
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















.webp)
Arm's Data Center Advances: Chiplets, Efficiency & AI Integration
I was lucky to catch up with Eddie Ramirez, VP of Marketing for Arm’s infrastructure business, at the recent OCP Summit. Eddie was last on the show at last OCP Summit talking about Arm’s focus on development of a data center ecosystem, and I was keen to learn about the progress the company had made in this arena. Arm’s advancements in data center technology are making a mark on innovative data center infrastructure with a focus on efficiency, chiplet innovation, scalable solution design.
During the recent OCP Summit 2024, Data Insights podcast co-host Jeneice Wnorowski of Solidigm and I had the pleasure of welcoming Eddie back to the TechArena to better understand the company’s impact across the industry. Arm’s big announcement this year at OCP Summit centered around the power of chiplets to accelerate silicon design. Chiplet technology enables multiple processing units to be combined in a single package, streamlining custom chip design. Arm’s Total Design program enables partners to adopt their cores efficiently, with configurations that cater to diverse needs, from general-purpose tasks to specialized AI processing. This modular integration approach enables flexibility, supporting efficient scaling for data centers that need adaptable configurations for different workloads.
Eight different partners within Arm’s Total Design program announced chiplet projects that they've kicked off, ranging from 16-core to 64-core setups that can be used in a variety of products. One partnership in particular brings together Samsung Foundry, a Korean ASIC design partner, ADTechnology, and Rebellions AI - a startup delivering TPU accelerators. Through this collaboration, Arm has demonstrated how its program helps deliver an integrated design that enables 3X greater performance efficiency than conventional GPU-based solutions – underscoring the power of best in breed chiplet solutions’ role in data center applications. When seeing where chiplet design is going with Arm, it comes as no surprise that this was a focus of OCP Summit, land of the hyperscalers. Arm cores have gained traction among the major players – AWS, Microsoft and Google – which all now integrate the technology in their home-grown designs – utilizing them for internal workloads as well as customer instances.
It's been in Arm’s DNA to provide compute efficient architectures. Their design delivers up to 60% higher power efficiency than x86 servers, allowing cloud providers to reduce power consumption and total cost of ownership (TCO) while achieving sustainability goals. This energy-saving approach is the key to Arm’s success with the hyperscalers, Eddie said, providing them a huge benefit and positioning Arm as an optimal choice for large-scale workloads.
With the rise of AI, the need for GPUs is amplified, especially to train large-scale models. However, CPUs remain essential, particularly for the inference stage, where AI models process data and provide real-time predictions. Unlike training, which demands high power, inference tasks can be handled efficiently by CPUs. Arm-based processors offer a cost-effective solution, balancing performance with reduced energy consumption.
Arm’s reach extends beyond computing into networking and storage within the data center. Arm cores are now embedded in top-of-rack switches, data processing units (DPUs), and baseboard management controllers (BMCs), enhancing efficiency in high-speed data transmission and storage. By deploying ARM cores across types of infrastructure, data centers achieve better resource management and power optimization, aligning with performance demands from AI workloads. This integrated approach allows data centers to streamline operations and enhance energy efficiency at every level.
Arm’s Neoverse platform - the company's infrastructure-focused product line – includes high-performance cores and interconnect IPs for data centers and edge environments. Neoverse’s adaptable architecture enables Arm partners to integrate the latest technology and expand it with additional I/O or storage features.
V3 of the Neoverse platform enhances Arm-based systems’ performance and flexibility, making them suitable for AI and data processing applications. This scalable approach enables data centers to meet growing performance needs without compromising power efficiency.
So what’s the TechArena take? I love chiplets and love what Arm is doing with an ecosystem. This design innovation makes sense for a wide array of use cases, and Arm’s foundation will help the industry move further, faster. Arm’s commitment to energy efficiency, modularity, and open collaboration also aligns well to Open Compute Project tenets, transforming data center infrastructure and offering true differentiation in a crowded field. Through programs like Total Design and platforms like Neoverse, Arm is responsibly building efficient and scalable solutions that meet the demands of AI, cloud, and edge applications.
There is a lot of disruption in the compute landscape with AI acceleration taking center stage. I see two paths of opportunity for Arm…one as a “head node” alternative to x86 with noted energy efficiency advantages, the other as a chiplet core with integration of TPU or other acceleration chiplets as alternative to GPU. Both are exciting to see gain traction in the market, and we’ll keep watching this space for more.
Listen to the full podcast here.

OCP Summit Recap: Innovation, Collaboration & Future Focus
OCP’s Rob Coyle shares insights on AI, cooling innovations, and open hardware’s role in transforming data centers as the industry accelerates toward scalable, sustainable infrastructure.

Boo! TechArena's Spookiest Tech Trends Heading to 2025
Do you hear mysterious footsteps in your data center? Are there otherworldly forces controlling your data? To celebrate Halloween, TechArena introduces the top 3 spooky tech trends heading into 2025.
1) Zombie data: Before you start thinking that the TechArena team spent last weekend with a Night of the Living Dead binge watch, zombie data is a real issue for data centers that's genuinely spooky for its potential costs to IT managers. What is it? Zombie data is data living inside organizations that is, well, dead, because it's tied to sources such as employees no longer at the company. Alive...but dead...hmm.
This is no laughing matter when you consider, for example, that data center storage consumes approximately 25% of all data center power. What can you do to finally put the zombie data to rest? You can tackle this at the individual and organizational level.
Individuals can receive training to delete twice and be aware of potential zombie data sharing from USB drives. Organizations can implement use of data management tools and smart data processing, tapping AI scanning for the undead data stores. Use of professional IT disposal services with an eye on responsible circularity will also help ensure lack of spread of zombie data.
Before we leave the topics of zombies aside, a bonus tip we had to include was TechArena guest Jonathan Koomey's aptly titled Zombie Data Center session at OCP Summit - well worth a look!
2) AI hallucinations: Our number two trend touches on a spooky trend that has run across the headlines of tech media in 2024. While TechArena is headquartered in Oregon, the first state to feature legal hallucinations, this trend is not influenced by that kind of trip. These AI hallucinations are much spookier for enterprises seeking to engage gen AI solutions across their businesses. What are they? In purest form, AI hallucinations are the perpetuation of false information based on that information's inclusion in AI training. This false information can have serious consequences, for example, extending bias into decision making, providing inaccurate recommendations to customers, delivering inaccurate medical diagnoses and spread misinformation. All of these can contribute to cratering a company's brand profile, so the threat must be taken with utmost seriousness.
What can companies do? Doing a great job at data collection and review prior to training an algorithm is a great place to start. This not-as-sexy element of the AI data pipeline helps reduce risk of improper sources getting into corporate AI tooling and cannot be an area that is under-resourced. Tools like RAG can help along this journey, and TechArena will continue to cover solutions to this challenge in the months ahead.
3) Cyborg Revolution: With the 40th anniversary of the release of Terminator this week, TechArena selected the rise of human and machine integration as our penultimate spooky tech trend. For those who do not follow the advancement of cyborg tech, this integration is most advanced in the development of machine controlled artificial limbs, an area that can give new mobility to people who have suffered the loss of a limb. Cochlear implant technology works in a similar fashion, giving the brain new access to hearing.
But...no spooky post would be complete in 2024 without a mention of Elon Musk. His Neuralink effort achieved a milestone in 2024 with the first implantation of a brain chip in a live human brain. With a vision to supercharge human intelligence well beyond the limits of biology, Neuralink and other efforts in this arena may redefine what it means to be human...or who controls humanity. With consideration of that future state that we deem beyond eerie, the entire TechArena team wishes you all a spookiest of Halloweens.

How Software-Defined Vehicles are Reshaping the Auto Industry
On September 1, 2000, Nokia introduced the iconic 3310 mobile phone. In its time, it was considered the industry’s best-in-class mobile phone. Designed to make mobile calls, it could also support texting through an awkward interface that appeared to be mostly an afterthought. If I recall correctly, a few very basic preinstalled games could also be played. In its time, the Nokia 3310 was considered the “must-have” mobile phone.
Seven years later, Apple introduced the iPhone, which forever transformed the mobile phone industry – ultimately creating the new smartphone market segment, which ultimately led to the demise of Nokia and the “fixed function” mobile phone market.
iPhone introduced many changes. Notably, the smartphone was more than just a purpose-built device for placing and receiving calls – it was a platform that supported a wide variety of capabilities and functions with an ecosystem of applications and application developers. These developers provided an ever-expanding library of applications, and more importantly, recurring revenue streams, for both Apple and the developers.
This open platform which supported a recurring revenue stream vaulted Apple to become one of the most valuable companies on the planet. Another lesser, but important detail, is that the same IOS and application can be downloaded via Over-The-Air (OTA) updates regardless of the level of the iPhone or the capabilities associated with a given model (more on the importance of that later).
So what does the transformation of cellular phones to smartphones have to do with the Software Defined Vehicles (SDVs)? Ultimately, it is the same transformation that the automotive industry is aggressively embracing. More specifically, constructing vehicles that are purpose-built for driving – where each model is uniquely designed for low-end to high-end – will quickly become a thing of the past. More importantly, from an automotive OEM perspective, there is a spellbinding allure associated with building a platform that ultimately has lower R&D costs while allowing for after-market revenues.
Tesla has already demonstrated that single-digit billions of dollars can be generated annually in after-market, subscription-based services. In this case, this is to enable ADAS capabilities which Tesla deems “full self-driving” (FSD). Market analysts project that the automotive industry as a whole can realize upwards of $150 billion annually in subscription-based revenues in less than 10 years. This is a game changer for an industry that typically operates on low-digit profit margins relying on dealership revenues coming from service and maintenance to provide some relief on profitability.
Subscription-based services like OnStar, which is offered by GM and provides in-vehicle security, emergency services, and remote diagnostics, have seen nominal traction as the industry grapples with determining exactly which services will be the winning app until vehicles with true SDV architectures come to market. Other notable failed attempts from auto OEMs include heated seats as a service – pay a monthly fee to turn on your seat warmer and remote start as a service – pay a monthly fee to start your car remotely.
As discussed in an earlier blog “From Chaos to Control: The Future of Automotive E/E Architecture,” the centralized E/E architecture is required to enable the vision of the SDV to be fully realized. As mentioned in that blog, for the incumbent OEMs, the transition from a legacy architecture to a centralized architecture is a complex, extended process that will take years to unfold. That said, the promise of large, profitable aftermarket revenues provides very meaningful motivation and tailwinds.
Because a common hardware platform can be used from a high-end through low-end vehicle, the overall R&D costs will be reduced in addition to a reduction in the time to a minimum viable product. It may be, that the “perfect” full-featured vehicle may not be available upon vehicle introduction, but over time and through Over-The-Air (OTA) upgrades, this can be addressed in time.
What has changed is that the personality and the capabilities of the vehicle are now defined via software – hence the term Software-Defined Vehicle. Similar to the IOS of an iPhone, one common software footprint will be deployed across all platforms and the specific capabilities of each model will be determined based on model type and associated population of vehicle sensors.
To that extent, personalization will be possible on a vehicle-by-vehicle basis and based on user preference. Furthermore, the capabilities of the vehicle can be upgraded over time by simply adding sensors that enable additional capabilities that weren’t present, for example, in a low-end vehicle. These sensors can be purchased later by the car owner and quickly installed like adding an add-on card in a personal computer. Again, these are all new business models and opportunities for new revenues that were previously not possible with older E/E architectures. With this vision in mind, there are industry efforts underway to support “programmable exterior paint” so the car owner can change the color of the vehicle at any time over the lifetime of the vehicle, or, daily, or hourly – for a price, of course.
Not only can external capabilities and various features be upgraded or enabled over time, the interior, or cockpit, of the vehicle can be tailored to the desires of the vehicle owner. There was a popular term referred to as software-defined cockpits (new terms go in and out of vogue quickly) and not only reflects the ability to tune the cockpit to the owner’s desires but the cockpit can be modified based on the individual driving the vehicle at the time. Furthermore, when coupled with AI, these changes can be made automatically based on recognizing the driver’s mood and tuning the cockpit accordingly. The range of possibilities is endless – from user-defined lighting styles, vehicle temperature, and music selection based upon a measure of the driver’s biometrics, an understanding of their calendar, their habits, traffic conditions – the list goes on and on. It’s very safe to expect that there will be many failed and crazy ideas, but the opportunity cost will be nominal since it’s all mostly software.
But it is a LOT of software. The modern car is projected to grow from 100 million lines of code to 1 billion lines of code within roughly a decade. With Windows 11 at 50 million lines of code, the automobile already contains the most lines of code of any application and that is about ready to explode. Seamless orchestration of software updates with appropriate levels of security and safety will be paramount to success. As the overall control of so much of the vehicle will be under the control of software, the importance of cybersecurity at this point can’t be overemphasized.
Will this vision of the future resonate with every car owner? Probably not. There will be those who probably want to go back to the good-old days when they had their Nokia 3310 that simply just placed calls and texts and had a game where the snake chased its tail.

Digital Ethics in AI: 3 Key Considerations for Leaders
In the last year, we’ve seen significant growth in the adoption of artificial intelligence (AI). One way to judge a technology’s maturity is to find its place on the Gartner Hype cycle. The challenge here is that “AI” is an umbrella name for a variety of distinct AI systems. And thus, there is no one place where we can put AI, but rather AI deserves multiple entries in the hype scale to demonstrate its true impact according to this measure.

Expert systems and narrow AI are more mature as they move into the plateau of productivity. But one of the more familiar systems, Generative AI, seems to have moved beyond the Peak of Inflated Expectations into a phase where companies are grappling with practical implementation challenges like ethical concerns, computational demands and sustainability challenges.
While this big technological revolution has enormous potential, implementing AI comes with its own set of unique challenges. We’ve all seen some of the more public examples of what can happen when AI gets it wrong – including recent instances of AI applications showing bias. This is where businesses need to de-risk the implementation of AI and ensure AI systems can be a force multiplier for the business rather than a counterproductive or disruptive element.
From an ethical perspective I believe there are three high level considerations for organizations determining their AI strategies.
- Bias & Fairness
The first thing is to have a good awareness and understanding of the system you are implementing and WHY. It’s important that this awareness and understanding spans your organization from procurement to senior leadership so all involved in the decision process can ask the right questions. Many free resources exist to get educated on the strengths and weaknesses of AI technology. This technology is rapidly evolving, so it is important to stay informed about the status quo.
Without awareness and understanding, we focus on the promise but overlook the implications. While you could potentially have significant gains in productivity, the flip side is that your AI system may be generating unfair outcomes because it’s biased and/or is discriminating. I’ve seen it firsthand when a client I was working with experimented with a vision-based recognition system for advertisement that didn’t work for people from certain demographics.
2. Transparency & Explainability
The other part of this is the WHAT. Be very clear on WHAT you want to achieve by implementing the technology and what benefit you want to realize. Once that is clear, de-risk the ideal outcome. Per example: If you implement a computer vision system, what happens when an image is identified with a false-negative or positive? When you use a supervised learning system, what are the label criteria and how are they applied? Or what if your NLP system gets the translation wrong ever so slightly? What could the worst impact be? How do you ensure the quality of your answer? And if it is not accurate, how do you inform your audience of this possibility – very much like that sticker on your car mirror?

AI is a transformative and very powerful technology, but it’s also a black box technology – meaning its decision criteria and decision-making process are very hard to reverse engineer to verify and ensure accountability. Some good news here is that developments on XAI (explainable AI) are underway and rapidly evolving too. Another related research area of interest is machine unlearning, which will help further refine models when old, illegal or incorrect data need to be removed from existing models. Several universities and big tech companies are researching this capability. Both examples underline my initial point to keep abreast of the latest developments.
3. Privacy & Data Security
AI, by nature, requires large amounts of data to train and improve its models. Frequently, this can include private and personal data, which is a concern for how data is collected, stored and processed. And while regulations such as GDPR are put in place, the pace of AI innovations is already challenging these legal frameworks in areas like data minimization, user consent and decision making. Per example: AI algorithms could leverage personal data in ways that weren’t foreseen when collecting this information, making it very challenging to get informed, and specific user consent, that GDPR requires.
Methods to address these challenges include data minimization and anonymization techniques and informing users that the data they submit for collection and processing can be used for AI purposes. As stated before, this is complex to implement, but certainly something to keep front-and-center when discussing AI.
Awareness and Education
Implementing AI requires continuous education and awareness. This is critical as this field and its capabilities are ever expanding. With the arrival of Generative AI, there has been mass adoption, but it has not been accompanied by mass education. This is a gap that will need to be addressed over time. Education moves slowly, but it has big impact in the long haul.
Driving more awareness of AI capabilities is at an all-time high as AI is right on top of the hype cycle and projections of economic gains in productivity are skyrocketing. This drives natural interest and hype from the industry. But awareness for some of the limitations and impact of AI and some of the ethical solutions is low and it’s up to us in the industry to share the learnings.
One of the best examples to date that I’ve seen is this highly educational YouTube video by Andrej Karpathy who is an AI researcher who worked at OpenAI and Tesla. Not only does he explain and provide examples of how Large Language models (LLMs) work, but he explains the security risks of LLMs (timestamp 45:44) and how prompt injection, data poisoning and jailbreaks can affect LLMs. He provides examples for these scenarios, too. The industry needs more of this kind of content and educational leadership.
There is more to be optimistic and encouraged by. I recently attended the Worldsummit.AI event in Amsterdam. And besides real-world implementation examples, it had dedicated tracks for responsible AI and governance and HUMAN-AI convergence and created a platform to discuss the current and future impact of AI on society. It’s clear that the democratization of AI comes with lots of benefits, but it also includes a worrying factor. Next to all the technological limitations, there are also the malicious actors who will continue to exploit this technology, which adds to the complexity of managing it all. Legislation will help mitigate some of the negative impacts.
Walking away from these two intense days, I’d like to share some observations from my discussions:
The first one is, “Every company is an AI company,” whether they have a strategy or not. Employees are experimenting and implementing.
The second one is that AI risk assessments seem to be the biggest driver of use-case adoption in the industry now. This assessment is typically done by an independent third party. And it seems to be a good balance between innovation and (to a degree) ethical implementation. It puts tension in the system on the checks and balances of outcomes and impact.
However, as one panelist discussing third party validation of AI mentioned, “Some things are checkable; some things are not...”
In summary
As with any technology, it’s critical to keep an open, curious and objective mind when thinking of AI applications and ensure due diligence on the digital ethical aspects of the implementation. We are all students of this new technology, so it’s on us to put the right guard rails in place.
Get Involved
If this topic holds your interest, I’d love for you to join the D.E.A.P. (digital ethics awareness platform) LinkedIn group. I’ve recently created it with the intent of bringing more awareness to the capabilities and ethical solutions and research available. This way, we can all make better informed decisions. Feel free to join and contribute relevant information here: https://www.linkedin.com/groups/13079342/.

OCP Insights with Scott Shadley: AI, Collaboration & Storage
Join Allyson Klein and Jeniece Wnorowski in this episode of Data Insights as they discuss key takeaways from the 2024 OCP Summit with Scott Shadley, focusing on AI advancements and storage innovations.

3 Top Takeaways from OCP Summit
The Open Compute Project Foundation’s OCP Summit is a haven for the cutting edge of tech requirements and a hub for the industry connections that are needed to solve them.
The event was the first that TechArena sponsored starting in spring of last year, and this past week was a humdinger for new insights on the industry. In my post about what I was looking forward to from the Summit, I'd identified performance, power and cooling, and standards as topics that I'd be tracking through the week, and the Summit delivered in spades across all fronts. Let's explore!
1. Performance: As we get into the late dawn of the AI era, the persistent need for more performance as quickly as possible is not abating. In my talk with Google's Amber Huffman, she called out a need for yearly platform innovation, faster than Moore's Law, that stresses every element of infrastructure design (more on this later). This acceleration of the industry was reflected in everything I saw at OCP. First, there was the sheer size of the event – at over 7,000 people – coupled by a massive leap in sponsors and a mushrooming of content. OCP has become a central hub for what's next in data center computing, well beyond a reference design for the elite.
The attitude of vendors underscored how massive a business opportunity this moment is for all. There's a lot of business to be had with new investment in infrastructure to fuel AI, and while vendors are being pushed to innovate, being brought in earlier to align technology, and being pressured to ensure supply, there is a bright-eyed optimism that the concept of an AI hype cycle does not reflect the tsunami of purchase orders fueling hyperscale data centers. And OCP, once a very CPU-centric event, featured NVIDIA's debut of a Blackwell platform design, a keynote, and a first-of-its-kind presence at the show. Not to be outdone, AMD showcased its right-out-of-the-fabs 5th Gen EPYC and MI325X platforms at the show, very much targeting Blackwell momentum while also placing a huge reminder on the growth of AI inference ahead. And while Intel was present at the show with a keynote, the torch of leading-edge platforms has squarely passed to an NVIDIA - AMD battle for long term superiority.
The most interesting thing about the performance talks at OCP was not the shift to GPU-centric designs or advance of CPU, GPU and broad acceleration offerings...it was open discussion of model delivery with more efficiency in mind. Many technologists at the show remarked to me that the industry needs to chart a path forward that puts into question the endless pursuit of vector processing on steroids in favor of disruptive compute algorithms that advance AI without the computational cycles or energy utilization on our current trajectory.
We've come to these moments before at smaller scale. Video delivery comes to mind, where the value proposition of what was to come seemed out of reach based on what was then an inability to render, transcode and deliver at scale. That was, until new technology paths were found, in this case with parallel advances in compute, networks, and compression technologies. I do think the industry is seeking a similar answer to AI and would not be surprised at all if we see new algorithmic approaches, math, compute architectures...something...as the center of discussion at OCP Summit 2025. Expect more reporting from TechArena on this in the months ahead.
2. Power: While performance scale and greenfield deployment is being ushered ahead with frenzy, the power draw that it's requiring is eye-opening. We published our TechArena Data Center Compute Efficiency Report in advance of OCP Summit, and the conversations at OCP, regardless of where they started, at some point came to a question on what power demand will be required ahead.
One thing that was notable to me was how quickly we've all pivoted to a new normal that hyperscalers are now running nuclear power plants. Nuclear was discussed as a part of the power equation in a way where it was a future consideration just six months ago. For those who have not been following the plot on this topic, Microsoft kicked off the nuclear conversation with their eye-opening announcement regarding the re-opening of Three Mile Island on September 20, quickly followed by Amazon's announcement of their own nuclear deal last week and Google's move yesterday. Think about this: Either the big three were playing a massive game of chicken on who was going to take the nuclear plunge first, or these companies can truly pivot on a dime to deliver groundbreaking business moves at massive scale. My bet is on the former reality as the companies continued to struggle with sourcing power from traditional grid. Regardless, nuclear is now being referred to as a carbon emission-free, positive alternative to other power sources that will free up electricity to fuel mountains of compute for AI. And with all of this power-rich compute, the liquid cooling industry is about to go bonkers. Everyone and their brother is now offering liquid cooling solutions; ODMs are rushing to integrate both direct and immersion solutions to their portfolios, and the liquid cooling players – once the niche industry relegated to the HPC arena – are being gobbled up by larger players at a stunning pace. Just last week Flex announced a strategic collaboration with JetCool and Schneider announced the acquisition of Motivair following on the footsteps of Jabil's acquisition of Mikros (who was an independent entity at last month's AIHW Summit, showcasing how rapidly these moves are playing out).
My question about the liquid cooling market is not that the hyperscalers – forecasted to be a majority of infrastructure sales in the next couple of years – will use liquid cooling. It's how far liquid will...well, flow. Will we see this migration to liquid immerse itself into the enterprise as organizations build their petit versions of training clusters? (And will enterprises build compute-intensive training clusters or opt for smaller models?) As enterprises adopt AI, will these configurations be deployed in edge environments, taking liquid cooling to these harsher locales? We'll continue to explore these questions in the months ahead, but for now, I expect to see continued consolidation in this space as solution providers position themselves for competitive advantage in the market.
3. Standards: Competitive advantage in the market also takes us to our final topic, standards. When I called out standards as a trend I was hoping to hear more about at the Summit, I did not imagine the Intel - AMD kumbaya that occurred from the keynote stage with the companies joining together in x86 instruction set harmony. While it's undebatable that this was a surprise development, the really interesting question is why it's happening and why now.
GPU rise has placed a foundational fear within x86 land that general purpose computing is dead. Those who are not media trained by their companies may state that fear as bluntly as I've written it. And moments of fear create strange bedfellows, in this case the once lofty Intel realizing that a collaboration with their arch-rival places them in a much better position against accelerated computing that the traditional hands-off approach that has defined the last two decades plus of x86 land. While I believe customers win with this collaboration (and think that general purpose computing and mixed workload configurations will keep x86 alive and kicking for some time – after all, mainframes are still running strong), I also think that my first question of a need for a different architectural approach to AI performance may, in part, be answered from this collaboration.
There is more to unpack from OCP Summit in the weeks ahead, but one thing is clear: While some companies came into OCP Summit leaping (i.e. liquid cooling companies, NVIDIA) and others limping (i.e. Intel), the entire industry is operating at a pace and fury that will unleash new compute capability. And if you believe AI will deliver to the promise of business and societal change that its proponents profess, we will all win from the engineering advancements that the community is delivering. More to come.

Insights on AI & Sustainability from Jonathan Koomey
Jonathan Koomey of Koomey Analytics shares insights on AI’s role in energy efficiency, sustainability, and the tech sector’s potential to address climate challenges in this must-listen episode.
.webp)
Inside AMD’s Vision for AI and Data Center Evolution
In this episode of Data Insights by Solidigm, Ravi Kuppuswamy of AMD unpacks the company’s innovations in data center computing and how they adapt to AI demands while supporting traditional workloads.

Keysight’s AI Test Platform: Optimizing AI Networks for Data Centers
The Keysight AI Data Center Test Platform is designed to meet the unique demands of high-performance communications within AI clusters. It provides capabilities such as emulating AI workloads, benchmarking AI network infrastructure, and co-tuning AI cluster performance, making it ideal for sustaining complex AI workloads in the data centers.
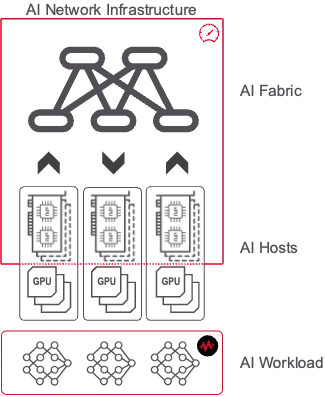
Why Is Networking Important in AI Data Centers?
The AI data center relies on a robust network infrastructure known as the AI Fabric. This network facilitates the transfer of large volumes of data between AI Hosts and ensures fast, high-capacity communication to effectively train AI models.
A reliable and efficient network infrastructure prevents data bottlenecks that can slow down AI model training and reduce overall infrastructure efficiency. Keysight’s AI Data Center Test Platform provides a comprehensive solution for testing, validating, and optimizing these networks to meet the demanding requirements of modern AI workloads.
Key Features of the AI Data Center Test Platform
Emulate AI Workloads:
The platform emulates real-world AI workloads, allowing AI operators to stress-test their networks with the same data patterns in production environments. This helps identify performance issues and bottlenecks before they affect real-world AI applications.
Benchmark AI Network Infrastructure:
The platform can benchmark key network elements, assessing the AI Fabric's performance. This process is crucial in ensuring that the network infrastructure can effectively handle AI workloads' high-throughput, low-latency demands.
Co-tune AI Cluster Performance:
Optimizing the AI infrastructure and the network fabric is essential to achieving peak performance. The platform offers tools to co-tuneAI hosts and their connected network infrastructure.
Integrated Software, Hardware with a Fabric Test Methodology for AIWorkloads
Keysight’s AI Data Center Test Platform delivers flexible and comprehensive solutions through both software and hardware components, tailored to optimize AI workloads and network performance.
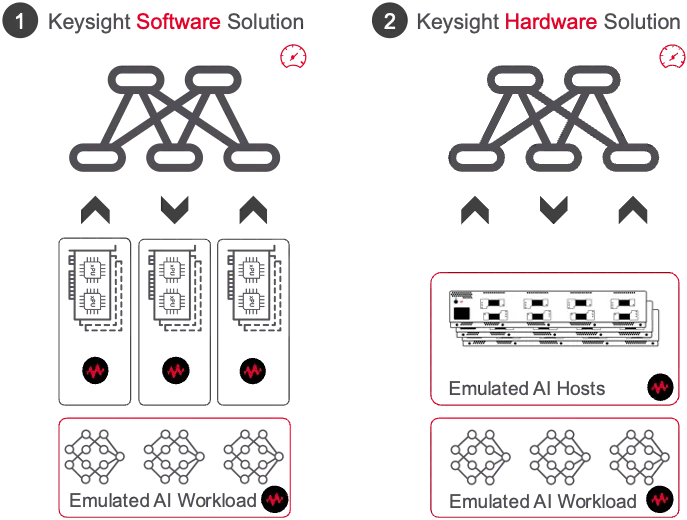
The software solution offers cost-effective validation, supports new transport protocols, and is ideal for production and cloud environments. Key benefits include minimal overhead with NIC+Fabric co-tuning for efficient network management. This solution enables AI emulation and workload validation without the need for large-scale infrastructure, making it suitable for cloud-based environments.
The hardware solution focuses on isolated fabric validation, providing a high-performance infrastructure capable of handling up to 800G throughput and delivering deep network insights. It allows users to test and validate their AI infrastructure while emulating real-world AI workloads, ensuring reliable results for performance benchmarking.
At the core of both solutions is the Fabric Test Methodology, which ensures that network fabrics are validated independently and optimized for AI data center demands. This methodology allows users to qualify AI network fabric efficiency in job completion time, performance isolation, load balancing, and congestion control mechanisms.
Conclusion:
Keysight's AI Data Center Test Platform is designed to validate network design at the core. AI clusters depend on efficient communication for optimal performance, and this platform provides superior capabilities for validating and fine-tuning network architectures. It is essential for identifying weak points in the AI fabric or optimizing data flow between GPUs, making it crucial for building next-generation AI data centers.
For more information please refer to our AI Data Center Fabric Test Methodology Black Book.

Inventec Delivers Cutting-Edge Cooling for AI Workloads
In this episode, Inventec’s Edward King discusses how AI workloads are shifting to the edge, and how innovations like liquid cooling and ruggedized infrastructure can power the next wave of tech advancements.

AI’s Impact on OCP: Scaling Innovation and Infrastructure Growth
In this episode, OCP CEO George Tchaparian shares how OCP is driving AI infrastructure innovation, fostering collaboration, and tackling scalability, efficiency, and sustainability challenges in data centers and beyond.

From Chaos to Control: The Future of Automotive E/E Architecture
With Halloween just around the corner, it seemed appropriate to bring a little intrigue and mystery into this week’s blog. In the heart of Silicon Valley is the Winchester Mystery House which, throughout the years, has grown to become a relatively popular tourist attraction.
Owned by Sarah Winchester, the heiress of the Winchester Repeating Arms fortune, (think Winchester rifles), this mansion was constructed over the course of 36 years from 1886 to 1922. The legend goes somewhere along the lines that she regularly heard haunting spirits tell her that tragic things would happen if she ever stopped construction on the house. This was the motivation that caused her to transform her eight-room farmhouse into a 24,000 square foot mansion with 160 rooms, 47 stairways and fireplaces, with 13 baths, 6 kitchens and a host of other amazing factoids regarding the ridiculous size and scale of this mansion.
Beyond its sheer scale, what is most unique about this mansion is that these rooms were added on with very little rhyme or reason or forethought. Sarah Winchester’s obsession with adding rooms led to a floor plan where the location of the rooms and the function that they served were irrelevant. The resulting mansion, that over 12 million people have visited since it was opened to the public in 1923, is a hodgepodge of illogical rooms, hallways, and dead-ends.

Perhaps a harsh analogy, but in a similar fashion, it feels like throughout the years, the automotive industry has continued to add more and more electronics to the vehicle employing an E/E architecture with similar levels of forethought as Sarah Winchester’s floor plan. The continued addition of electronics has led to high-end vehicles with over 130 microcontrollers that are physically located wherever it seemed to make best sense at the time – resulting in what’s commonly referred to as distributed architecture. The resulting wiring harness required to interconnect all the distributed microcontrollers and other devices, has grown from 55 wires with a total length of 150 ft in 1948 to the present day where the wiring harness for a vehicle based upon a distributed E/E architecture weighs roughly 120 lbs and contains 1,500 to 2,000 wires with a total length of 5,280 feet (one mile).
To a certain degree, it’s not too hard to see how this distributed architecture may have come into existence. More than two decades ago, the automotive OEMs viewed electronics as context, not core to their businesses. This led to the eventual spin-out of the OEMs’ EE teams and the formation of Tier 1s, an external company that had indirect responsibility for the OEM’s electronics and associated E/E architecture.
Today, automotive OEMs are becoming acutely aware of the importance and impact of both the electronics and the underlying E/E architecture. This is driving the mature OEMs to shift back to their original model where the electronics teams were vertically integrated. Fun fact, I have been told that this trend is not uncommon across different industries and that the Harvard Business Review refers to this shift from dis-integration back to vertical integration as “the double helix.”
With this greater, more immediate focus on the electronics and underlying shift to greater control of the vehicle through electronics, there is a similar increase in focus by the OEMs that is placed upon the underlying E/E architecture. More specifically, there is a keen focus on how to reduce the size, weight, complexity, cost, and associated poor reliability of the wiring harness. The impact of the wiring harness, which has typically been considered innocuous, has now become very significant.
EV startups without the baggage of legacy architectures have mostly embraced the centralized E/E architecture, which holds the promise of addressing all the above-mentioned challenges associated with the distributed architecture. However, for most mature automotive OEMs with legacy architectures, the move to centralized can prove too much of a stretch. So the approach is to move from a distributed architecture to a domain architecture and then eventually to the centralized architecture.
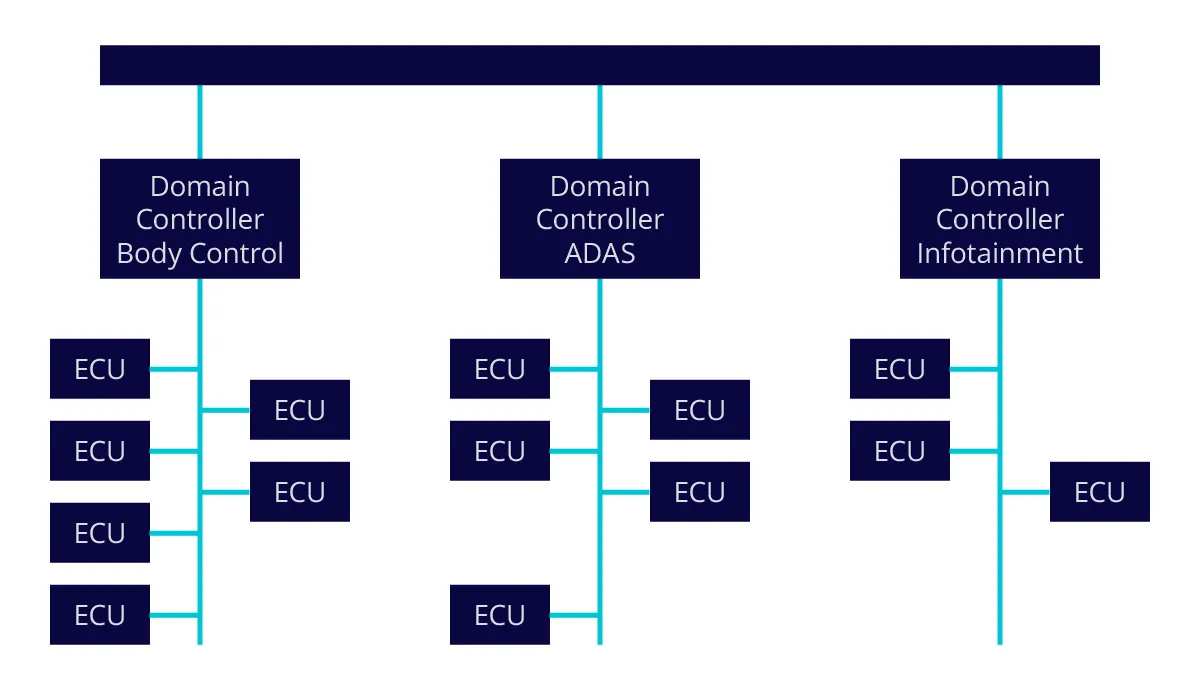
Domain controllers allow for rich communications between electronics control units (ECUs) within a common domain, while isolating unrelated communications between other, unrelated domains.
As shown in Figure 1., one of the key concepts behind the domain architecture is that not all electronics control units (ECUs) need to communicate with one another at all times. This concept is similar to the way that office computer networks are typically constructed. Breaking the network traffic into local area networks with common communication needs leads to greater efficiency and reduced costs. As an example, personnel within an engineering department need to regularly communicate with others in the engineering department, but less frequently with personnel in the shipping department. Breaking these groups into two unique local area networks, i.e. engineering and shipping, allows for rich communication within each group and isolation between the two groups via a bridge. This allows only relevant conversation between either group to occur, and leads to a reduction in wiring while greatly improving communications throughput and reliability.
While the domain architecture offers significant improvements over the distributed architecture, the physical location of the different ECUs directly impacts the physical length of wire required to connect to the appropriate domain controller. The centralized architecture, on the other hand, addresses wiring length and provides many additional, significant benefits.
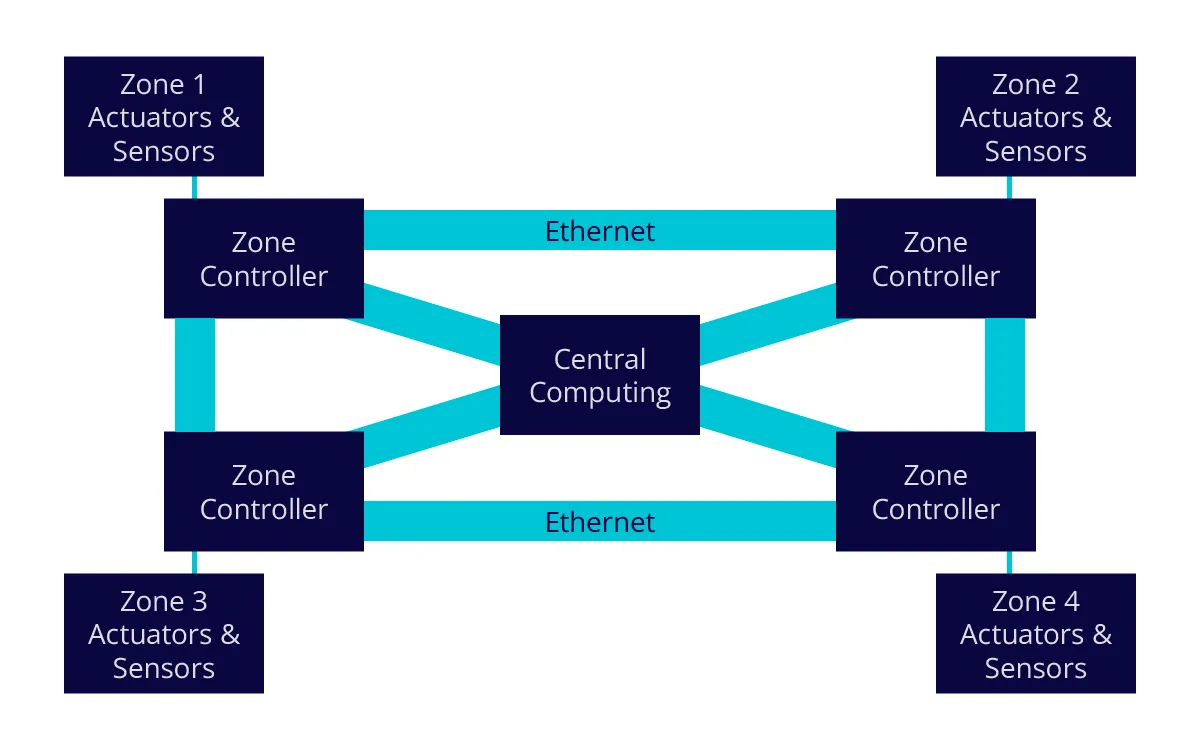
The centralized architecture, as shown in Figure 2, is the eventual, target E/E architecture for most incumbent OEMs. While there are variations on a theme of this actual architecture, typically what they all hold in common is the majority of the computing is aggregated into one common, centralized location. The zone controllers are physically located in different quadrants of the vehicle and connect the different actuators and sensors that are found in the same physical location of a given zone.
For purposes of definition, an example of an actuator would be the physical controller that engages the brakes in the case of anti-lock or automatic emergency braking, whereas a sensor might be a camera or radar that is again, located in the given quadrant, or zone of the vehicle.
As noted in Figure 2., the different zone controllers are interconnected via Ethernet in a mesh configuration – implying that every zone controller has more than one way of connecting to the central computing block. Ethernet connectivity is chosen because it is a very mature, proven, robust serial communication technology that relies on lightweight cabling for connection. Variants of Ethernet, including TSN (time sensitive network) are gaining momentum in automotive as they offer greater levels of determinism in communication timing performance, typically a requirement in real-time embedded applications.
Employing a mesh-based connectivity architecture allows for one or several segments of the network to fail without impact. The network simply seeks an alternative connection path, which is enabled through this scheme. This connectivity topology is typically found in today’s data center in support of what’s referred to as a “fail-over” architecture. As previously mentioned, in many different ways, the vehicle of the future is increasingly becoming a data center on wheels.
The centralization and consolidation of compute resources also leads to a significant reduction in the total number of discrete ECUs while also more readily accommodating computational redundancy, again leading to greater levels of reliability.
Within a given zone, the sensors and actuators can be added based on trim level of the vehicle in a manner similar to populating a PC with a new add-in card. The sensor or actuator identifies its presence and personality to the centralized computer via a unique IP address and the vehicle’s computer’s operation is updated accordingly. This allows for greater levels of simplicity in the manufacturing of different classes of vehicles, which typically contain different numbers and types of sensors and actuators. Different types and numbers of sensors are added on the manufacturing floor based on vehicle type or level. This type of “plug-and-play” also supports the concept of upgrading a vehicle to a higher trim level years after the vehicle has left the showroom floor.
With software scaling into the 100 to 300 millions of lines of code, the importance of practical support of over-the-air OTA software updates cannot be overstated. The distributed architecture with over 130 MCUs that are distributed throughout all corners of the vehicle, does not lend itself to simple OTA updates. A similar point can be made in regards to the manner in which the centralized architecture leads to a more rational and practical way to address cybersecurity.
Without a centralized architecture, the hot industry buzzword, Software Defined Vehicles (SDV) would be almost impossible to realize.
In the same way that the evolving E/E architectures are driving transformation, the SDV is also poised to transform the auto industry in even more significant ways.
This is, however, another topic that I will discuss in a future blog.

Roy Chua of AvidThink on AI, Networking, and Sustainability at OCP
Allyson Klein and Roy Chua, founder & principal of AvidThink, explore AI-driven networking, sustainability challenges, energy efficiency, and more in this insightful episode, recorded at OCP Summit 2024.

Exploring AI Innovations: Chen Lee of Gigabyte at OCP Summit
Join host Allyson Klein and co-host Jeniece Wnorowski in this episode of Data Insights as they chat with Gigabyte's Chen Lee about AI innovations and the future of server technology at OCP Summit.

Ocient: Revolutionizing Data Warehousing for AI Workloads
Live from OCP Summit 2024, this Data Insights podcast explores how Ocient’s innovative platform is optimizing compute-intensive data workloads, delivering efficiency, cost savings, and sustainability.

JetCool's Innovative Liquid Cooling Tech Powers High-Performance AI
JetCool Founder & CEO Bernie Malouin discusses the company’s breakthrough liquid cooling tech, which targets processor hotspots with jets of coolant to boost efficiency across intensive workloads.

Google Cloud’s Amber Huffman on AI, OCP & Future Innovations
Live from OCP Summit, Google Cloud’s Amber Huffman shares insights on AI's future, open standards, and innovation, discussing her journey, data center advancements, and the role of collaboration at OCP.

GEICO’s Rebecca Weekly on IT Transformation and OCP Innovation
In this episode, Rebecca Weekly shares how GEICO is rethinking cloud strategy and embracing OCP for improved efficiency, security, and cost savings in its infrastructure journey.

From Desktops to Data Centers: Zane Ball on Silicon Innovation
In this episode – recorded live at the OCP Summit – host Allyson Klein catches up with Intel Corporate VP Zane Ball to discuss silicon innovation, AI evolution, and the future of enterprise adoption.

Data Insights: Arm’s Eddie Ramirez on Data Center Innovations
Join Allyson Klein and Jeniece Wnorowski as they chat with Eddie Ramirez from Arm about how chiplet innovations and compute efficiency are driving AI and transforming data center architecture.

CoolIT: Revolutionizing Data Centers with Liquid Cooling Tech
Learn how CoolIT Systems is driving efficiency and performance in AI and data centers with cutting-edge liquid cooling solutions in our latest Data Insights podcast.

How Flex Manages Power, Heat and Scale in the AI Era: Part 2
Join us as Rob Campbell from Flex discusses the challenges and innovations in data centers, focusing on power, heat, and scale, while shaping the future of AI and sustainable solutions. This podcast is the second episode in a two-part series. Listen to part 1 here.

How Flex Manages Power, Heat and Scale in the AI Era: Part 1
Rob Campbell of Flex discusses how Flex is driving data center transformation with cutting-edge solutions like liquid cooling, AI-ready infrastructure, and vertical integration for global hyperscalers. This podcast is the first episode in a two-part series. Listen to part 2 here.

A Trio of Trackable Topics at OCP Summit
The OCP Summit kicked off last night with its customary opening reception. This event is the highlight of the year in how hyperscale infrastructure is advancing, and this week's Summit is rumored to be the largest in history.
The elephant walking the halls of the San Jose Convention Center is how infrastructure will adapt to the continued pressure of AI performance demands, and whether open hardware design pivots to a world where performance density and acceleration are the keys to the kingdom. The TechArena is delighted to once again be a media sponsor of the event, and we'll be delivering key takeaways from the show all week. Here are the top things we're targeting for the biggest news at the event:
Performance: How will OCP pivot its focus to address the world of accelerated computing? This is on top of many people's minds at the show that has been dominated by CPU-centric designs for over a decade. This year's Summit is different, with NVIDIA taking a much more visible role in the proceedings and NVIDIA having delivered reference designs to OCP for construction of rack-level AI compute. We'll be tracking how much NVIDIA technology is being embedded into OCP workstreams within our conversations with both members of the foundation and industry representatives.
Power and Cooling: With emphasis on expansion of data centers and delivery of more watts per square foot, the power and cooling industry will be out en masse at this week's Summit. Last year, Submer made waves, literally, with an immersion cooling tank system that got everyone's attention. This same tank was featured in yesterday's podcast with CircleB. However, the discussion on direct-to-chip and immersion cooling approaches continues to bubble, and we expect to hear a lot from the industry on cooling advancements, collaborations like the one announced by Flex on our podcast today, and discussions of dielectric alternatives sending chem geeks into molecular bliss.
Standards: Last year's Summit featured a major announcement about Ultra Ethernet, and AMD made waves yesterday with the introduction of the first Ultra Ethernet adapter to hit the market. We've seen standards advancements in scale up networking, chiplet designs and expect to hear more about memory advancements at the conference. We'll be covering all announcements from the show through interviews with standards leaders assembled in San Jose.
Are these the topics you're seeking from OCP Summit? Follow along by following us on LinkedIn, subscribing to our feed or connecting with us to provide feedback on what you want to hear about most.