unprecedented capability to peer into the universe’s earliest moments. Dr. Fox shared awe-inspiring images, such as JWST’s first deep-field image and simulations of black holes, illustrating how supercomputing enables humanity to “visit” unreachable phenomena.
Dr. Fox explored NASA’s heliophysics and planetary science efforts, including Parker Solar Probe’s close encounters with the Sun and missions like Dragonfly, designed to explore Saturn's moon Titan. She also touched on Europa Clipper, which seeks signs of life on Jupiter’s moon Europa.
Closing with Carl Sagan’s “Pale Blue Dot,” Dr. Fox underscored NASA’s role in inspiring unity, curiosity, and hope. She invited the audience to collaborate with NASA, highlighting how their contributions drive groundbreaking discoveries and technological innovation that benefit all humanity.

PCI-SIG’s Al Yanes on PCIe 7.0, HPC, and the Future of Interconnects
In this podcast, PCI-SIG President Al Yanes explores PCI-SIG's journey to PCIe 7.0, advancements in copper and optical specs, and their pivotal role in HPC and AI.

VAST Data Showcases an AI Hall of Fame at SC24
What do you get when you combine football turf, Chick-fil-A, and a bunch of supercomputing operators? Today in Atlanta at the College Football Hall of Fame, that magical combination represented VAST Data’s latest update on its quest to become the operating system for AI with its VAST Data Platform. VAST Data knows the SC crowd well, having heritage in delivery of storage and data solutions for the HPC arena. Their advancement with the VAST Insight Engine and other solutions written about extensively on the TechArena represent a leap forward for VAST, delivering foundational tools to fuel AI training.
Today, VAST CEO Renen Hallak described this transition, highlighting that we’re on the cusp of our next inflection, moving from training to fine tuning and inference. VAST solutions, now integrated with RAG pipelines and vector databases, provide the tools for enterprises to take this bold leap forward with the confidence to keep data secure while delivering the performance offered by the world’s largest models.
This vision has been celebrated by the market with VAST deployments growing among the largest AI training providers and garnering a valuation of over $9 billion dollars based on momentum of its series E funding round. Today’s event was a terrific look into VAST’s traction in the market with leading AI players including XAI, CoreWeave, and Harvard Medical School.
The first up on deck was X-AI, Elon Musk’s AI arm, that just delivered a 100,000 GPU scale cluster called Colossus, in a mere 122 days. Why move so fast? X has notably been less engaged in AI training vs. other cloud behemoths, and Colossus places the firm in a position to accelerate their work quickly with the help of NVIDIA, Supermicro, and yes, VAST Data. The data platform was selected to drive foundational data management for this supercharged work with VAST engineers working closely with X-AI counterparts to get this Memphis based cluster up and running.
One customer that captured attention for their rapid buildout of AI services at scale was CoreWeave. CoreWeave’s Chief Product Officer, Chetan Kapoor, described his company’s mission to drive an accelerated compute platform, custom optimized for AI. Chetan stated “in our environment, you’re not going to find six hundred compute options, we’re specifically designed for AI.” The company has delivered with CoreWeave committing to H100 GPUs a year and a half ago and scaling to levels of performance focused on 100’s of megawatts of accelerated infrastructure and growing rapidly. This places CoreWeave on the path to potentially emerge as on par with the hyperscalers with continued market success.
CoreWeave has been built from the ground up with the VAST data platform. CoreWeave takes this combination of NVIDIA compute and VAST data management, and engages selective customers that are well prepared for AI adoption at scale. They’re targeting the 10,000 GPU scale for their customer base, a statement that highlights the relative demand for GPU cycles in market.
Today’s event wasn’t just about hyperscale. VAST also brought up Spencer Pruitt, CIO of Harvard Medical School, to highlight how scientific discovery is also being propelled by this AI driven innovation. Spencer shared how Harvard is driving genomics research to tackle challenges in disease management like cancer and personalized medicine with use of high-octane technology.
What’s the TechArena take? Data is the gold of this gilded age, and as long as companies are chasing insight from AI, the VAST data platform will continue to earn bold valuations in the marketplace. While much of this infrastructure buildout represents an AI arms race with repercussions beyond the scope of this article, the world will benefit from the accelerated innovation hyperscalers are driving as evidenced by what Harvard Medical School has driven with their data transformation. Color us continually impressed with VAST Data’s ability to execute within this high-pressure environment and waiting to see more innovation from this company in 2025.

Forecasting HPC, AI, and Next-Gen Weather Models with Peter Dueben
Peter Dueben of the European Centre for Medium-Range Weather Forecasts explores the role of HPC and AI in advancing weather modeling, tackling climate challenges, and scaling predictions to the kilometer level.

Unlocking Innovation with High-Performance, Cost-Effective AI Infrastructure
This session will explore the key infrastructure considerations for developing AI applications in industries such as the life sciences, healthcare and academia, and how edge-specific infrastructure, combined with PEAK:AIO's proven solutions, is critical to meet the demands of these sectors. Join us to discover how PEAK:AIO’s innovative infrastructure can support organizations to harness the power of AI, enabling them to execute transformative ideas and drive significant advancements.

Cornelis Networks CEO Lisa Spelman on Decisive Leadership
In this illuminating TechArena Fireside Chat, Cornelis Networks’ Lisa Spelman shares deep insights on leadership, team, embracing risk, and why she chose the ‘next great optimization frontier.’

Bill Gropp on the NCSA and the Future of Supercomputing Innovation
In this podcast, NCSA Director Bill Gropp explores the latest advanced computing trends, from AI innovations to groundbreaking research on supercomputing climate models, and how this tech is transforming science and society.

Revolutionizing AI Workloads with Advanced Data Center Solutions
Discover how AI is transforming data centers, with innovations in high-speed networking, emulation, and hyperscale infrastructure driving efficiency and performance in the era of AI workloads.

Gazing Into the Future of Insight & Discovery: 5 Top Trends at SC24
There isn't a conference as inspiring in the tech sector as Supercomputing (SC24), the annual gathering of the top technical computing centers on the planet, and the industry that supports them with the latest advancements in large scale tech.
While AI has taken center stage in every technology conversation, it's important to remember that the massively parallel computing delivered by HPC clusters are both the precursors of AI training clusters and the machines that have opened up calculations of some of the boldest scientific projects in history.
Here are just a few examples of things HPC clusters are studying today and poised to to advance tomorrow:
– Complex systems represented by climate and Earth's evolution
– Mapping of weather patterns
– Peering into the outer reaches of space
–The future of disease management
At TechArena, we are plotting a full lineup of interviews from the leading researchers in the field today, and will be publishing throughout the week on how these institutes are pushing scientific discovery forward with massive scale computing as their tool. We'll seek out insights from national labs across the globe as well as university centers engaged in collaborative studies to propel academic research forward. And, of course, we'll peer into the industry innovation that underpins advancement of supercomputing clusters. What are we looking for? Introducing our top five top trends we're tracking at SC24:
- The AI Infiltration of Supercomputing: It's easy to say that AI has invaded the world of supercomputing clusters. After all, much of the compute infrastructure sought by large AI model developers are also tapped by HPC. What we're seeking here is the integration of AI into supercomputing problem solving, and this is a question of mathematical models and precision. AI, long known as a low precision science, allows for massive acceleration of modeling vs. the tight precision of traditional HPC algorithms (i.e. the hard science). How do these come together? DeepMind's research into protein discovery gives us a map. Imagine the ability to tap AI to narrow down solutions from millions of options to a virtual handful. This allows scientists to narrow their focus for traditional HPC models, accelerating actual discovery by traditional high precision models to the point of making certain discoveries uniquely in reach. We'll be looking to see the applicability of AI integration across scientific spheres to see if further advancement in this space is on the table in the coming half decade, as well as seeing the most innovative integration being driven by scientific computing centers today.
- Network Innovation: We've written about it a lot on TechArena, but the next major advancement in compute cluster performance is removal of the chip-to-chip and node-to-node bottlenecks through further advancement of scale up networks, scale out networks and cabling. The moment of optical integration is upon us, and we're excited to see what the optical industry is delivering towards true integrated optics on platforms. We're also excited to see how the rest of the industry is faring in competing with NVIDIA's strong grip on networks with NVLink and InfiniBand solutions. Earlier this year, AMD released the first Ultra Ethernet adaptor, signaling the rapid delivery of this industry standard alternative for scale out connectivity, and we expect to see more in this space. Will we see highlights from other solutions at SC'24? Watch this space to learn more.
- Keeping it Cool: The liquid cooling industry is coming home to roost at the only conference that's always loved it. Supercomputers have embraced liquid cooling alternatives for years as they feature compute density requiring liquid technology. We expect to see a galvanized liquid cooling ecosystem on hand working to differentiate their solutions within their core market, bolstered by the acquisitions and broader investment that they are enjoying in the AI era. We'll be tracking the news from these players as they seek to further differentiate their offerings in a landscape that is getting more competitive and profitable.
- Efficient Data Management at Scale: We love threes, but we couldn't let this bonus trend sit on the cutting room floor. There's no bigger "big data" challenges than supercomputer calculations, and we expect to see advancements in data management from the major players delivered in part because of infusion of urgency from the AI arena. How will this AI momentum deliver new approaches to HPC data oversight? How will underlying advancements in storage media, most notably the introduction of 122 TB drives from Solidigm signaling the latest wave of storage density advancement, change the game for what's possible? We'll be reporting out this week on this storyline.
Following TechArena: Buckle up and set your eyes on the stars, as TechArena's platform is about to be inundated with inspirational stories of what our sector does best. If you enjoy this coverage, please give us a follow on your favorite social or content platform and subscribe to our newsletter below!

Cornelis Networks’ Lisa Spelman on Being CEO
Four months into her tenure as CEO of Cornelis Networks, Lisa Spelman sat down with TechArena to chat about leadership, how tech has changed, her vision for AI innovation, what’s on her playlist – and so much more.
A veteran of the data center and AI industry known for her deep technical expertise, Spelman brings over two decades of leadership experience from Intel to her new role.
We learned that she has perfectionist leanings, favors action, values collective expertise, is a diligent Pelotoner – and a Swiftie.
Dive into our Q&A with Lisa to learn more about her fascinating journey in tech and where she plans to take Cornelis Networks:
1) Q: Lisa, you recently took the helm of Cornellis Networks as CEO. What’s it like to take the reins of a company?
A: It’s an honor, truly. Having a board of directors and a group of founders choose you as the person to help lead the company to the next phase of growth is an honor. I am really enjoying getting to know and work with such a smart and capable team. I also really like the variety: everything comes at you. In a day, you can be in an architecture discussion, setting a sales commission plan, deciding on a new parental leave policy, recording a podcast, and meeting with a potential investor.
2) Q: You've led a lot of senior teams in your time. When you're considering building team cohesion, is there anything you've found to be your secret to success?
A: I’m a big believer in individual accountability, but with a thread of mutual reliance for success. I have often set up teams of mine to need each other in order to succeed. Some people like to pull it all apart and have more of an “every person for themselves” set up. I like to get people to lean in a bit and have to care about each other’s joint success. I’m not sure there’s one perfect recipe, and I will say that cohesion does not mean always getting along or agreeing on everything.
3) Q: For those who are newer to senior leadership, what mistakes did you make in this regard that you'd wish someone had told you about?
A: Oh, I won’t say no one told me, but did I listen? I remember when I took on my first really big team. I was in IT and took a role leading a large, technical, global team. We had people in 50 countries! I so clearly remember the pressure I put on myself that I had to be the one with every answer. I thought, ‘What use am I to them if I get asked a question and I don’t have the best answer?’ Classic perfectionist behavior. I learned pretty quickly, though, that so much progress and scale comes from harnessing all of the incredible knowledge you have in your team. Your power becomes the collective of all of those experiences.
4) Q: You've spent your entire career in tech. What do you see about the 2024 tech era compared to when you entered this arena?
A: Oh my gosh, when I entered the arena 100 years ago? 😊 I will say that the pace of progress and change is astounding. But some of the fundamentals are the same. Tech and scientific discovery are all about what is just out of reach: I can see the idea, but I haven’t quite yet figured out how to get there. It’s what I love about engineering, and I say this all the time – what was impossible on Friday is possible by Monday… and even more elegant by Wednesday (as long as you don’t have too many meetings).
I also see that big ideas and innovation are coming from everywhere. Technology itself has democratized how accessible it is to bring an idea to fruition. Look at my company building an end-to-end network for scale out AI and HPC. We taped out our switch and our adapter ASICs with less than 50 HW engineers, high quality, full emulation. That’s astounding when you think about it.
5) Q: What does this mean in terms of your approach to leadership and engagement in the industry?
A: My leadership philosophy goes back to scale. Everything is moving too fast; you have to create systems of trust and rely on collective expertise to set the pace. By the way, relying on collective expertise is not the same as requiring consensus, that is slooooow and leads to excessive politics in an organization. As far as the industry, I see it as my role to spend about 50% of my time outside of the company. Whether that’s with customers, investors, recruiting, suppliers, potential partners, peers. It’s my job to stay on the pulse of the industry and use that knowledge to expand the worldview of the team.
6) Q: You are also a bit of a unicorn as a female CEO of a tech infrastructure company. What do you think is imperative for female leaders in this industry, and how do you think the tech sector has evolved in terms of equal opportunity for women?
A: That’s the goal right? A unicorn leading a unicorn. 😊 I think it’s imperative for all leaders to do deep work understanding their strengths and areas where they need support. Then use that knowledge as you build out the best possible team to compliment your skillsets, fill in any gaps and to challenge you. I tell all my teams that if they are sitting around the table agreeing with me, then I don’t really need them. I enjoy hearty debate. But I have to create space for that and make it part of the culture.
I think for women specifically, the likability tax is real. Study after study shows that both men and women hold women to different standards on how likable they should be as part of effective leadership. And it is a tax, it’s draining. Every leader has to think about how they show up, but I think that women and minorities carry an extra burden there. It takes energy to be extremely self-controlled or to wear a mask.
7) Q: I need to work in AI here, but we aren't going to deep dive on tech. I really want to ask you about your view on the promise of AI and if you think our industry will deliver to the vision being touted?
A: I think we are just at the start of what’s possible. I know that AI can raise a lot of fears in people, and I know that it is being shoved in some places that just don’t make sense. Have you heard the one about using AI in drive throughs to recommend the right beverage? It’s hot out so recommend a diet coke instead of coffee. That’s not AI, it’s common sense! But despite that, despite the AI washing of everything, I really think we are heading into some amazing breakthroughs that will improve life for humans.
8) Q: What practices or habits do you rely on to keep your mind sharp and your energy up amid the demands of being a CEO?
A: Exercise, I love my Peloton. Walking and being outside.
9) Q: What advice would you give your 23-year-old self?
A: Ok this is really cliché, but don’t worry so much about what other people think. Some people are going to think you’re great, others are going to find you less so. It’s fine. Focus on what interests and excites your brain, not what someone else thinks you should do. Also, keep taking risks. My move overseas, my move to IT, my move to a startup, these have all been risks and each one has turned out better than I could have imagined
10) Q: What team(s) do you root for?
A: We went to the Blazer game on Sunday night, it was painful, not a good year. The Grizzlies have a fun player from Japan who’s only 5’8.” He’s an amazing ball handler and passer, the crowd was going crazy cheering for him and he was on the other team!
11) Q: What is the book that you most recommend?
A: I read a lot for work, but I like to read for fun too. I think it’s good to have a lot of choices so you always have something that’s right for your mood. Have a book, a few magazines, newspapers. I have really enjoyed reading a bunch of Frederick Bachman’s books.
12) Q: What’s at the top of your playlist?
A: I like everything, truly. But I must say I am a Swiftie!
13) Q: What superpower do you have that people don’t know about you?
A: I think I have a good ability to see everyone’s POV and the motivation behind it. It’s not so much acknowledging someone else’s point, which is just good listening and also valuable. But I think I do a pretty good job of getting to the why, and that helps me working with and leading people.
14) Q: Final question: At the end of your career, how do you want to leave your mark on those you lead and collaborate with?
A: We had a lot of fun while we did hard, cool stuff.

How Ocient is Revolutionizing Data Warehousing for AI
Ocient is disrupting the data warehousing space by offering a unified data platform that optimizes for always-on, compute-intensive data and AI workloads. This hyperscale enterprise data warehouse platform enables swift transformation and analysis of petabyte-scale data at speeds 10- to 50 times faster than competitor solutions - at a disruptively better price.
I recently had the pleasure of learning more about Ocient from Vice President of Marketing Jenna Boller Chorn during the Open Compute Project (OCP) Summit. Jenna joined Jeniece Wnorowski of Solidigm and me to discuss Ocient’s pioneering data warehousing technology and its impact on the industry.
Ocient’s platform consolidates various capabilities into a single system, eliminating the need for data movement between disparate platforms.
“By bringing more capabilities directly to their data in one platform, our customers typically realize a 50 to 90% savings in cost, system footprint, and energy consumption,” Jenna said.
Ocient’s unique architecture centers on a concept known as Compute Adjacent Storage Architecture (CASA), which tightly integrates compute and storage layers. Ocient’s technology leverages Solidigm’s NVMe SSDs instead of traditional hard drives, providing the speed and performance essential for real-time data management and analysis.
Jenna emphasized Ocient’s commitment to innovation at the software level for higher performance and lower operational costs.
“We’re really focused on maximizing that efficiency benefit, having a really tight data layer at the foundation,” Jenna said.
As companies prepare for increasingly data-driven and AI-intensive workloads, Ocient’s technology is built to help manage costs and performance at scale. Jenna noted that traditional data warehousing models have often focused on elasticity and convenience, allowing users to spin up new environments quickly. This approach can lead to unpredictable costs.
“We’re starting to see with customers that operate on a very always-on basis, the cost quickly gets out of control and actually becomes very unpredictable for them,” Jenna observed. “It’s not uncommon for me to talk to customers who are aggressively deleting data and introducing constraints on their environment to manage costs.”
Ocient’s technology allows companies to control these expenses by streamlining data processing, preparation, and exploration stages directly on the platform.
“As customers need to do more, particularly in the age of AI, they’re going to need to be more efficient at that core foundational layer,” Jenna noted.
Ocient’s approach reduces the need to transfer data between systems, which minimizes security risks and operational overhead.
The company also supports AI initiatives by incorporating in-database machine learning capabilities, allowing clients to train and deploy models directly within Ocient’s platform.
“We launched Ocient ML last year, bringing ML directly to the data in Ocient,” Jenna said. This functionality enables clients to explore, prepare, and process data with fewer resources and less time, making the pipeline for predictive AI and general AI more streamlined and cost-effective.
Customer satisfaction is a high priority for Ocient, especially as clients tackle high-compute tasks requiring seamless integration with existing systems. Jenna described the role of Ocient’s Customer Solutions and Workload Services Team, which helps clients manage data pipelines and identify ways to optimize processing and pre-processing tasks. This hands-on support ensures that Ocient’s clients can realize the platform's benefits from day one, which has led to a high retention rate among their users.
“By the time they go with Ocient, they've already seen everything working, and they're realizing value from day one,” Jenna highlighted. “That drives incredible stickiness with our customers.”
Ocient’s SSD-exclusive architecture means that clients can avoid energy-intensive hard disk drives while still achieving the performance levels they require.
“From our first day, we’ve always optimized for performance at scale and for efficiency,” Jenna said. By showing clients the comparative footprint of legacy systems versus Ocient’s solution, Ocient often reveals a 50 to 90 percent reduction in operational costs and energy consumption.
Jenna also expressed hope for more transparency around the energy consumption of software applications, particularly as AI applications increase in popularity.
So what’s the TechArena take? Hyperscale data environments are projected to account for over 50% of global data center capacity by 2026, so, in short, Ocient is in the catbird seat. Their technology is well-positioned to serve organizations requiring high-efficiency, large-scale data solutions.
With continued innovations, strategic partnerships, and a firm commitment to efficiency and sustainability, Ocient is leading a transformative shift in how organizations manage and leverage their data. And their commitment to sustainable practices help set it apart in a rapidly changing industry.
Interested in learning more? Listen to the full podcast and visit Ocient.com or connect with them on LinkedIn.

High Performance Portable Compute (HPpC) at the Edge with Antillion and Solidigm
The TechArena Tech Talk featured a discussion with experts from Antillion and Solidigm, who explored advancements in high-performance, portable computing solutions designed for edge environments. Alistair Bradbrook from Antillion shared insights on the critical need for compact, flexible, and resilient edge servers tailored to operate under harsh conditions. Solidigm’s Conor Doherty highlighted their innovative storage solutions optimized for these environments, emphasizing the importance of co-design to meet unique edge demands. Together, they discussed how modularity, density, and ruggedness enable scalable, efficient storage and compute solutions for applications at the edge.

Flex Demonstrates Leadership with Acquisition of JetCool
For those who have been following our continued coverage of the liquid cooling industry's rapid consolidation, it likely will come as no surprise that Flex announced its acquisition of JetCool today.
The companies had announced a strategic collaboration prior to OCP Summit, and with moves by Schneider and Jabil to acquire competitors in the space, that strategic collaboration was likely to get cozier. Today's announcement brings JetCool's direct liquid cooling propulsion technology, developed out of the MIT brain trust, into the Flex data center portfolio as a perfect complement to Flex's critical and embedded power offerings. Of equal importance, it brings top tech talent into the growing data center business best known for manufacturing services.
Some people may wonder why Flex targeted direct liquid cooling over an immersion cooling alternative as an acquisition target. During our recent TechArena podcast interview with Rob Campbell, Flex’s President of Communication, Enterprise and Cloud, he shared that JetCool's patented precision, direct-to-hotspots cooling jets enable direct liquid cooling systems to cool much higher compute densities than previously assumed. If true, this could be a game changer for many operators seeking to avoid the added complexity of immersion tank deployment.
Regardless, this is a win for Flex customers, as they can now source innovative liquid cooling with the same scale and supply chain flexibility that Flex offers for compute infrastructure and power solutions, critical with growing demand in AI data centers.
We'll be following this story with more engagement with the JetCool team at SC'24 next week.

Solidigm Introduces World’s Highest Capacity Drive: D5-P5336
We write a lot on TechArena about applications of technology to propel business, connect us in virtual communities, and propel humanity forward with scientific discovery and advancement.
The topic of the moment, of course, is artificial intelligence (AI) and how it’s vastly transforming how technology is serving as an increasingly valuable tool in productivity and insight. In all of these stories, there are a couple of foundational truths: everything reaped from the technology spectrum comes from processing and insight of data, and that data resides in infrastructure based on a silicon foundation.
This is why Solidigm’s gathering in Manhattan last night to introduce their latest QLC NAND feat – the delivery of the D5-P5336 – a first-of-its-kind 122 terabyte drive, is a foundational advancement for the broadest range of innovation. With its introduction, Solidigm maintains its QLC NAND leadership position that it first established with the quad bit per cell technology introduction in 2018. They recently passed 100EB of QLC NAND shipped, redefining what’s possible in data center-to-edge storage environments.
Before we delve deeper into the impact that it will have across markets, let’s unwrap the drive details. QLC NAND was developed for maximum storage density, storing 4 bits per NAND cell. This density also yields improved cost and energy efficiency but has some perceived tradeoffs in design, with lower write speed and endurance but notably higher read speeds.
Historic perception of QLC NAND has also questioned the durability of the drives. As the leader in QLC technology, Solidigm has been tackling these challenges focusing on delivering TLC performance with QLC technology. How have they done it? One thing that characterizes serious SSD innovation is whether a company is driving their own controller architecture, and Solidigm is serious about controller design as well as firmware engineering to drive up write performance. What has this resulted in within the D5-P5336 drive? Solidigm is claiming a 134.3 PBW rated endurance, which, in practical terms, promises 5 years of constant read and write without wearing out.
That’s an incredible achievement that opens the door for QLC NAND in a lot of new environments.
The new drive delivers 7,400 megabytes per second (MB/s) and comes in a variety of form factors including U.2 and E1.L, providing flexibility to systems designers for integrating into a variety of system configurations from edge to cloud. Notably, it sips power per TB, perfect for high-capacity data challenges where power savings is critical to free up needed watts for compute.
And then there’s, well, the ridiculous amount of capacity that this delivers. To put into perspective, you’d need about 500 drives to store IMDb’s 13 million movie catalog in HD. Four drives could store all of Spotify’s 100 million song titles. These examples put into context real use cases where large scale data pipelines are required. Let’s unpack a few offered from the Solidigm event:
PEAK AIO: Roger Cummings, CEO of PEAK AIO was on hand to share their vision for utilizing storage innovation to drive improved density in AI and HPC environments. PEAK AIO is driving solutions to the edge, carving a role for themselves with efficiency platform deployments. The market has responded well with a 4X growth of deployments within the last year. What markets are they targeting? Edge solutions can be found across verticals and applications as diverse as visual analytics, drones, MRI machines and more.
VAST Data: Renen Hallak, Founder and CEO of VAST Data, discussed how his team is driving a profound redefinition of data platform delivery for AI. Renen discussed a seven year history of collaboration with Solidigm to deliver innovation to customers and discussed how his data platforms, those covered broadly on TechArena, were to be found in the “biggest of the big” including QLC drives. The 122 TB drive, in Renen’s mind, presents the moment to move away from hard drives to a fully SSD era, accelerated by AI models.
CoreWeave: Jacob Yundt, Director of Compute Architecture at CoreWeave, was on hand to discuss how his team was building native cloud services for AI, and how his company is tapping QLC NAND to drive the scale of data that are required by his customers. The collaboration with Solidigm runs deep with Coreweave, as evidenced by the TechArena interview with Jacob from GTC earlier this year. Jacob claimed that “what we’re doing wouldn’t be possible without these high-capacity drives because our customers say ‘I need all of it’ and we’re constantly seeking more storage.”
Arm: Chloe Jian Ma, VP China GTM and IoT Line of Business at Arm, discussed how data center and cloud infrastructure require increased efficiency starting with Arm processors and extending to efficient storage deployment. Chloe discussed how hyperscalers such as Microsoft, Google and Amazon, are seeking these platforms to drive the energy savings to free up energy to fuel their AI training.
Ocient: Sophie Kane, Director of Growth Marketing at Ocient, discussed always-on compute intensive workload management bringing compute and storage closer together and delivering 50-90% improved compute and storage deployment efficiency. Sophie emphasized the close collaboration with Solidigm hardware and Ocient software to deliver infrastructure sustainability and more acutely energy efficiency. Ocient solutions are targeted to a variety of verticals driving analytics solutions deep into the enterprise.
So what should we make of the drive introduction? SSD demand has been on a tear with the rise of AI in the data center, and we do not see this adoption curve slowing down as enterprises seek to implement generative AI at scale in their edge-to-cloud environments in 2025. Getting the likes of VAST Data and CoreWeave to show up for an SSD introduction underscores the importance of this foundational silicon innovation to the big things these companies are doing in the AI arena. It also showcases Solidigm’s unique savvy operating in the data center arena and understanding “up the stack” requirements that transforms them from procurement engagement to strategic technology collaborator.
The work the Solidigm team has delivered within controller and firmware development highlights their tech prowess that puts them atop drive considerations for these markets. I expect the 122 TB capacity to get a lot of attention from the world’s largest data centers given the efficiency it provides to storage arrays and the immediate action needed for freeing up power within data centers to fuel power-hungry GPUs.
The level of resiliency built into the drives also should be welcome news for IT managers seeking to modernize their storage environments, but potentially sitting on the fence for concerns about QLC reliability and longevity. We’ve got some serious FOMO about not having our deployment plans in place at TechArena and are wondering…what would you do with 122?
Watch this space for more.

MLCommons’ David Kanter on Benchmarking AI, Accelerating Innovation
David Kanter discusses MLCommons' role in setting benchmarks for AI performance, fostering industry-wide collaboration, and driving advancements in machine learning capabilities.

The Rise of High-End Audio in Modern Vehicles
The audiophile trend is finding its way to the automobile – and OEMs are seeing dollar signs.
In this post, I’ll discuss the state of car audio today and break down options for audio amplifiers. But first, let’s take a moment to reflect on car audio through the decades.
As you can see, there were some 1950s-era cars that were equipped with phonographs. For obvious reasons, having a record player in the car was not a good idea. And while it was claimed to be impervious to skipping, it did indeed skip. The phonograph was based on a unique 7” format, which was never embraced by the music industry, leading to a catalog of 8 records and total sales of less than 5,000 units. This did, however, illustrate the point that there was a move underway to replicate the home entertainment experience in the car.
Ford became one of the first to offer 8-track players as a factory option in cars and trucks in 1965. Popular throughout the 1960s and 70s, they were replaced with cassette players in the early 1980s. CD players came onto the scene in the 1980s, but didn’t garner widespread popularity until the 1990s. And during the time in between, it was quite popular to have a vehicle equipped with a dual cassette player and CD changer.

CD players remained a common feature in cars through the 2000s, though they started to decline in popularity in the 2010s with the rise of digital media and Bluetooth audio. By the mid-2010s, many car manufacturers began phasing out CD players as streaming and auxiliary connections became the standard for in-car audio.
Fast forward to today, and bringing the high-end audio experience into the car is officially a thing. Today’s consumers are expecting the same, seamless digital experience in their cars as they have in their homes. Original Equipment Manufacturers (OEMs) are embracing this trend as it leads to greater revenue-per-vehicle while unlocking an opportunity for after-market revenues. (See my previous blog, How Software-Defined Vehicles are Reshaping the Auto Industry)
Historically, OEMs would install a fairly low-end AM/FM radio and then the various other players we’ve discussed based on when those formats came in and out of use. For audio enthusiasts who wanted something better in their cars, there was a large after market that opened for high-end car audio equipment and speakers – money that rightly could have been for the auto OEM. (Well, that’s not going to happen anymore.)
So you want high-end audio? Let’s talk about how to enable it.
Which Amplifiers are Best for Vehicle Audio?
Class A audio amplifiers are generally considered to be the best sounding amplifier of all the different classes of audio amplifiers. Unlike the more common class B amplifier, which uses a complementary output pair that is based upon push-pull operation between two output devices (transistors), the class A amplifier does not use a complementary output pair or push-pull operation. The class A amp processes the full swing of the audio across the output devices.
Because the class B amplifier effectively splits the audio signal in half, switching between the push-pull output stage – there is a period when one transistor is turning on and the other is turning off, where there is a “dead zone,” which is referred to as “cross over distortion.” This type of distortion leads to listener fatigue. While class A doesn’t suffer from crossover distortion, the overall power efficiency of a class A amplifier is very poor – at the level of 10%. This implies a modest 100-watt class A amplifier would require 1000 watts of power from the wall. The cost of the electronics, power transformers, and thermal management (cooling 1000W requires lots of heat sinks) makes this class prohibitive to the masses. Class B amps are inherently more power efficient, leading to significantly lower costs.
However, class A amps are common in audiophile circles because for the audiophile, price is not an issue. A high-end home audiophile-quality system can easily exceed $100,000. While there are some amazing systems that deliver some amazing, unmatched performance, this is an area that is riddled with snake oil, in which it’s difficult, if not impossible, to prove the difference in performance of some of these esoteric gimmicks with price tags that are not for the faint of heart.
A pair of “high-end” speaker cables three meters in length costs upwards of $7,000. For equivalent length cables sufficiently capable of driving high-end speakers, the cost is roughly $40. But apparently, you’re missing out on how “the synergistic blend of metallurgy and conductor strikes a keen balance between detail, transparency and a natural tonal presentation.” I’m not sure what that means, but I know industry “golden ears” have refused to perform blind A/B testing of different cables to avoid the risk of identifying “low-end” cables as the superior choice.
So what class amplification is finding its way in the vehicle – class A or class B? Actually, it’s neither – it’s class D. I’ll spare the detailed underlying technical description, but class D allows for significantly greater power and cost efficiency than even class B. Without the burden of heat and power, even smaller form factors can be realized. In its infancy, class D was not vogue due to the unpleasant artifacts that arise from the underlying high-speed switching architecture. Throughout the years, engineers have been able to address those artifacts leading to audio performance specs that are at least on par with class B.
That said, you will still have the rogue audiophile complain that these amplifiers don't deliver the keen balance between detail, transparency and a natural tonal presentation. (If you know what that means, shoot me a comment on LinkedIn.)
Now that we understand the available amplifier options a little better, let’s look at some of the carmakers that have already implemented high-end audio offerings.
Automakers Seizing the Audiophile Trend
Examples of carmakers who have jumped on the audiophile movement include Jeep, Hyundai and Kia. Two years ago, Jeep rolled out a vehicle with the highly coveted high-end audio equipment brand McIntosh inside. Jeep touts it as the McIntosh living room experience in the car and has received mostly positive reviews. Jeep promotes “a sweet spot” in every seat.
Other audiophile brands including Marc Levinson, Focal, and B&W are also finding their way into higher-end vehicles. However, controversy exists as to whether these high-end brands are mostly licensing their brand name to the OEM or Tier 1, where the underlying technology is based on commodity hardware with little to no actual involvement from the stated brand. Again, it appears as though we’re even seeing snake oil sales happening in audio in the car.
Beyond providing an audiophile experience in the car, OEMs are rolling out vehicle interiors that offer immersive experience that can be personalized for every occupant in the vehicle. Hyundai Kia is introducing this capability – referred to as Separated Sound Zone (SSZ). This technology allows each passenger to have their own unique audio stream without interference from other vehicle occupants. This includes sources such as phone calls, bluetooth connection, music, etc.
SSZ is based upon technologies that are similar in nature to those used in noise-canceling headphones or “beam forming” to focus the sound. Beam forming is used in WiFi and cellular networks and directs the RF signal to the network/cellular user for optimal signal strength on a user-by-user basis.
In conclusion, it would seem the sky is the limit for in-car audio. Which begs the question: with vinyl coming back in vogue, should we revisit the in-car phonograph?

JetCool Tackles AI’s Power Demands with Precision Cooling
I recently had the pleasure of sitting down with JetCool Founder & CEO Bernie Malouin to discuss the company’s liquid cooling tech, which uses arrays of microfluid jets to directly target chip hotspots. This precise technique allows JetCool to chill processors reaching up to 3,000 watts – a figure that’s mind-boggling when you consider traditional cooling systems.
JetCool collaborates closely with major chipmakers like Intel and NVIDIA to understand exactly where each chip’s hottest points are, designing their jets to tackle those areas directly. The result is highly effective, efficient cooling that keeps even the most power-intensive chips running smoothly.
As part of TechArena’s Data Insights series with Solidigm, my co-host Jeniece Wnorowski and I caught up with Bernie during OCP Summit 2024.
JetCool spun off from a research project at Massachusetts Institute of Technology (MIT), which explored cooling technologies capable of managing extreme heat loads for aerospace applications. As chip power demands surged with the advancement of data centers and AI, JetCool launched – shifting its focus to data centers and advanced computing and taking its place as an industry innovator with a unique and compelling liquid cooling solution.
With customers including Intel, AMD, and NVIDIA, JetCool has emerged as one of a small group of players at the forefront of a crowded field of cooling solutions.
Providing a Gradual Approach to Liquid Cooling Adoption
Many companies may not be ready to adopt full facility-level cooling, so JetCool provides tailored solutions for both “brownfield” (existing) and “greenfield” (new) data centers. Bernie described how the company’s self-contained single-phase cooling systems are a great entry point for data centers looking to implement liquid cooling gradually.
As processors get more powerful, so do their cooling needs. Bernie projects that 100-150 kilowatts per rack will become standard in many deployments, with performance clusters reaching up to 300 kilowatts per rack.
As installations scale up, they can transition to larger solutions, like JetCool’s new CDU (Cooling Distribution Unit) line, which supports up to 300-kilowatt racks.
JetCool and Flex: A Strategic Partnership
Bernie also highlighted a recent announcement regarding JetCool’s strategic partnership with Flex – a move he sees as crucial for the company to rapidly scale. Flex brings 50 years of advanced manufacturing experience to help reach markets faster, delivering customized cooling products for hyperscalers and enterprises alike. Flex’s global reach enables JetCool to support clients worldwide.
Reusing Heat & Committed to Sustainability
A fascinating part of our conversation centered on heat reuse. JetCool has engineered its systems to operate at higher coolant temperatures, making it feasible to repurpose waste heat for applications like district heating, greenhouses, and even municipal projects. This capability is particularly popular in Europe and gaining traction in North America. JetCool’s approach allows coolants to reach 50-65°C, far higher than typical systems, enabling more efficient heat recovery for sustainable operations.
JetCool demonstrates its commitment to responsible innovation by selecting efficient materials, designing cooling systems that lessen energy consumption, and aligning its tech to the broader goal of reducing environmental impact. Bernie highlighted that the company’s systems operate on minimal power, helping data centers reduce their carbon footprints without sacrificing performance.
So what’s the TechArena take? JetCool’s combination of unique precision cooling, scalability, and sustainability differentiates them. I love the way they provide different stages of solutions that reduce barriers to entry for customers. And I admire that JetCool is paving a path that balances performance with responsibility, taking meaningful strides to help shape the future of sustainable high-performance computing as the industry faces growing pressures to reduce environmental impact.
Interested in the future of cooling and sustainable data center management? Check out the full podcast with Bernie and learn more about what JetCool is doing.
.webp)
Great Debate featuring voices from Intel, Metrum AI, and NeuReality
In this Great Debate, moderator Allyson Klein tees up the topic, "Enterprise Adoption of AI: Hype or Hope" with industry experts Iddo Kadim, Field CTO at NeuReality, Lynn Comp, VP at Intel, and Steen Graham, CEO of Metrum AI. They delve into enterprise adoption of AI and explore the advancements in multimodal AI as well as the potential shift toward robotics and physical AI.
The panel discusses the need for trust, security, and practical integration to avoid pitfalls like hallucinations or catastrophic security issues. They also detail some of the challenges enterprises face, including data management, cost, infrastructure, and sustainable differentiation. They conclude that AI’s adoption must be strategic, considering enterprise-specific needs and ethical safeguards for true value.

Revealing the Algorithm Genie: The Astounding Promise of AI
AUSTIN – November 8, 2024 – Machine learning (ML) and artificial intelligence (AI) technologists from around the globe packed a standing-room only ballroom this morning, transfixed by Jepson Taylor’s keynote address kicking off Day 2 of in-person sessions at the ML Ops World – Gen AI Summit 2024.
Taylor, Former Chief AI Strategist at DataRobot & Dataiku and founder of VEOX Inc. – took center stage and shared anecdotes about deeply personal parts of his life journey while weaving a mind-bending narrative about the power and potential of AI.
Delivering a talk entitled, “Unleashing the Algorithm Genie: AI as the Ultimate Inventor” – Taylor engaged the audience with a visual demonstration of how AI can exponentially augment each practitioner’s ability to imagine and invent – and specifically, to generate advanced, high-quality algorithms. Intertwined with the AI and the math, Taylor shared his intricately true-to-life AI portraits and delved into powerful anecdotes from his journey – including referencing a period of time when he chose to be homeless in the snowy hills of Utah as a college student – continuously challenging himself to incrementally more difficult living conditions.
Taylor is a popular speaker in the AI space, having been invited to give AI talks to companies like Space X, Red Bull, Goldman Sachs, Amazon, and various branches of the U.S. government. His applied career has covered semiconductor, quant finance, HR analytics, deep-learning startup, and AI platform companies. He co-founded and sold his deep-learning company Zeff.ai to DataRobot in 2020 and later joined Dataiku as Chief AI Strategist. He is currently launching a new AI company focused on the next generation of AI called VEOX Inc.
His keynote landed powerfully and was filled with personal insights, humor, and deep reflections on the pace and nature of change in AI and innovation.
He opened by describing his passion for invention and innovation, noting the rapid acceleration of advancements in AI. He describes his "chaotic" presentation style, emphasizing his intention to blend storytelling, science, and personal anecdotes to make key concepts memorable. He divided his talk into four main themes: decisions, intelligence, innovation, and adaptation.
Decisions: Do I have the muscle memory to execute?
Taylor began with a discussion of decision-making, exploring how the human brain handles choices and adapts to challenges. Reflecting on his experiences snowboarding down a steep mountain, he used the anecdote as a metaphor for navigating high-stakes decisions and “facing down fear.” He illustrated this through the brain’s interaction between the amygdala, which "thinks we’re going to die," and the neocortex, which, while aware of mortality, doesn't believe death is imminent. He highlighted the role of muscle memory in decision-making, explaining that complex skills, whether driving or surgery, cannot be learned by simply watching — they require practice and experience.
He emphasized that life and career paths are often “a random walk,” with decisions sometimes driven by unpredictable opportunities rather than clear-cut plans. He shared a humorous anecdote about his early programming journey, including how he failed as a PhD student because his motivation at the time was video games – and how he lived in a tent in the snow during college, garnering the nickname, “Homeless Ben.” His aim at the time was simple: to not pay rent. But he used the experience as a way to continually improve, daring himself to increasingly difficult living conditions.
Intelligence: The acquisition of knowledge to be used for future decisions
In his discussion on intelligence, Taylor offered a unique perspective on what it means to be “smart” and how intelligence develops over time. He defined intelligence as "the acquisition of knowledge to be used for future decisions," pointing out that intelligence isn’t merely about innate ability, but the compounding effect of shared human experiences. He contrasted the intelligence of different species, noting that while a butterfly may react to immediate threats, humans are uniquely capable of transferring knowledge across generations — allowing us to build on each other’s learning, as seen in complex achievements like space exploration. Taylor illustrated this with a striking thought experiment: “Are you smarter today than you were yesterday?” Time, he argued, does not guarantee growth in intelligence. Instead, he emphasized that advancing intelligence requires stepping out of one’s comfort zone, actively seeking new ideas, and “colliding” with other people to spark innovation. This collision of ideas and perspectives, he concluded, is essential for fostering the creativity needed to tackle future challenges and adapt to a rapidly changing world.
Innovation: Mining for Gold
Moving on to innovation, Taylor compared it to "mining for gold," with discoveries often emerging through a combination of luck and persistence. He reflected on his graduate research, where a computer algorithm delivered a breakthrough by finding a mathematical insight he hadn’t anticipated.
“Am I smart, or am I lucky?” he pondered, attributing the success to the machine’s relentless testing capacity. He pointed out the inherent limitations of human ideation, noting:
“Humans can't come up with a thousand ideas on the spot—at most, we have three or five. But AI can try millions of ideas and vet them instantly.”
Taylor shared examples of how generative AI has transformed creativity, even in fields traditionally seen as human domains like visual arts. He contrasted the high cost and time associated with human-produced visuals seven years ago with the near-instant, cost-effective results achievable with today’s generative AI.
"Everyone’s an artist; they just don’t know it yet,” he said, urging attendees to experiment with creative AI tools like Midjourney.
One of the most compelling parts of Taylor’s talk was his description of an imagined AI-generated competition for the best headshot. He explained how adaptation plays a vital role in such contests, with AI developing hyper-realistic images, down to details like micro hairs on a nose or reflections in an eye. AI’s capacity for “emergence,” a spontaneous formation of complex, life-like patterns, represents a revolutionary step in creative fields.
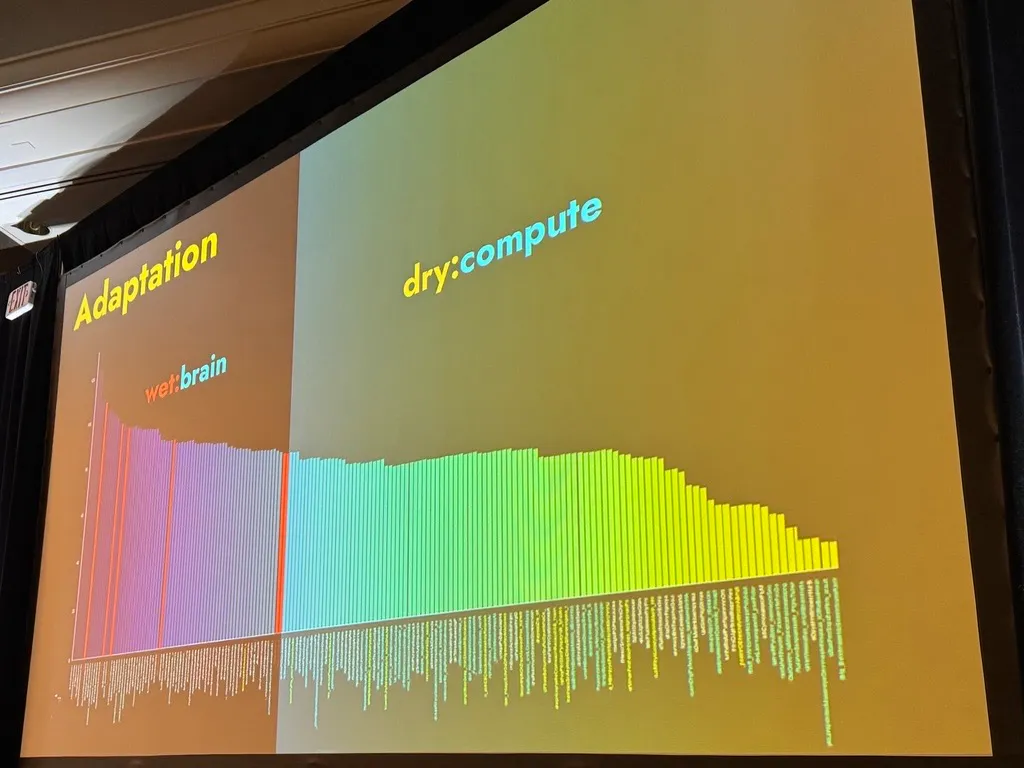
Adaptation: Mining for Gold with a Tool that “Boils the Ocean of Possibilities” For You
Taylor concluded by emphasizing adaptation as the ultimate key to success. He highlighted the need for AI systems to be adaptable to different contexts and requirements. For example, he described his development of an AI “hacker” that autonomously tests and breaks his company’s security protocols, then learns to avoid making the same mistakes in future runs. This self-learning mechanism, or “adaptive system,” has broad implications for fields like cybersecurity.
Taylor also addressed the transformative effect of AI in software development, asserting that there may soon be no “sacred” part of the engineering workflow immune to automation. He explained that within his company’s internal development, agents can handle entire projects, performing refinement, modularization, and even making their own agents to improve project efficiency. This represents a profound shift in how engineering is done.
“You don’t need an engineer to define the structure anymore; AI can boil the ocean of possibilities for you,” he said.
He discussed the role of inspiration in driving innovation. Humans can create algorithms inspired by natural phenomena, such as pheromone trails left by ants. However, AI now holds the potential to push beyond this human capability by generating truly novel concepts that defy typical human thought processes.
In his closing remarks, Taylor encouraged attendees to embrace AI tools and experiment with their capabilities.
“If you’re not spending at least an hour a day with tools like OpenAI and Anthropic,” he urged, “you’re missing out on a complete game changer.”
His excitement for the future of AI was palpable as he outlined a vision of a world where human creativity and intelligence are augmented by machines. He offered a glimpse of a future where knowledge is more accessible, learning more engaging, and innovation knowing no bounds.

ML and AI Technologists Convene, Connect at ML Ops World
AUSTIN, Nov. 7, 2024 – Leading machine learning (ML) and generative artificial intelligence (AI) technologists from around the globe gathered in Austin today to kick off Day 1 of the in-person global ML Ops World/Gen AI Summit.
Amidst an environment of rapid industry acceleration, ML and AI practitioners are seeking connections, collaborations, best practices, recommendations and tools.
AI Makerspace Co-Founder Greg Loughnane opened the conference with encouragement for technologists to take advantage of the ML Ops community and learn from one another in addition to attending deep-dive sessions on topics ranging from tutorials on building LLM applications to architecting multi-agent systems for code generation.
“It’s always good to learn from others’ experiences,” said Prabhdeep Singh, a ML engineering manager at United Airlines who is working to build and tune a machine learning platform and hopes to learn best practices from the ML Ops community.
“There is ambiguity in the industry – and there are tons of tools,” said Robin Amin, an ML ops engineer at Veterans United, as he gestured toward the conference exhibition hall, where dozens of vendors tout their products and services. “I’m here to see what types of automations other organizations are adopting so that I can select some tools and then develop others.”
Also working to build or coalesce their employers’ ML platforms are an IT leader from Fannie Mae and an ML Ops engineer from Turo.
“Building from the ground up is not a popular or efficient approach,” said Angelica Pando, an engineering manager at Turo who is looking for plug-ins and best practices to help expedite her project.
Cyber Advisor and Evangelist Helen Oakley, CISSP, GPCS, GSTRT, who is founding partner of AI Integrity & Safe Use Foundation, said she is attending the conference to make new connections. The foundation’s work centers around helping organizations build and acquire resilient AI systems.
Denys Linkov, head of ML at Voiceflow, took the main stage to reflect on key advancements made in the ML and AI space in 2024. He discussed multimodal LLMs that combine vision, audio, and other data types, such as Gemini Pro and GPT-4.0, which significantly expand context length and functionality. These advancements, including open-source tools like PaliGem and CoPali, are setting new standards for AI's ability to interact with multiple data forms. Linkov also pointed to human-computer interaction breakthroughs, noting Meta's integration of LLMs within its ecosystem, reaching billions of users worldwide. This trend is furthered by OpenAI's acquisition of Multi, which supports multi-agent systems, and GPT Canvas, enhancing desktop interactivity. In video generation, Linkov noted releases like Runway Gen3 Alpha and Meta’s MovieGen, which have introduced exciting new capabilities, with both closed and open-source options now available to developers.
Also in 2024, we have seen the rise of MegaGPU clusters, he said. These vast supercomputing networks, such as Elon Musk’s Colossus, are built to support complex AI models but face challenges with power demands and reliability.
Linkov underscored the importance of evaluations in AI model performance, with major vendors like Anthropic, Cohere, Google, and OpenAI launching platforms for evaluating and optimizing AI models. This focus on evaluation tools reflects the industry’s need for precise measurement in GenAI. He also discussed how automation remains central to AI's future, with companies like Google and Amazon leveraging AI-driven automation in tasks such as Java migration and customer support, despite return on investment (ROI) not being the primary focus initially. And he emphasized the emergence of synthetic data as a pivotal resource, as demonstrated in the Llama 3 paper.
Stay tuned for more to come tomorrow from the ML Ops World – Gen AI Summit in Austin!

CoolIT: Leading the Pack on Liquid Cooling
As hyperscalers, supercomputing operators, and advanced enterprises globally rush to modernize and expand operations, CoolIT has emerged as a key partner for data center cooling – providing efficient, reliable solutions that have been proven in the market for 20 years.
Liquid cooling – once the target of skepticism across a data center industry that balked at its complexity and didn’t need it yet – has exploded on the data center scene as one of the key enablers of heavy AI workloads. During the OCP Summit 2024, new liquid cooling entrants could be seen in every direction. And what’s more, established players in other parts of data center infrastructure have begun planting liquid cooling flags.
It’s more than apparent that the opportunity is gargantuan. But there are few liquid cooling players that come to this data center modernization party with 20 years of expertise. CoolIT is one of them.
I thoroughly enjoyed the opportunity to sit down during OCP Summit with Charles Robison, Director of Marketing for CoolIT Systems, to learn more about this critical player in the AI - data center landscape.
From Chips to Data Centers
CoolIT’s liquid cooling tech has its roots in making cooling chips for high-performance gaming platforms. This foundational knowledge of chip-level cooling enabled the company to quickly pivot when data center demand began to skyrocket.
Today, CoolIT’s offerings include cold plates and advanced cooling loops designed to support Original Equipment Manufacturers (OEMs) and Original Design Manufacturers (ODMs).
But as Charles highlighted, its core offering is cold plate technology, which targets hotspots on chips, delivering focused cooling where it’s needed most, ensuring systems operate optimally even under high workloads.
Why the Focus on Direct Liquid Cooling
In the liquid cooling industry, various methods are available, including immersion cooling and rear-door heat exchangers. CoolIT focuses on single-phase direct liquid cooling (DLC) because it is proven, reliable, and scalable. With liquid cooling technologies tested across generations of servers from brands like HPE and Dell, CoolIT’s cold plates stand out for their reliability. Single-phase DLC is particularly effective for handling high thermal design power (TDP) in modern chips, including hot spots that require targeted cooling. By focusing on DLC, CoolIT addresses both the demand for scalable solutions and the ability to cool today’s high-powered chips.
While CoolIT recognizes the value of other cooling approaches, such as immersion cooling, DLC remains the most feasible option for wide-scale deployment. As Robinson explained, “Our technology has been through multiple generations… it’s a proven technology and a scalable technology.” This commitment to proven solutions ensures data center operators have reliable and consistent performance, a necessity in an industry where operational continuity is crucial.
CoolIT’s reputation as an end-to-end provider has been bolstered by their ability to cover every aspect of data center cooling. They supply a full suite of products, from cold plate loops that deliver direct cooling to chips, to Coolant Distribution Units (CDUs) that manage the overall cooling flow. This comprehensive approach ensures that customers receive a streamlined solution, custom-tailored to their needs – making CoolIT’s systems a reliable choice in a high-stakes environment where consistency is paramount.
Charles aptly pointed out that when Jensen Huang of NVIDIA announced liquid cooling as the future of data centers, it marked a turning point for the liquid cooling segment. Once confined to high-performance computing (HPC) and academia, it is now erupting onto the data center infrastructure scene as a solution that significantly enhances energy efficiency.
“Liquid cooling has crossed the chasm; it’s now a mainstream approach,” Charles said.
With their single-phase direct liquid cooling, data centers can handle AI-driven workloads that push conventional cooling to its limits.
Quality. Service. Support.
“Quality, as they say, is job one,” Charles said, explaining CoolIT’s top priorities.
Reliability is at the center of CoolIT’s approach. The cooling systems they produce are meticulously designed, using technologies like friction stir welding to create a single, molecular-level fusion of cold plates. This construction minimizes the potential for leaks, ensuring longevity and reliability. CoolIT employs rigorous quality control, from inspecting incoming parts to conducting end-of-line testing. Every system is tested before it leaves the factory, guaranteeing that clients, including major server manufacturers like Dell and HPE, receive a flawless product.
Beyond the product itself, CoolIT offers a comprehensive service network covering more than 70 countries, ensuring seamless deployment and ongoing support. CoolIT assists customers at every stage, from design consultation to installation and commissioning, making it easy for operators to integrate liquid cooling into their existing data centers.
“So you want to figure out how to design?” Charles said. “We'll help you with that. Would you like to install it? Yep. We've got an installation team that will come in. And we'll put together a secondary fluid network if you need…We'll help you figure that out. We'll commission it. So we'll put the fluid in and we'll actually get it running.”
Scaling for Growth
Looking into 2025 and beyond, the demand for liquid cooling will only increase as data centers handle denser and more complex workloads. CoolIT has invested significantly in expanding their production capabilities, scaling up by 25 times to meet the growing demand. This capacity enables CoolIT to handle both brownfield deployments – where liquid-to-air CDUs can be introduced to existing data centers – and greenfield projects that require a more comprehensive cooling solution from the ground up.
The scale of CoolIT’s investment in production reflects the growth potential they see in the market. As Robinson noted, “We certainly see just a massive deployment of liquid cooling… we have multi-gigawatt manufacturing capacity within our shop.” This preparation positions CoolIT as a capable partner for any data center operator looking to future-proof their infrastructure against the demands of tomorrow’s computing workloads.
Educating the Industry and Pioneering Change
To ease the industry’s shift toward liquid cooling, CoolIT emphasizes education and industry collaboration. As a founding member of the Liquid Cooling Coalition, CoolIT is committed to informing operators, policymakers, and the broader industry about the benefits and applications of liquid cooling. Through these initiatives, CoolIT hopes to normalize the adoption of liquid cooling, fostering an industry-wide shift toward more efficient, sustainable practices.
So what’s the TechArena take? I’m so grateful to Solidigm and our Data Insights series for opening the door to this delightful discussion. As for CoolIT, in short, they are rocking liquid cooling. Their solutions have proven themselves in one of the most demanding environments — data centers powering AI. And while this space is nascent and has more promise than volume deployments, as we head into the second half of the decade, we at TechArena are expecting a hockey stick ramp for this segment of the industry. We also are keen to see how CoolIT leverages this massive opportunity towards financial returns. Listen to the full podcast here.

The Road to Sustainable IT Starts at the App & Microprocessor
We have seen the popularity of Sustainable IT in the enterprise rising. Is it truly a new CIO initiative or simply a revival of the early 2000’s ‘Green IT’ hit?
Sustainable IT is the practice of designing, using, and disposing of information technology in ways that minimize its environmental impact. Its goal is to reduce the carbon footprint and energy consumption of end-to-end IT operations, which includes everything from manufacturing and using computers and servers to managing data centers and disposing of electronic waste.
The scary thing is that I was deeply involved in the first go-around even going as far as to present at the 2009 COP15 in Copenhagen a global energy reductions model for IT. So, what’s different now? Will Sustainable IT make a real impact on any corporate ESG goals?
Let’s start by looking at what is different today. To begin with, there is an abundance of data regarding the amount of energy consumed at the macro level, e.g. at the server, the server rack, storage arrays, the data center facilities (be it on premise, co-location, or with a cloud service provider). There are metrics such as the Power Usage Effectiveness or PUE which indicates the overall efficiency of a compute organization (Note: I had a small hand in helping the Green Grid and Jonathan Koomey develop the metric 😊).
However, in a world where customers are driving to an ‘everything as a service’ business model, the granularity of measurements are not good enough to truly identify what is consuming energy. Simply put, while it is the IT infrastructure and hardware that consumes energy and creates a carbon footprint, it is applications that drive energy consumption across the whole infrastructure. While there is innovation happening to measure the detailed energy consumption at a microprocessor level, this is still not detailed enough.
The emissions digital thread for IT needs to start with the software applications!
Pulling on that thread will take the measurement journey from emissions and consumption at the lines of application code, to the server and disk storage devices, the racks that house the hardware, to the data center facilities and finally to the utility supplying the energy. The compounding effect on CO2 emissions and kilowatts consumed of these steps on the original application impact is missing. While taking on an application resource optimization project is not easy, it really does bring financial and environmental savings. It is also a cross functional effort that includes business units, development, procurement, security, facilities management and of course the sustainability office. Finally, the results of this initiative will impact the decision and priorities of any application migration or rehosting as part of any migration strategy.
To start any application resource optimization, businesses need to assume that they need to be prepared to measure each application’s resource consumption whether it’s a legacy standalone application or part of a virtual machine/container environment. By accessing the IT CMDB (configuration management database), map memory, compute, and disk storage resource consumption to validate application modernization and migration priorities. Despite the number of applications to be measured being large in some companies, the 80-20 rule seems to apply. Eighty percent of emissions are accounted for by 20% of the applications.

Often applications get chosen to be migrated to the cloud based on their software licensing costs without knowing what their environmental costs are. However, over the life of the asset, energy costs are frequently larger than the hardware and software acquisition costs. By auditing and mapping the carbon emissions footprint of each application, migration and modernization prioritizations change will result in lower emissions and energy costs. This approach will lead to application development and testing deployment teams having a better understanding of how to embed sustainability into their application portfolio.
Finally, corporate sustainability offices have turned a blind eye to the carbon footprint of infrastructure utilization. Why should they be bothered accounting for something that they believe typically accounts for 4 – 6% of a business’ total emissions? IT is often overlooked as an emissions reduction priority. However, with the advent of emerging technology trends such as AI, Digital Twins, and Edge Computing, data center energy consumption will see an explosion in energy demands to the point that within the next 5 years, the total emissions for IT infrastructure will double. This will put pressure on fossil and renewable energy sources to power the data centers, create water security issues and a larger IT asset recycling problem.
The solution to a successful sustainable IT industry lies in two places. Applications need to be optimized for efficiency as well as functionality. The better the application runs, the larger the savings multiplier will be throughout its value chain. Since applications don’t generate emissions, but rather the compute platform that they run on does, it makes sense to accelerate the investment in significantly more efficient computing by starting at the microprocessor.

How LLMs Are Powering Next-Gen Malware: The New Cyber Frontier
Welcome to the AI cyber arms race, dear reader.
What is the state-of-the-art in LLM-generated malware?
Disclaimer: The following information is for educational and lawful purposes only. Misusing LLMs for unauthorized activities is illegal and unethical. By proceeding, you agree to adhere to all relevant laws and regulations.
Introduction: The biggest LLM risk
The rapid advancement of AI, in particular Large Language Models (LLMs), presents revolutions in cybersecurity, which is defense, and cyber, which is offense. In defensive cybersecurity jargon, which you might be most familiar with, “cyber tools” are called “malware.” Ever wonder what the state-of-the-art is in cyber tools?
Some cybersecurity concerns with LLMs include data privacy, discrimination and bias, attacks on AI systems themselves, misuse of synthetic AI-generated or edited media, using AI to support social engineering cyber-attacks, a lack of transparency and power asymmetry between users and AI companies, and ethical considerations, such as having a human “on” the loop controlling autonomous weapons.
This article is about another LLM risk – one covered much less – using LLMs to develop advanced cyber tools (i.e., malware) that are extremely challenging to detect and defend against. Quoting ChatGPT: “ChatGPT can potentially generate harmful content, including phishing emails, social engineering attacks, or even malicious code. Malicious actors may try to exploit the technology to create malware or other attack vectors.”
How LLMs Generate Malware:
Cyber actors exploit LLMs to generate malware in three ways: they manipulate general-purpose LLMs, buy custom LLMs tailored for cyber-attacks, and train LLMs.
Cyber actors use LLM jailbreaks sold on the dark web as a part of a criminal economy. A more benign “hacktivist” version of an LLM jailbreak is explored here.
Alternatively, cyber actors buy pre-trained LLMs specifically designed for cyber-attacks, such as PhishingGTP, which uses an LLM to generate tailored phishing cyber tools rapidly. These LLMs specialize in one type of cyber tool and do not have the content moderation controls you see in ChatGPT and Gemini. This specialization can make them effective for their intended purposes even if they lack OpenAI or Google’s vast resources.
Lastly, advanced cyber actors, besides buying and chaining together pre-trained LLMs, build their own LLMs to generate cyber tools. Because of the computational resources and technical expertise involved, this is a challenging project, but well within the capabilities of many advanced threat actors. According to Microsoft threat intelligence, Iran has been doing exactly this with LLM-supported social engineering, LLM-generated code, and LLM-enhanced anomaly detection evasion.
Growth areas for LLM cyber tools
LLM-assisted cyber tooling use cases include reconnaissance and vulnerability research, threat generation, personalized attacks, adaptation, and enhanced evasion techniques and security feature bypass.
The initial stages of cyber-attacks, such as reconnaissance, can be automated using LLMs. They can refine proven network management tools, like Nmap, and innovate new methods for vulnerability discovery. Additionally, LLMs can tailor cyber-attack tools to specific targets, making the attacks more precise and effective.
Welcome to Day Zero of the LLM cyber revolution
One interesting use of cyber LLMs is to discover vulnerabilities in target systems and generate exploits for them. The LLM can analyze the entirety of the source code and configuration of the software you use and leverage these vulnerabilities to create cyber tool exploits and attack sequences. This has consequences for zero-day and other time-sensitive exploits.
For commercial software, where the source may be unavailable for LLM training, be aware that cyber LLMs can be trained on disassembled code (assembly code, for example) as easily as they can read open-source code, thanks to tools like Ghidra. Ghidra is a well-known software reverse engineering (SRE) framework developed by the US National Security Agency (NSA) and released to the public back in 2019.
A zero-day attack exploits a previously unknown hardware, firmware, or software vulnerability. This means that a patch to address it does not exist.
Between a patch's release and consumer installation, a one-day attack can take place. The name "one day" suggests a short time frame, but in reality, because patching is delayed, these vulnerabilities remain in every organization for months. The most notable example of a long-running vulnerability is Heartbleed, which Neel Mehta and Michaël Ras of Google's Project Zero security team discovered in 2014. Despite the availability of a vendor provided patch, cyber actors continued to exploit the vulnerability for years due to delays in patching (it was not a straightforward remediation).
LLMs accelerate the discovery of time-sensitive vulnerabilities and increase the effectiveness of cyber tools to exploit them. Cyber actors are eager to launch their attacks before the vulnerabilities are patched in the system they are targeting. Using LLMs reduces the time it takes to make a viable cyber tool (i.e., exploit) enabling cyber actors to successfully attack even systems that are patched quickly.
The forefront in LLMs cyber:
The most advanced use of LLMs in cyber tooling lies not in their ability to create zero day exploits, but in their ability to enhance evasion techniques. AI can generate malware variants with unique characteristics that bypass traditional detection methods. By generating many malware variants, each with unique but functionally equivalent profiles, AI challenges most widely adopted anti-virus detection systems that rely on known patterns. Advanced evasion techniques include content obfuscation through encryption and encoding, polymorphism, metamorphism, and anti-analysis tactics.
Metamorphism is malware capable of rewriting its entire code from scratch in new ways to avoid detection, making it impossible for antivirus software to recognize the threat using traditional methods that search for specific malware signatures. AI's practical application in evasion is not only theoretical, but a reality, with automated and adaptive strategies already in use.
It might be that behavior based cybersecurity tools can help, if the LLMs cannot easily circumvent them as well as the go tos of patching, Continuous Monitoring and Response, Zero trust, Layered Security Advanced Threat Intelligence and cybersecurity awareness training.
This is just a partial list of how and why cyber actors are using LLMs to create and improve cyber tools.
Welcome to the AI cyber arms race
AI-generated malware poses a formidable challenge to traditional cybersecurity due to its rapid evolution, ability to mimic legitimate software, and potential for high-severity attacks. AI's automation capabilities make it difficult to keep up with the constant threat, while the unknown nature of AI algorithms can hinder the development of effective countermeasures. This combination of factors means cybersecurity professionals need innovative tools that leverage AI for cybersecurity to develop effective countermeasures: Welcome to the AI cyber arms race. It’s the only way they have a chance.
Knowledge is power when it comes to protecting digital data and processing. By staying informed about the latest tactics used by cyber actors, we can develop more robust defenses. Understanding cyber actor tactics helps in developing stronger defenses. Resources like Microsoft's threat intelligence reports, which publicly acknowledge the use of LLMs by adversarial nation-states including Russia, China, and Iran, can help us stay ahead of the curve. Additionally, tools such as MITRE ATLAS, dedicated to understanding the adversarial landscape of AI systems, can help improve safeguards.