
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















.webp)
CloudFest 2025: Honing the Human Edge
After a smooth plane ride and quick car ride via the German autobahn, I arrived in EuropaPark. For four days, the quiet city of Rust was the home of the world’s leading cloud conference, bringing together the industry’s largest players, eager start-ups, and those passionate about how cloud is changing our future.
Bringing together cloud service providers, system integrators, corporate IT, resellers, platform integrators, open source professionals, OEMs and distributors across 90+ countries and with an impressive number of 9,000+ participants, CloudFest 2025 was the place where tech met humanity. Major topics revolved around:
- Human centric AI – How can the integration of human empathetic oversight in the latest AI driven hardware enhance performance and service delivery
- Cybersecurity and networks – How human vigilance and expertise safeguard the digital infrastructures against continuously evolving threats
- Service is everything – Innovations in products and services that deliver delight to customers through human-centered design and empathetic human interactions, making the difference in a cutthroat market
Through advanced AI technologies, 1SP Agency together with MSM.Digital, brought Albert Einstein to life and into CloudFest, for a fireside chat with Soeren von Varchmin, CloudFest’s Chief Evangelist. Einstein delved into his groundbreaking theories, his perspective on modern advancements, posing the troubles arising from conflicts and inequalities, as well as his hopes of a future where reason, compassion and cooperation guide humanity. His invitation to everyone in the audience was to never let their curiosity wane.
Lenovo made a solid case around liquid cooling in data centers. A decade ago, the company brought liquid cooling in data centers to address overall performance and sustainability. John Donovan, Executive Director & GM of MSP, spoke about how today the discussion is around what data centers are capable of, design constraints, total cost of ownership (TCO), sustainability, competitive forces and regulatory actions. And liquid cooling comes as an attractive solution to the high energy spend happening in data centers, who use a significant 3% of global electricity resources. Out of these 3%, 40% is used to cool and by 2030 the numbers quadruple. Reasons are many: CPUs usage increase, memory, smart mix, addition of GPUs, more wattage used, more heat generated, more power used to remove the heat. Lenovo proposes Neptune technologies (DWC + Open) which meet criteria on environmentally friendly, hassle-free maintenance, high quality tubing and hoses, low pump pressure and pre-tested and shipped air pressurized. Using warm water, a single CDU that can manage 400 kW of heat rejection to water only consumes 3.7 kW of power. A CDU can provide 4x heat rejection to liquid for 10X less power than air cooling.
Esther Spanjer, Micron’s director of channel business development, introduced the topic of how AI is stretching the limits of data centers from a performance, capacity and energy efficiency perspective. On memory and storage, the quest for bigger memory and better capacity continues. The current EDSFF (Enterprise and Datacenter Standard Form Factor) E1 is optimized for 1RU servers, supports data and boot use cases and targets mainstream data center use; while E3 is optimized for 2RU servers, maximizes power envelope and supports a broad range of storage, memory and specialized use cases. Micron introduced Micron 6550 ION NVMe SSD, the world’s fastest, most energy efficient 60TB data center SSD. It has best-in-class 60TB performance, uses up to 20% less power and it can store up to 67% more per rack. It comes in 30TB and 60TB capacity, PCI Gen 5, and the form factor E3.S, E1.L and U.2. Data gets pulled faster, which means that expensive GPUs don’t sit idle. And as a side effect, more drives can be squeezed into a server: 40 E3s SSD drives in a U2 server.
CloudFest turned to its members in 2023 and 2024 to learn about the current state and future of the industry and they did the same this year. Brooke Edge, from Open Eye, presented the state of global cloud market report and the trends for 2025. With a sample of over 600 global responses, in-depth expert interviews, and fill in date with ~1 week before CloudFest, the report passed statistical significance. 2025 outlook is not as bright as it was in 2023 and brings additional stressors that factor on the continued dip. AI is not seen as a villain, but is not seen as the hero either, at least not yet. Here are some interesting trends in responses for the past 3 years:

The conclusion is that we didn’t become more pessimistic, but the causes for the industry’s concerns have become more intense. And through the in-depth interviews, Open Eye was able to pinpoint the fact that people feel somehow powerless to the winds of regulations and geopolitics.
I so enjoyed my time and learnings at CloudFest 2025, and look forward to what the event will hold in store for 2026.

Nebius and VAST Data Combine Breakthrough Tech for AI Innovation
Enterprises are seeking innovative solutions to make organizational learning curves flatter, and trusted partnerships with industry innovators will help speed adoption. One such partnership that caught my eye at GTC features two players that are integrating cutting-edge technologies to deliver a powerful solution to the market. Nebius, a global AI cloud provider, and VAST Data, a leader in high-performance data solutions, are delivering a truly transformative approach to AI infrastructure that is poised to deliver needed tools for enterprises worldwide. Daniel Bounds, CMO of Nebius, and Chris Morgan, VP of AI Solutions at VAST Data, recently shared insights with TechArena into how their collaboration is revolutionizing AI cloud infrastructure. Let’s unpack what we learned.
Nebius offers a full-stack approach to AI workloads, providing an integrated platform across distributed infrastructure. What truly sets Nebius apart is how it has constructed its software layer to ensure a robust and easy-to-use experience for customers. As Daniel emphasized, this “secret sauce” is what makes the difference. It’s not just about having oodles of GPUs, but making sure customers are able to fully leverage this valuable infrastructure through an intuitive, user-friendly experience.
This is where VAST Data comes in. Known for its high-performance data solutions, VAST’s technology is helping Nebius push the envelope even further. By integrating VAST’s technology into Nebius’ stack, the companies are enabling customers to access not only powerful GPUs, but also an optimized data environment that can handle the most demanding AI pipelines. VAST’s platform ensures that the data management of AI is handled efficiently, giving users the ability to scale their operations without compromising performance.
As AI becomes more mainstream in the enterprise, the shift from model training to model inference is a major milestone and reality to manage. Chris highlighted that this transition is where the real value of AI lies for many businesses. Enterprises are increasingly looking to incorporate AI into their day-to-day operations, not just for training models but for integrating them into known workflows to drive positive business outcomes.
When we look deeper at Nebius, we find a wide range of flexible services. Whether it’s their AI studio, which enables on-demand inference, or a full suite of self-service and managed services, Nebius provides customers with a tailored experience based on their specific needs. As the demand for AI continues to grow, so too does the need for infrastructure that can handle large-scale, complex workloads, and this is where VAST’s data platform really shines. Nebius is tapping VAST technology to address this challenge by providing a solution that’s not only powerful, but also scalable, adaptable, and user-friendly.
What’s the TechArena take? We’re excited to see Nebius differentiate itself with an AI-centric cloud service offering, and we’re delighted to see how they’re leveraging VAST for the enterprise. Most of all, we went into GTC seeking signs of enterprise adoption, and while we’re not yet overwhelmed by scores of customer adoption stories at scale, VAST proved by be a foot forward player ready to deliver value to scale inference across enterprise verticals and functions. We can’t wait for what comes next.
For those interested in exploring Nebius’ AI cloud solutions, their platform offers multiple entry points, including AI Studio and other partner ecosystems: nebius.com. To learn more about how VAST’s high-performance data solutions can accelerate AI workloads, visit vastdata.com.

AI Benchmarks Shift as MLPerf Highlights LLM Dominance
Last week, MLCommons dropped a benchmarking bombshell with the release of MLPerf Inference 5.0 — and the implications for the AI infrastructure world are massive. As one of the most trusted benchmarking efforts in machine learning, MLPerf continues to evolve at the pace of the industry it serves. And with this latest round of nearly 20,000 new results, a surge in large language model (LLM) submissions, and several new hardware entrants, the signal is clear: inference is having a moment.
Here’s the TechArena take on what matters most.
LLMs Take the Crown from ResNet-50
In what feels like a milestone moment, the ResNet-50 era is officially over — at least in terms of benchmark popularity. MLPerf Inference 5.0 marks the first time an LLM has overtaken ResNet-50 as the most frequently submitted workload. Specifically, LLAMA 2 70B now leads the pack, with 2.5x more submissions than it had a year ago. The benchmarking community – often conservative in adopting new workloads – is fully embracing the age of LLMs.
Why does this matter? Because benchmarks drive optimization, and optimization drives real-world performance. The more representative the benchmarks, the more aligned vendor innovation becomes with enterprise needs.
Introducing the Biggest LLM Benchmark Yet
MLPerf 5.0 introduced LLAMA 3.1 405B, the largest model ever benchmarked by the organization. And yes, it’s as heavy as it sounds — long context windows, massive parameter counts, and distributed inference across accelerators. The real challenge here isn’t just throughput; it’s achieving tight latency constraints while maintaining accuracy.
A few stats that stood out:
- Median input token length: ~9,500
- Time to first token (99th percentile): 6 seconds
- Time per output token: ~175ms (faster than human reading speed)
Translation: These benchmarks aren’t theoretical — they’re reflecting production use cases like RAG (retrieval-augmented generation), agentic AI, and high-performance LLM APIs.
It’s Not Just About LLMs
MLPerf 5.0 also brought new benchmarks for Graph Neural Networks (GNNs) and automotive workloads:
- The GNN benchmark features a relational graph attention network (RGAT) trained on a massive heterogeneous dataset with over 5 billion edges.
- The new automotive benchmark, based on point painting and the Waymo Open Dataset, blends LiDAR and image processing — key for 3D object detection in real-time, safety-critical applications.
Both benchmarks reflect a broader point: inference is everywhere, from cloud AI services to edge deployments in cars and industrial systems.
The Hardware Evolution: FP4, Virtualization, and Liquid Cooling
From AMD’s Instinct MI325X and NVIDIA’s GB200 to Broadcom’s push for virtualized GPUs and Solidigm’s liquid-cooled SSDs, MLPerf 5.0 submissions captured an accelerating hardware shift.
We’re seeing:
- Adoption of FP4 (4-bit floating point) for LLMs, pushing performance up to 3x while meeting tight accuracy requirements
- Virtualized inference platforms from Broadcom and others that aim to mirror what VMware did for CPUs in the early 2000s
- Liquid-cooled servers entering the mainstream, as GPUs and SSDs hit thermal thresholds that demand new data center designs
This round wasn’t just about faster silicon — it was about smarter system-level design.
The Industry Is All In
Submissions came from 23 organizations: AMD, ASUSTeK, Broadcom, CTuning, Cisco, CoreWeave, Dell, FlexAI, Fujitsu, GATEOverflow, Giga Computing, Google, HPE, Intel, Krai, Lambda, Lenovo, MangoBoost, NVIDIA, Oracle, Quanta Cloud Technology, Supermicro, and Sustainable Metal Cloud. The “open” division also gained traction, giving software-focused companies a chance to shine by showcasing algorithmic and architectural innovations outside strict benchmark constraints.
As for data center decision-makers, MLPerf continues to offer a valuable lens for understanding how platforms evolve over time. Submitters now see MLPerf as more than a race — it’s a way to validate software stacks, evaluate scaling strategies, and compare performance under realistic production constraints.
With plans underway to replace older models like GPT-J, expand low-latency LLM scenarios, and broaden the edge inference suite, MLPerf is already planning for version 5.1. And if the growth we saw this round continues, the next wave of results will reflect even more LLM momentum, cross-industry relevance, and workload diversity.
At TechArena, we’ll continue tracking this fast-moving space and bringing clarity to the deluge of data. Because when benchmarks are this influential, they don’t just reflect the market — they help shape it.
Want to explore the full MLPerf 5.0 dataset? Dig into the Tableau dashboards now via MLCommons.org.

AI Ops & Autonomous Networks: The Future of Telecom
In this Data Insights episode, Andrew De La Torre discusses how Oracle is leveraging AIOps to enable automation and optimize operations, transforming the future of telecom.

Edge AI Silicon Heats Up as MemryX Closes $44M Series B
MemryX, an Edge AI startup that’s shared its vision on TechArena, announced today that it’s secured $44 million in its latest Series B round. This investment underscores the market’s continued appetite in infusing capital into AI processing capabilities including those aimed directly at the edge.
Founded in 2019, MemryX specializes in developing hardware and software solutions for edge acceleration. Their technology integrates memory and processing units to achieve optimal efficiency and flexibility, utilizing a single standard connection between the host processor and MemryX chip to limit data bottlenecks. This low-latency solution has the potential to expand edge applications where data flow is mission-critical, addressing the increasing demand for efficient AI processing at the edge, where data is generated.
The recent funding round saw participation from new and existing investors, including notable firms such as HarbourVest Partners and M Ventures. This infusion of capital is expected to accelerate MemryX's efforts in scaling their technology and expanding their market presence.
As AI continues to permeate various industries, the need for efficient, localized processing becomes paramount. It’s a fantastic time to be in the silicon industry, and MemryX's innovative solutions position them to play a significant role in the future of AI acceleration. They are meeting evolving demands, giving customers more tools to deliver efficient processing. Bravo!

Dryad Adds Drones to Speed Up Wildfire Detection
At TechArena, we’re always watching for companies that apply cutting-edge technology to solve complex, high-stakes problems — and Dryad Networks continues to deliver. This week, the company unveiled a major step forward in early wildfire detection with the successful demonstration of its new wildfire monitoring drone prototype at the ProSion Fire Brigade in Eberswalde, Germany.
Dryad is already known for its solar-powered, LoRaWAN-based Silvanet sensor network — one of the world’s largest deployments of its kind — which detects wildfires in their earliest smoldering stages. But this latest advancement sets its wildfire intelligence platform to flight.
Sensors Meet Drones
The Silvaguard drone prototype is designed to autonomously investigate alerts triggered by Dryad’s underground sensor network. Once a sensor detects a potential ignition, the drone can quickly fly to the location, equipped with thermal and optical cameras to visually confirm the fire. This not only helps reduce false alarms but gives emergency responders real-time situational awareness of an emerging threat.
Dryad’s approach has always been about interoperability and resilience. The company’s sensor mesh network, leveraging LoRaWAN for low-power, long-range communication, enables ultra-early wildfire detection — often before there’s visible smoke. Now, by integrating aerial surveillance into the platform, Dryad has created a layered response system that can reduce emergency response times and improve firefighting efficiency.
Smart Forests, Smarter Infrastructure
This is another example of distributed intelligence making a real-world impact. It’s a compelling use case for edge computing, IoT, and drone autonomy, delivering tangible benefits in sustainability, resource protection, and public safety. As climate change continues to amplify the frequency and intensity of wildfires globally, innovations like Dryad’s are essential infrastructure.
Dryad says the drone prototype is just the beginning. The company is now working to expand the integration between its sensor network, drones, and AI-based alerting platform to create a fully autonomous wildfire detection and verification system. If successful, this could become a blueprint for wildfire-prone regions around the globe.
So, what’s the TechArena Take? As wildfire seasons grow longer and more dangerous, this type of innovation doesn’t just matter — it could be the difference between containment and catastrophe.
See our earlier coverage of Dryad here.

AI Dev Tools, Agentic Trends & Cloudflare’s Evolving Stack
At GTC 2025, Cloudflare discusses empowering developers, managing agentic AI workflows, and simplifying application management as AI infrastructure rapidly evolves.

Unpacking The AI Data Factory – A Storage Perspective
Last week’s GTC event featured so many updates in the world of computing, and we’ll be unpacking layers over the next few weeks on TechArena. One story that caught my eye was NVIDIA’s view of the AI Factory, and specifically calling out the key vendors who were innovating for AI-centric infrastructure delivery. Here, you can see a who’s who of innovators across AI-serving layer, AI-resource orchestrator layer, and AI-semiconductor layer. What is fascinating about this grouping of companies is how many disruptors are present and how this reflects the change in architecture foundations for an AI-centric world.
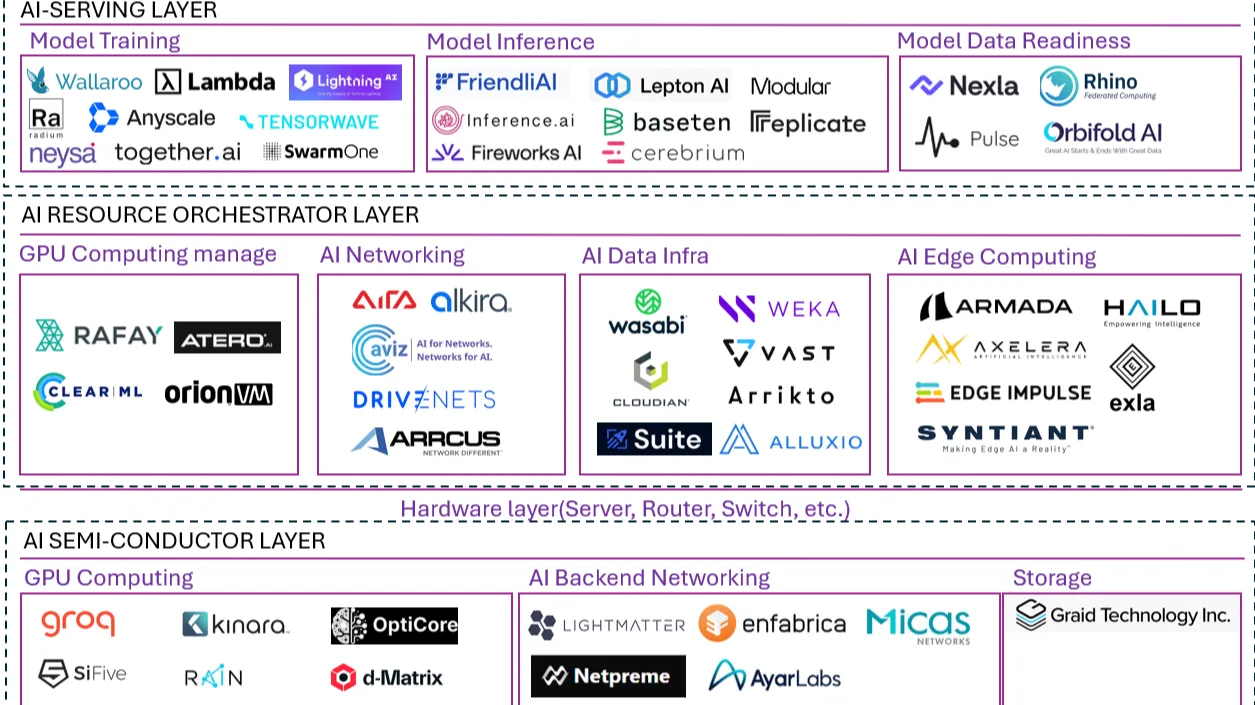
In today’s piece, I want to focus on storage, as data movement across a distributed landscape is so critical to the entire AI pipeline – and getting even more important, given the sustained access to data required by agentic computing. Last week at GTC, we featured a major collaboration announcement from VAST Data, showcasing a deep engagement with NVIDIA to deliver enterprise inference capabilities using VAST’s proven data platform. NVIDIA and VAST have a long history dating back to work within the HPC arena, and it shows in this announcement, as VAST is providing a core technology path that NVIDIA needs – simplified, broad adoption of generative AI workloads. While this element of their broader collaboration is just rolling out, expect to hear more about enterprise utilization of these solutions in the months ahead.
We also took a deeper look at Weka’s announcement of a new NAND-based memory grid architecture to drive “across-the-network” performance for fast response of scalable data. Weka’s solution is built upon access of distributed data across cloud and at scale, so this advancement carries the credibility of integrating into a solution that assumes a distributed architecture. It was cool to see Weka realizing that network data rates and SSD latencies have fundamentally shifted to the point that long-held truths about local vs. networked data have become legacy.
If we dig a bit deeper into NVIDIA’s map, we see that Graid has been called out for storage hardware innovation. They sit notably alone in the storage box, which is why I wanted to dig in further, as they’re the only solo vendor across the landscape. NVIDIA discussed GPU-accelerated storage extensively at the conference, and I soon learned why Graid was getting this opportunity for the spotlight. Graid has delivered exactly to NVIDIA’s vision with its SupremeRAID solution, providing software-defined storage control on a GPU for maximum SSD performance. This allows RAID solutions to be utilized within AI clusters without the I/O bottlenecking found in traditional RAID architectures. Again, we’re seeing traditional architectural models turned on their sides to deliver new capability, and once again a disruptor is taking center stage with an innovative solution for the market.
But let’s go under the covers one step further. We’ve written a lot about liquid cooling on TechArena, and of course we’re seeing a massive migration to liquid cooling on accelerated hardware. When we think of this, we typically think about GPUs. But what about the other components inside a server? There was an announcement at GTC at the heart of storage that shows more broadly how accelerated computing is putting new demands on innovation across the box, and this came from Solidigm. The purple monster of SSD capacity delivered a breakthrough liquid-cooled enterprise SSD, specifically for AI deployments. The innovation eliminates the use of a fan for cooling an in-server SSD, moving to a cold plate cooling alternative that allows for cooling both sides of the SSD and allowing for hot swapping of the device. The first design based on this new part will be delivered via ruler form factor, and I expect we’ll start seeing it integrated into many of the disruptors on the list, showcasing both the importance of all SSD configurations in AI clusters and the rate of innovation in every element of AI configurations.
Like what you’re seeing? Check out more GTC unpacking posts in the days ahead.

Deloitte and VAST on the Next Stage of Enterprise AI
Deloitte and VAST Data share how secure data pipelines and system-level integration are supporting the shift to scalable, agentic AI across enterprise environments.

With Augmented Memory Grid, Weka Challenges Old Guard Thinking
A wonderful thing about the GTC conference is that there are pockets of news to unpack across the data center computing landscape, and one such story is WEKA’s announcement of a new Augmented Memory Grid within their WEKA Data Platform software integration with NVIDIA accelerated computing. It’s these kinds of stories that get our attention at TechArena, as they demonstrate shifts in the computing landscape that are often overlooked.
To understand just what WEKA has delivered, we have to look at a broader trend going on within computer interface advancement, those industry standards that connect components in and across systems. When we look at the past five years in Ethernet speeds, we’re seeing data rates climb from 25 Gb to 40, 100, 200, 400 Gb and beyond. In a similar timeframe, PCIe has moved from 64 GB/s to a forecasted 256 GB/s with 7.0 (with influence on future generations of NVMe transfer rates as well), and the upcoming introduction of MR-DIMMs will introduce increased bandwidth and transfer rates – but all of these changes have not advanced as quickly as Ethernet.
What does this represent? We’re advancing data movement in the platform, but the thought that keeping data local vs transferring data across the network may be antiquated, at least at this moment of our architectural paradigm.
WEKA – an expert in managing distributed data – has seized on this opportunity with Persistent Memory Grid support. What the technology does is tap standard NVMe drives for fast data capacity delivered at surprisingly low latency, forming a far memory tier for accelerated inference clusters. This augmented memory grid, being based on NVMe, offers persistence. Don’t get distracted by that persistent memory name. This is not 3DXPoint or Optane, just standard NAND-based storage operating at fantastic speeds.
WEKA claims a 3x capacity improvement to existing designs for large model support, and this is important when you consider the longer context windows needed to support functions like agentic computing and its inherent expanded autonomous decision-making. Some performance claims offered to support the technology included improvement of first token delivery by 41x when processing 105,000 tokens and a savings on the cost of token throughput by 24%. Those claims are significant when considering the scale of infrastructure deployment and are just another example of great engineering delivering pragmatic value to customers.

Building a Full-Stack AI Cloud with Nebius and VAST
This video explores how Nebius and VAST Data are partnering to power enterprise AI with full-stack cloud infrastructure—spanning compute, storage, and data services for training and inference at scale.

Solidigm, Dell Discuss AI Data Challenges at GTC
During GTC, Solidigm’s Scott Shadley and Dell’s Rob Hunsaker, director of engineering technologists, discussed how Dell is tackling the challenges of AI data infrastructure with cutting-edge solutions.

Ampere Receives A $6.5 Billion Exit
Earlier this week, Ampere announced that it had been acquired by Softbank, the Tokyo-based conglomerate with deep investments across semiconductors, AI and robotics, telco and more. This ends the startup’s independent quest to drive Arm-based silicon innovation deep into the data center and edge and opens a new chapter for the 1,400-member team as part of a much larger and more powerful entity. With the acquisition, Oracle and Carlyle, Ampere’s lead investors, have sold their stakes in the company.
At its launch, Ampere delivered a shot across the bow of x86 dominance in the data center landscape introducing large core count processing for data center workloads based on the Arm core. Their focus was on addressing the balance of performance and efficiency at scale, modernizing an architecture that was designed specifically for the cloud. This has played out in the market with mixed results, with highs of Ampere gaining traction within OCI (note Oracle investment) as a wedge against x86 alternatives. More recently, Ampere had seen sales slump from over $46 million in 2023 to just over $14 million in revenue in 2024 as data center operators attention shifted to accelerated computing to fuel AI, and a value proposition of large quantities of efficient cores became less urgent.
$6.5 Billion – That's a Lot of Cores
When looking at this deal, we need to ask why Softbank, a very savvy investor group, spent $6.5 billion for a company generating $14.6 million in revenue. The answer likely lies in a few strategic broader trends in the market, that trace from the world's governments to this week’s GTC conference, and to the limitations of savvy microprocessor designers vs. industry demand.
At GTC this week, Jensen Huang made clear that the unrelenting demand for computing is growing at an exponential rate. Hitting a nail in the threat of new levels of efficiency of LLMs like Deep Seek, Jenson clarified that these reasoning models require a stunning 100X compute power vs previous forecasts to deliver to their market opportunity. This compute demand will, of course, in part be satisfied by NVIDIA GPUs like the upcoming Blackwell Ultra and Vera Rubin models. But customers are getting increasingly nervous about continued “one basket” investment with team green. We’ve commented on this recently in our coverage of late on Cerebras, the high-powered AI ASIC startup that is delivering some breakthrough performance, and we expect to see a groundswell of growth across accelerator alternatives as large players start chipping away at that 100X capacity demand.
What customers may have this on their radars? Well, a first stop may be looking at the recent announcements of governments stepping aggressively into the AI game, most notably with the Stargate (U.S. government initiative announced earlier this year). We’d also look at something Softbank announced themselves, Cristal Intelligence, a bold move for AI adoption in the Japanese market. Both deals featured OpenAI collaborations. Both also had another highly featured vendor...Arm. Arm and Softbank have a long history together with Softbank maintaining 90% control of the company’s equity. Arm was also notable in the Stargate announcement, and many took their presence as a reflection of their core integration into Grace Blackwell platforms, bringing an efficient head node core in balance with Blackwell GPUs. The company was more prominently featured within the Cristal Intelligence announcement being called out as a strategic innovator for the new “SB Open AI Japan” joint venture that is seeking to unleash agentic computing to automate over 100 million workflows for Softbank group companies.
And agentic computing takes us to our third topic – a dramatic shortage of talented semiconductor designers within the industry to serve this 100X ramp. In fact, this was a key theme at Synopsys’ Executive Forum this week, where the firm rolled out their strategy for agentic semiconductor engineering assistance to help the industry fill this gap. We’ll be delivering more on this story in the coming days, but needless to say, with demand to shrink component designs from historic windows of 7 years down to one year from concept to deployment, the semiconductor arena requires an infusion of engineering cycles as the entire industry innovates the semiconductor design workflow.
With Ampere, Softbank gains just that with a 1,100 member CPU design team to match their architecture design team within Arm, filling what likely is a strategic talent gap for path to market. This marries perfectly with the large customer collaborations rolling out at rapid pace and potentially blends with the much rumored direct from Arm product portfolio expected by the industry later this year.
So what’s the TechArena take?
We’ve been covering Ampere since the foundation of our platform and are excited to see the next chapter for the company and its leadership. I, for one, am intrigued by how the two firms will work under one Softbank umbrella. And, most of all, I’m led into conjecture space where I see the mounting pressure for more competition in the accelerator arena. Reading through the ambitions of the Cristal Intelligence initiative, I see Arm being positioned for much more than efficient core delivery for this landscape. Arm’s CEO, Rene Haas, has a history in GPU product oversight in the seven-year tenure at NVIDIA preceding his move to take the helm at Arm. He’s tapped key talent from NVIDIA to help him lead that charge. Now we’ve got Renee James, a very savvy semiconductor executive with decades of experience in understanding both microprocessor delivery and full stack optimization at Intel dating back to her time as Andy Grove’s protege, growing what seems to be tighter alignment with team Haas.
Does this deliver an opportunity for tech innovation that we have yet to imagine? We can’t wait to find out what comes next.

AI, Edge, and Power: Key Takeaways from MWC Panel Discussion
At Mobile World Congress 2025 in Barcelona, the discussion around edge computing, data centers, and AI took center stage, and I had the honor of moderating an engaging panel featuring leaders from Ansys, Ampere, and Rebellions.
Ansys CTO Jayraj Nair, Ampere Chief Product Officer Jeff Wittich, and Rebellions CEO Sunghyun Park shared valuable insights on the evolving landscape of AI, hardware innovation, and the challenges of modern computing.
According to Sunghyun, 2025 is shaping up to be a pivotal year for the widespread adoption of generative AI, especially in the enterprise sector. As AI continues to evolve, the focus is shifting from AI R&D to the practical implementation of AI in business operations, with a strong emphasis on inference.
Meanwhile, Ampere has been focused on solving the power challenges associated with AI’s increasing presence in cloud and data centers, as well as at the edge and endpoint devices. As AI models expand, so too does the need for more efficient hardware that can deliver high performance while managing power and space constraints. Jeff pointed out that these challenges aren’t limited to data centers, but are also now pervasive in telco environments, where AI models are also deployed.
With advances in simulation engineering, companies like Ansys are helping accelerate AI adoption. Their work enables faster, more efficient design of critical factors, such as signal integrity, power integrity, and thermal performance across multi-scale models. As chiplet architectures and multilayer designs become more common, simulation tools will help engineers address challenges, such as voltage drops and thermal stress, which can negatively impact performance. This multi-physics simulation engineering ensures that silicon can handle the demands of AI-driven systems.
As the conversation continued, the panelists highlighted a major turning point for AI adoption in 2025: its seamless integration into all enterprise applications. Rather than users actively seeking out AI tools, AI will become an invisible force running in the background, embedded in everyday software. As AI-powered systems work behind the scenes to enhance productivity, it will increasingly rely on autonomous, machine-to-machine interactions, reducing human involvement. This shift will fuel tremendous demand for AI hardware and software across industries.
Jeff emphasized the need for collaboration and open-source technologies. He pointed out that without strong partnerships, progress in AI and silicon would be limited. The discussion highlighted how AI ecosystems require integrated efforts to keep pace with technological advancements.
Jayraj stressed the importance of academic partnerships in shaping the next generation of engineers. As AI hardware and software become more complex, specialized curriculum is essential for preparing future tech leaders.
The conversation then shifted to the global stage, particularly the geopolitical implications of AI investments. The EU’s $200 billion InvestAI initiative raised important questions about the risks and opportunities of such investments. While Sunghyun acknowledged uncertainties in global dynamics, he emphasized the importance of collaborating to secure second-source technologies and ensure resilience in the supply chain.
Looking ahead, the panel agreed that power efficiency and sustainability would remain significant challenges. As AI models grow, the demand for energy will rise, but innovations in low-power CPUs and efficient hardware will help address these issues. Despite the hurdles, the panelists were optimistic about the future, envisioning a world where AI is seamlessly integrated into every device and workload, transforming industries worldwide.
So, what’s the TechArena take? The future of AI is unfolding, and the path ahead is filled with opportunity.
For a deeper dive into the topics we discussed, watch the video here.

VAST & NVIDIA on the Insight Engine-DGX Collaboration
At GTC 2025, VAST’s John Mao and NVIDIA’s Tony Paikeday discuss their recent announcement and how AI infrastructure is evolving to meet enterprise demand, from fine-tuning to large-scale inferencing.

The Next Frontier of AI: Key Insights from AMD’s Salil Raje
While at Mobile World Congress (MWC) in Barcelona, I had the delightful opportunity to chat with Salil Raje, senior vice president and general manager of Adaptive and Embedded Group within AMD.
During our fireside chat, Salil shared some exciting insights about the future of AI at the edge—one of the most transformative trends in technology today.
Here are five key takeaways from Salil’s conversation at MWC.
1. AI at the Edge: A Paradigm Shift
While AI’s rise in the cloud captured attention in 2024, Salil anticipates that things will shape up differently in 2025, with the real transformation lying at the edge.
“AI will be everywhere—from satellites to devices,” he said.
As AI moves closer to users and devices, it enables real-time data processing, reducing latency and improving decision-making. This shift is crucial for industries like healthcare and automotive, where speed and efficiency are vital.
2. The Power of Federated Learning
Federated learning is a game-changing technology that powers edge AI. It allows devices to process data locally and send only necessary updates to the cloud, where the model weights are coalesced and then sent back to the edge. This minimizes data transfer and improves decision-making speed.
3. Revolutionizing the Automotive Industry
In the automotive sector, AI at the edge is transforming not just autonomous driving, but also safety and driver experience. Salil mentioned AMD’s partnership with Subaru, which centers on reducing fatalities to zero by 2030. Through AI, Subaru’s safety systems are becoming more intelligent, processing real-time data for faster decision-making. Additionally, AI companions are enhancing the driving experience, personalizing interactions and improving safety.
4. AI in Healthcare: Beyond Diagnosis
AI’s impact on healthcare is already irrefutable, but Salil highlighted how AI and robotics are taking things a step further. AI-driven exoskeletons, for example, are helping individuals who have lost a limb regain mobility and functionality, offering a new level of independence and improving their quality of life. AMD’s partnership with Hiroshima University utilizes AI to improve rates of early detection of cancer, while their partnership with Clarius aims to enhance diagnostics through advanced portable ultrasound imaging techniques. These innovations show how AI at the edge is improving not just diagnostics, but patient care in real time.
5. The Silicon Behind the Revolution
To support AI at the edge, powerful, specialized hardware is essential. Unlike cloud AI, which relies on massive CPUs and GPUs, edge devices require more compact and efficient solutions. Salil highlighted AMD’s innovative hardware, such as the Versal AI Gen 2, which integrates CPUs, GPUs, and FPGAs into a single platform designed for edge workloads. This hardware helps industries efficiently process complex data while meeting size, power, and cost requirements.
What’s Next for AI at the Edge?
The potential for AI at the edge is vast, but there are still hurdles to overcome. For example, Salil pointed out the need for faster adoption within telecom, a sector that has been slower to deploy AI.
So, what’s the TechArena take? In the coming years, more industries will embrace AI at the edge, enabling smarter systems and better, faster decision-making. As Salil put it, we’re on the brink of an “AI moment” that will reshape the way we interact with technology.

Synopsys Accelerates Chip Design with NVIDIA Grace Blackwell, AI
At GTC today, Synopsys delivered a unique insight into the reach of Grace Blackwell-powered innovation with the release a suite of electronic design automation (EDA) tools including PrimeSim circuit simulation, Proteus computational lithography simulation, and Synopsys AI CoPilot. PrimeSim taps NVIDIA CUDA-X libraries to help accelerate circuit design by up to 30x vs historic solutions. Proteus advancement is not that far behind, achieving up to 20x performance improvement within the lithography arena. That collective performance advancement is simply stunning, especially when considering the incredible pressure on the semiconductor industry to innovate and deliver bespoke solutions that are optimized for point workload requirements across the AI continuum and across cloud-to-edge environments.
This announcement is reflective of the increased complexity of semiconductor design and delivery in the AI era, something we covered extensively on the TechArena platform at Chiplet Summit earlier this year, as monolithic designs shift to more complex packaging technologies enabling modular chiplets, often delivered across different process technologies.
We'll be spending time with Synopsys later today and tomorrow to learn more about this and other advancements from the tech leader as they continue advancing foundational technology to fuel the next generation of semiconductor innovation.

How PEAK:AIO is Powering the Future of AI and GPU Compute
Solidigm’s Jeniece Wnorowski and I recently had the pleasure of chatting with Mark Klarzynski, founder of PEAK:AIO and a key player in the world of AI-driven storage solutions. With AI’s ever-increasing demands for faster data processing, the need for innovative storage solutions is paramount. Mark shared valuable insights into how PEAK:AIO is leading the way in high-performance storage for AI and GPU compute, and its role in transforming industries from conservation to healthcare.
AI’s Growing Data Needs: A Storage Challenge
As AI technology becomes more advanced, it generates and relies on increasingly vast amounts of data, which presents a significant challenge for traditional storage solutions – underscoring the need for faster, more efficient storage options. Mark explained that many industries, from wildlife conservation to healthcare, are increasingly depending on AI to process massive datasets in real time. However, many legacy storage systems simply can't keep up with the processing demands of modern AI workloads or fit within the tight power and space restrictions.
This is where PEAK:AIO is stepping in to revolutionize and refine AI storage. Unlike traditional solutions, PEAK:AIO is specifically designed to optimize AI performance by reducing space, power, and complexity, which ensures rapid data processing without bottlenecks.
PEAK AIO’s Role in AI: Real-World Impact
Mark offered some intriguing examples of how PEAK:AIO is already making a significant impact. In the healthcare sector, for example, AI is now providing healthcare professionals with medical image analysis – such as MRIs and CT scans – at previously unimagined speeds. The increased rates at which massive image files are processed enable doctors and medical technicians to more rapidly develop insightful diagnoses.
Mark also outlined possible scenarios where AI, powered by PEAK:AIO’s fast and reliable storage, has the potential to save lives with its rapid processing capabilities. Rather than waiting six weeks for a doctor to evaluate imaging results, AI can deliver results before patients even leave the clinic. The ability to identify and diagnose health issues in real time, which might otherwise have gone undetected due to delays in data processing, will have significant positive impact on health outcomes.
AI in Conservation: Protecting Wildlife with Peak AIO
Beyond healthcare, Mark also highlighted how PEAK:AIO is contributing to wildlife conservation efforts. One project involves the Zoological Society of London (ZSL) and their use of AI-powered camera traps to monitor endangered species in remote locations. These camera traps generate massive amounts of image data that need to be processed and analyzed quickly to track animal populations and combat poaching.
Mark explained that PEAK:AIO’s high-performance storage technology allows conservationists to analyze this data in real time, enabling them to make faster decisions that critically impact efforts to protect populations of endangered species. By offering scalable, reliable storage that can handle large volumes of data, PEAK:AIO plays a crucial role in ensuring that AI can provide accurate and timely insights that directly impact conservation efforts.
Scalability: Preparing for the Future of AI
One of the key factors that Mark emphasized throughout the conversation was the scalability of PEAK:AIO’s storage solutions. As AI continues its inexorable growth, the amount of data generated will only increase. Unlike traditional storage systems that are often ill-equipped to sustain such growth, PEAK:AIO’s technology is designed to scale seamlessly. Whether it’s in healthcare, conservation, or any other industry, PEAK:AIO ensures that data can be processed, stored, and accessed without the bottlenecks that slow down traditional systems.
In fact, Mark shared that PEAK:AIO is already looking ahead to the next big advancements in AI storage. As AI technologies become increasingly sophisticated, the demand for storage that can handle larger, more complex datasets will continue to rise. PEAK:AIO is uniquely positioned to meet these future demands, providing high-performance solutions that keep up with AI’s rapid evolution.
The Power of Efficient Storage for AI’s Growth
So, what’s the TechArena take? PEAK:AIO’s innovative storage solutions are helping industries unlock the full potential of AI by providing fast, scalable, and efficient data storage. Whether in healthcare, conservation, or beyond, the work being done by PEAK:AIO is making AI faster, more reliable, and capable of driving meaningful change in the world. In the heady world of hype on AI’s future potential, our conversation was a refreshing reminder that AI capability is being deployed for pragmatic benefit today. Check out the interview to learn more.

The Truth About AI Inferencing: Understanding Generative AI and Its Infrastructure Demands
Generative AI has rapidly become the driving force behind over 80% of enterprise AI deployments, signaling a shift from traditional predictive models to systems capable of creating entirely new content. In this webinar, Shimon Ben David, CTO of Weka, and Ace Stryker, AI & Data Center Lead at Solidigm, explore the evolution of AI inferencing, the critical infrastructure challenges that come with scaling generative models, and real-world case studies showcasing how enterprises manage inferencing at exabyte levels. Learn how advanced storage solutions, optimized resource utilization, and seamless GPU integration can reduce model load times dramatically and ensure the efficiency needed to support the next wave of AI innovation.

GTC 2025: AI Factories Take Center Stage
We are heading to GTC this week, and I can't help but think of Aaron Burr singing about the room where it happened. This is THE AI conference of the year, where a certain leather-clad CEO will provide his outlook on the next stage of AI infrastructure delivery. And while there will be heady talk of the next mega-factory buildout pushing LLM capability further, I am seeking information on a few topics to set the stage on the strength of broad AI adoption.
- The DeepSeek impact: We have featured DeepSeek extensively on TechArena, and I'm intrigued by how NVIDIA will embrace this and other Chinese developed LLMs, all delivering new capability and efficiency. Some have claimed that these models threaten NVIDIA demand. I, for one, believe more efficient technology begets broader market adoption and am hoping to hear a lot about a broader array of model optimization at the show.
- Enterprise uptick: We have been discussing AI inference at scale lately – from the pragmatic approaches offered by Intel to the fine-tuned leadership performance from Cerebras to the energy efficient AI acceleration at the edge from Untethered AI. What I'm excited to see at GTC is actual enterprise adoption examples across industries, with meaty, scalable, adoption of LLM infused applications. 2025 is forecasted to be the year of hockey-stick growth for enterprise application ignition, and I'm keen to see what use cases and industries are leading the charge. While NVIDIA will likely showcase these stories across the event, we will be digging deep into the vendor showcase to seek out broader examples of customers taking the gen AI plunge.
- Agentic computing: At MWC earlier this month, the talk suggested everyone got a memo upon entering the Fira stating that they must mention AI agents at least three times a day. Agentic AI is the new hot topic as researchers push the application of LLMs further, and automated sequencing of work takes hold. I am at GTC to dig into the various approaches to Agentic computing and how vendors are building guardrails to agent actions for risk-averse enterprises who may not be totally ready to hand over full control to an army of agents.
We will be reporting on these topics and more in the coming days from San Jose! Watch this space for coverage, and follow the TechArena feed to ensure you don't miss any of the story unfold.

ASIL Decomposition and Functional Safety
In my previous blog, titled A Deeper Dive on Functional Safety (FuSa), I took a closer look at the two key elements of functional safety: systematic fault coverage and random fault coverage. In short, systematic fault coverage ensures that the device in the system is designed, verified, and tested at a level of rigor and robustness that is consistent with the target Automotive Safety Integrity Level (ASIL), to ensure there are no faults that are systematic in nature. (For those not familiar with the terminology being used at this point, it is advised to review the earlier blogs on this topic.)
For those of you old enough to remember the Intel “Pentium Processor Divide Error,” this is a good example of an error that was systematic in nature - i.e. the same set of numbers when divided by one another consistently produced an erroneous result across every Pentium Processor. A key foundation to achieving a given ASIL is that there are no systematic faults that have been designed into the device. If that is not the case, one can imagine a situation where an instruction is issued to a processor to have a car turn right, but instead, it turns left and will do so erroneously every time that instruction is issued. If systematic errors are not wrung out during the design, verification, and testing of the device, it is almost certain that the system will fail or, at a minimum, provide an undesired response.
Random hardware failures, on the other hand, occur unpredictably over the lifetime of a product. However, they tend to be probabilistic in nature. These errors are the basis for the term ‘probabilistic metric for random hardware failures’ (PMHF), and occur for various reasons, such as neutron flux, power supply droop, transients, etc., which are independent of design and quality rigor. The other faults that comprise the suite of random hardware faults include single point fault metric (SPFM) and latent point fault metric (LFM). As ASILs increase, the acceptable levels of “escaped faults” become more stringent for the system.
To remind the reader, functional safety is not the absence of faults - it is the ability to detect or flag a fault when it occurs, so this information can be passed on to the system, and the appropriate corrective action can be taken. This action can range from advising the driver to take the car into the shop for maintenance in a few months, to crippling the car and driving it off to the side of the road. These decisions happen at the system level, but the fault needs to be detected and flagged at the chip level and communicated in order for the system to be able to make those decisions.
While semiconductors employed in critical automotive safety applications support ASIL D systematic fault coverage, the majority of the complex semiconductors employed in a vehicle support only ASIL B random fault coverage, which seems somewhat counterintuitive. That said, the entire system, which comprises all the multiple devices in the safety path, typically needs to achieve ASIL D at the system level. So, the question is: how is ASIL D random fault coverage at the system level achieved when each device itself supports only ASIL B random fault coverage? The answer is through a technique called decomposition. Before going into some of the details of decomposition, here is another analogy that can be very helpful.
If you have ever glanced into the cockpit of a major airliner aircraft, it is riddled with an incredible number of gauges, dials, knobs, and switches. One begins to wonder exactly how a pilot would be able to figure out which gauges to read and which knobs and switches to turn. Upon closer inspection—should you be allowed inside the cockpit of a commercial airplane—you would find that there are actually three gauges that are measuring the exact same thing, as well as three switches and knobs that control the same aspect of the plane. This is done deliberately, and is referred to as triple mode redundancy (TMR).
The motivation for this approach is that, under normal operating conditions, all three gauges will read identically the same. However, in the case of a random fault, the probability is that the random fault will only occur with one of the gauges, not all three. So, if two of the three gauges are reading the same value and one gauge isn’t, it probably means that the gauge showing the different result is wrong. Employing TMR, the probabilities of a random fault not being detected can become even more infinitesimally smaller than those defined in ASIL D random fault coverage.
The price tag associated with solving the problem through TMR also leads to a significant increase in the cost of each protected system. This may not be a problem for a multi-million-dollar aircraft, but it quickly becomes impractical in an eighty-thousand-dollar passenger car. Now, taking a step back for a moment and returning to the original point with regard to systematic fault coverage, which requires real rigor and a foundation for FuSa, imagine a platform with three Pentium Processors, with the divide error now connected in TMR. When they check each other’s results, even though the answers to the division problem are incorrect, they all arrive at the exact same conclusion, which is obviously a problem. This is why I made the point that robust, i.e. ASIL D systematic fault coverage is a foundational requirement for FuSa.
So, for reasons previously explained, most semiconductors don’t simply employ TMR on-chip to achieve ASIL D random fault coverage, because the costs would be exorbitant and prohibitive. To achieve ASIL B random fault coverage alone requires subsystems with “lock-step” processors on board, where, rather than three processors, two processors check each other’s results and use that information for safety-critical regions of the device. Typically, these are the processors that either drive actuators (motors, brakes, etc.) or pass messages on the CAN bus - a bus that ultimately may affect the actions of an actuator. I’ll stop here, because this topic too can get fairly deep fairly quickly.
Through a technique called decomposition, multiple devices in the system provide alternative paths to ensure checks and balances are maintained at the system level, similar to the TMR aircraft example. Decomposition is not a topic worthy of blogging about in depth, as it becomes more complex even faster than the way ASIL B random fault coverage is achieved at a device level. However, the curious reader can certainly use ChatGPT to dig in deeper if interested. Suffice to say, decomposition, in effect, mirrors that of TMR in the way the results from one device aren’t simply taken at face value.
Perhaps the key takeaway from this three-part series on FuSa is that designing devices and systems for automotive applications requires significant thought and foresight. One of the key forcing functions to ensure that best-practices are employed and ISO26262-compliant guidelines are followed with rigor is that, in the case of a life-threatening accident, if it becomes clear that these guidelines and rigor were not followed, the automotive OEM and Tier 1 (as appropriate) will assume the liabilities.
When it was proven that a well-known OEM with a “stuck accelerator” problem was caused by poor software coding practices, a settlement of $1.2 B was reached. And oh, yeah, we didn’t touch on the topic of FuSa as it applies to software. Maybe another blog?

Generative AI vs. Machine Learning: What's the Difference?
Some people say that we are in the age of AI. In fact, we seem to be smack in the middle of a bubble – AI is all anyone in tech can talk about! But what do people mean when they talk about AI? How can you be sure you’re building something that will solve real problems? One way is by understanding terms. Let’s start with the differences between Machine Learning (ML) and Generative AI (Gen AI).
Search Terms Indicate a Hype Bubble
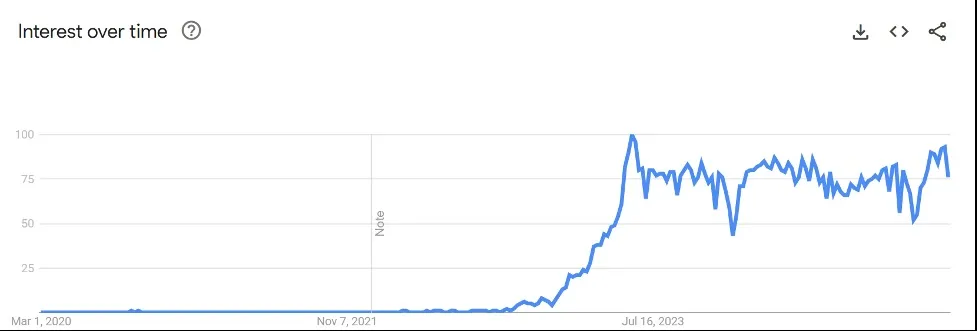
In many cases, marketing for AI is really marketing for Gen AI. Take a look at Google trends for the term “generative” AI for the past five years:
But when you look at Google trends for the term “machine learning,” you notice that it’s been a popular search for the same period:
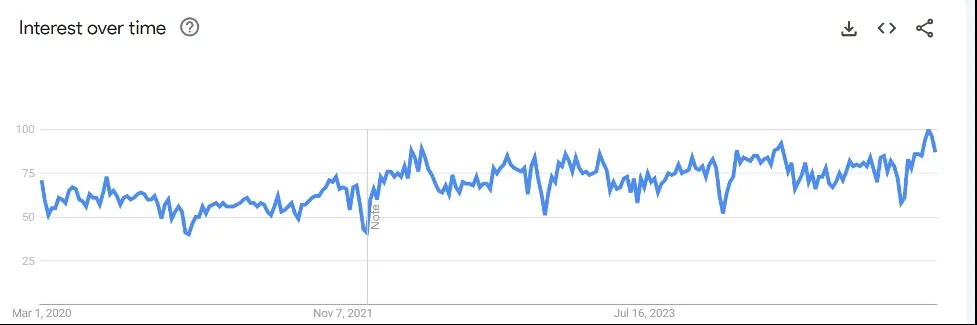
It’s apparent from Google search trends that interest is more consistent with ML than Gen AI. Why is that?
How is generative AI different than Machine Learning
Generative AI creates new content from existing data. Different models generate text, images, music, and more, based on the way they have been trained with advanced algorithms. It takes vast amounts of data to power the algorithms.
Machine learning is an entire subset of AI. According to IBM , ML is “a branch of AI focused on enabling computers and machines to imitate the way that humans learn, to perform tasks autonomously, and to improve their performance and accuracy through experience and exposure to more data.” ML is what fuels descriptive, predictive, and prescriptive AI applications.
Machine learning is an entire subset of AI. Algorithms are applied to large amounts of data so that the ML program can “perform tasks autonomously, and ... improve their performance and accuracy through experience and exposure to more data (via IBM). ML is what fuels descriptive, predictive, and prescriptive AI applications.
Machine Learning Categories Explained
There are three ways to perform ML. With supervised learning, the models are trained with labeled data sets. My colleague, Tony Foster, walked through training a model to recognize cats in our VMworld session last year.
With unsupervised learning, the models use unlabeled data sets. This is what helps you find data trends you may not know to look for.
Reinforcement learning trains models “through trial and error to take the best action by establishing a reward system”. This could be as simple as letting the model know when it made the right decision.
Most AI in the Enterprise is Powered by Machine Learning
Here’s a list of applications that depend on machine learning that you probably already use (via TechTarget):
- Chatbots use ML and natural language processing (NLP) to mimic conversation.
- Digital assistants, such as Siri and Alexa use ML to understand and respond to voice commands.
- Recommendation engines process your past purchases + current inventory + what other customers are buying to recommend what you should also buy.
- Dynamic pricing helps companies adjust the prices they charge based on market conditions. Controversially, it also seems like they have been marrying recommendation engines and dynamic pricing to charge different prices for individual consumers.
- Speech recognition can record calls, monitor customer calls with human agents, and provide language translation.
Generative AI Doesn’t Work Without Machine Learning
Gen AI relies on ML techniques to work. It often uses NLP and computer vision in its creation process. Other ML disciplines used by Gen AI include (via Blue Prism):
- Multimodal AI to interpret text, images, and videos.
- Large Language Models (LLMs) were designed to generate and understand human language text.
- Generative adversarial networks (GANs) are unsupervised learning techniques that pit two neural networks against each other during training.
- Transformers use math to identify the context and relationships between data.
- Diffusion generates new data.
Know AI Basics to Navigate the Hype
Generative AI is built to create new content. Machine Learning analyzes lots and lots of data to make sense of it, and there are many models to accomplish this. Knowing the difference between the two will help you zero in on what type of AI can help you solve business problems.
Here’s the question to ask yourself before a vendor calls you to pitch an “AI” solution: what is your business use case for AI? Will it require Gen AI? Or will an ML algorithm be enough?

The Evolution of Ransomware, Pt. 2
Welcome to the second half of this series on the growing threat of triple extortion ransomware. In the first part of this series, we discussed Aaron, a business owner who became the victim of a ransomware attack that not only rendered his data inaccessible, but also threatened to expose sensitive personal information that would destroy his reputation. This attack highlights the evolution of ransomware, which is no longer just about encrypting a victim’s data – it’s about exploiting that stolen data in increasingly personal and nefarious ways to maximize damage.
As ransomware has evolved, attackers have adopted more sophisticated methods, such as double and triple extortion, to target both the confidentiality and reputation of businesses and individuals. These advanced techniques render traditional defenses, such as secure backups, insufficient against this growing and dangerous threat.
The Goalposts Have Moved: Triple Extortion Ransomware
Old-fashioned ransomware attacks focused on encrypting a victim's data, rendering it inaccessible. The attackers would then demand a ransom payment in exchange for the decryption key, effectively holding the availability of the data hostage. This type of attack disrupted operations by targeting the availability of the data to its rightful owner.
Modern ransomware has evolved beyond simply encrypting data in two ways. Now, attackers not only encrypt the data, but also steal it and threaten to release it publicly if the victim does not pay the ransom. Typically, they try to sell it as well. This "double extortion" tactic adds another layer of pressure for the victim to pay the ransom, targeting not only the availability of the data, but also its confidentiality. Even if a victim has protected backups and can restore their data without paying, they still face the risk that attackers will expose sensitive information, potentially leading to reputational damage, financial losses, identity theft, and legal repercussions.
Triple extortion ransomware, the latest evolution in ransomware, amplifies the already devastating effects of double extortion (data encryption and theft) with a third, often highly personalized, attack. It represents a significant and growing trend, especially among more sophisticated threat actors. Think of it happening to you: First, your computer is locked down by encryption – you cannot access any of your files. That is the initial blow. Second, the attackers reveal they have stolen sensitive personal data, such as tax returns, banking files, medical records, and private messages, and threaten to expose it publicly or sell it unless you pay. This is the second extortion, preying on your confidentiality. Then comes the third attack, designed to maximize coercive pressure, so they get paid immediately: they might hijack your social media and email accounts, locking you out or posting fabricated, reputation-destroying content to your contacts. Mixing stolen family photos with materials involving the sexual exploitation of minors, for example, effectively coerces payment, even though it is a falsified accusation. If you go to the police, they will release this material. The sense of helplessness can compel victims to pay even more quickly. This triple threat – loss of access, threat of exposure, targeted disruption of your online life, and police deterrence – makes triple extortion a particularly effective and profitable form of ransomware.
No Longer Safe with Backups
Traditional ransomware solely targeted the availability of data. The threat was primarily operational disruption. Modern ransomware, with double and triple extortion, targets confidentiality as well. The threat now includes reputational damage, financial losses from data breaches, and potential legal repercussions. This is a fundamental shift, because even with secure data backups, victims are no longer safe from ransomware.
The progression from single to double to triple extortion reveals a calculated escalation in attackers' methods, driven by a desire to maximize profit. Many people view the pursuit of financial gain as a healthy business practice, but ransomware attackers go beyond mere profit-seeking by using increasingly mean tactics to achieve this goal. The example of mixing stolen family photos with false accusations of child predation, while deeply disturbing, illustrates the lengths to which they will go to coerce quick payment. The emotional and psychological impact of triple extortion, therefore, extends past financial losses, underscoring the consequences of their profit-driven motives.
The evolution of ransomware techniques is directly linked to increased profitability for attackers. Double and triple extortion tactics provide more leverage, increasing the likelihood of payment, as attackers not only extort victims, but also have the option to sell the stolen data. This increased profitability often directly funds the development of more effective and profitable RaaS tools, creating a cycle that perpetuates itself.
A Widespread Threat
While ransomware is widely acknowledged as a serious threat, some believe that strong cybersecurity measures—such as up-to-date backups, robust endpoint protection, and employee training—are sufficient to mitigate the risk. However, even the best backups become ineffective when attackers focus on extorting personal information, as ransomware has evolved to more aggressive tactics.
Some argue that triple extortion is still in its pilot stages and believe that most organizations and individuals are unlikely to be targeted by such sophisticated attacks. However, the tools and techniques used for triple extortion are becoming increasingly accessible. The democratization of cybercrime tools, due to RaaS providers, lowers the barrier to entry for attackers. For example, using AI-generated images, it has become relatively easy to place a victim into a compromising position.
Additionally, anyone with enough financial resources—such as those able to pay $25K—becomes a potential target. But it’s not just individuals with that amount of money on hand that are at risk. Those with valuable data that can be sold, or those holding data that can be used to extort a third party for a payment, also become prime targets. This makes individuals and businesses involved in supply chain networks, or affected by data broker breaches, especially vulnerable to these growing threats.
A Call to Stay Vigilant
This article aimed to shed light on the evolving ransomware landscape, encouraging both individuals and organizations to adopt proactive and comprehensive security measures. As we've discussed, ransomware has moved beyond simple data encryption; it has transformed into a multifaceted extortion tool, utilizing "double" and "triple" extortion tactics. This shift, driven by the potential for direct financial gain, the rise of personalized attacks (such as social media hijacking), and the limitations of traditional defenses, like backups, highlights the urgent need for increased vigilance.
The dangerous feedback loop, fueled by the growing profitability for attackers, demands immediate attention. This issue directly impacts personal and professional security, threatening reputations, finances, and even emotional well-being. Therefore, readers will benefit by learning more about how attacks work, engaging in meaningful conversations about these evolving threats, and taking steps to protect themselves and their organizations from the real threat of modern ransomware.

Shaping the Future of AI: Insights from Ami Badani, CMO of Arm
Mobile World Congress took place in Barcelona last week, and I’m still buzzing with the discussions from the event on the advancement of artificial intelligence (AI). A surprising company to enter the leadership fray in this space is Arm, whose technology is driving AI powered devices and applications that are transforming industries and enhancing user experiences worldwide. I caught up with Ami Badani, CMO of Arm, in a TechArena fireside chat from the show. She shared valuable insights into how the company is positioning itself at the forefront of the AI revolution. Ami’s heritage is vast, with time spent in finance as well as creating market traction at NVIDIA, so she knows a lot about both AI’s advancement and what it takes to manifest broad market opportunity.
Arm’s Crucial Role in AI
Arm has long been known for its power-efficient computing. As AI takes center stage, some might question how Arm will fare as accelerated computing has taken center stage. Arm, however, has strategically positioned itself to be in the middle of AI’s advancement noting that AI is swiftly transforming to hyperscaler driven training to inference across a vast sea of computing platforms at the edge. With its role expanding rapidly. Ami highlighted how Arm is involved in the training, fine-tuning and inference phases of AI. “You can’t do anything without a power-efficient compute platform,” Ami explained, underscoring Arm’s importance in enabling AI across a wide range of applications.
Where is AI expanding? Well, everywhere. Ami sees the technology advancing across industrial systems, autonomous vehicles, and even smart homes. And with a focus on delivering maximum performance per watt, Arm is ideally positioned to support AI in in use cases and environments that seek efficient compute at scale.
Strategic Partnerships Driving Growth
Ami highlighted Arm’s success, particularly through its strategic partnerships with major tech players - companies like NVIDIA, Amazon AWS, Microsoft, and Google, all of whom rely on Arm’s power-efficient compute to deliver AI solutions. For example, Arm’s partnership with NVIDIA on the Grace Blackwell system (they are the Grace in Grace Blackwell) has proven pivotal for AI training and inference. Arm’s leadership extends into hyperscaler’s home-grown chips with industry behemoths including Amazon, Microsoft, Google and more tapping the architecture for their respective silicon offerings.
But the data center is just one aspect of the story here. Arm’s historic strength lies at the edge especially mobile platforms. Arm’s collaborations with leaders Samsung and Apple powers devices like the Samsung Galaxy and iPhone where AI is rapidly integrating into the user experience. In the automotive space, companies such as Mercedes-Benz, Rivian, and Honda rely on Arm’s technology for AI-driven experiences in autonomous vehicles, from driver assistance to in-car infotainment.
AI at the Edge: The Next Frontier
Looking ahead, Ami highlighted expanding opportunities for AI at the edge. Devices in cars, factories, and homes will increasingly run AI workloads locally, without relying on distant cloud servers. This shift to edge-based AI will showcase the ability of Arm’s power-efficient architecture to enable autonomous systems to make decisions quickly and efficiently.
In addition to hardware, software optimization plays a key role in ensuring AI works seamlessly on Arm’s platform. Ami pointed out that, as AI use cases expand, software will need to evolve to better scale and deploy across Arm’s ecosystem. This focus on optimization is critical to making Arm’s technology easier to integrate into AI applications.
A Commitment to the Developer Community
Arm’s commitment to AI extends beyond hardware development. Ami emphasized the company’s commitment to empowering developers, who are vital to driving AI progress. Arm offers a wealth of resources for developers, from tools to educational content. “We have a lot going on in the developer space,” Ami said, encouraging developers to explore Arm’s offerings and engage with the company’s online presence.
Whether through social media platforms, such as LinkedIn and Instagram, or the Arm Newsroom, the company ensures that both industry professionals and developers stay connected with the latest advancements in AI and compute technology.
So what’s the TechArena take? Recent announcements, such as Arm’s inclusion as a key partner in the Stargate project with OpenAI, Oracle, and SoftBank, confirm the company’s position as a leader in AI growth and development. “Arm is at the center of everything happening in AI,” Ami said, emphasizing the company’s integral role in enabling AI at scale. I’m excited by the opportunity that the architecture represents to extend AI to the far edge and curious as to how the market responds to the rumored Arm delivered processors later this year. Expect more coverage on the company in coming weeks from TechArena.

Optimizing AI Inference: Fireside Chat with Cerebras’ Andrew Feldman
Cerebras is on a tear. Just a week ago, I had the privilege of hosting Cerebras CEO Andrew Feldman, for a Fireside Chat. He laid out his vision for the company, the background of delivering a dinner plate sized ASIC to drive AI inference at scale, and how he drives disruptive innovation where others have failed. It was a fascinating interview that showcased why Cerebras is turning customer heads.
And at AI speed, Cerebras has unleashed new momentum in the market. This week, the company announced a massive expansion of its inference capacity, adding six new AI inference data centers across North America and Europe. Powered by thousands of Cerebras CS-3 systems, this network will deliver over 40 million Llama 70B tokens per second, marking a significant leap forward in AI compute.

What’s more, the company announced a sweeping collaboration with Hugging Face, everyone’s favorite opensource AI model, bringing new capability to over 5 million AI developers.
In an AI landscape where advancements emerge weekly, the scale of deployment and the boldness of the collaboration has the potential to be a game-changer. You’d almost start to wonder if it was the week before GTC 😊.
How did we get here? Let’s wind the clock back, all the way to last week’s fireside chat. Andrew shared that he and his co-founders crafted a vision to revolutionize AI compute, as far back as 2015, after observing that existing compute architectures weren’t well-suited to handle the unique performance requirements AI demanded. They saw an opportunity to create a new type of processor that was specialized to handle the increasing demands of AI inference. This ambition led to the creation of the largest chip ever designed—one that would not only challenge conventional architectural approaches, but also surpasses them in performance.
One of the most interesting aspects of our conversation was the way Andrew and his team approached the challenge of building such a massive chip. At the heart of Cerebras’ strategy is the belief that merely improving on existing technology wasn’t enough: "If you're going to attack an incumbent, doing something a little better and a little cheaper is unlikely to get the job done," Andrew explained. Instead, Cerebras went big—building a chip 56 times larger than the largest GPU ever made.
But the scale of impact of Cerebras’ chip isn’t just about size. The design is optimized to deliver high performance with efficient power consumption, making it ideal for navigating the complex computations required by AI inference, especially when you consider power requirements of competing GPUs. The result is a chip that delivers performance that far exceeds traditional GPUs, with some models outpacing 50, 60, or even hundreds of GPUs, depending on the workload.
Today, Cerebras-based platforms are delivering results across a wide range of AI models. Andrew spoke about how their engineers are able to quickly adapt their hardware to new models, something that’s a challenge in today’s warp speed model advancement, to enable customers to utilize models of choice including support for models optimized for different languages. Cerebras technology, for example, was instrumental in optimizing Jais, a leading Arabic-language LLM developed by G42.
This model advancement, of course, assists with performance of end user deployments. One example Andrew shared that particularly resonated with me was their collaboration with GlaxoSmithKline to increase the pace of pharmaceutical innovation using new AI models. I have spoken on this platform before about the potential for AI tools to unlock new frontiers in medicine, and by putting cutting-edge compute in the hands of researchers, Cerebras is playing a role in solving important medical issues and improving lives.
Looking toward the future, Andrew predicts that AI inference advancement will continue to skyrocket, especially in industries such as healthcare, energy, and communications. He explained that the next wave of AI adoption would be driven by an interesting interplay between edge and cloud, stating that the role of edge computing would enable broad inference adoption and place more demand for data center compute. Drawing a comparison to the launch of the original iPhone, Andrew posited “everybody was worried that it would mean less data center spend.
And lo and behold, we make the device in your hand more powerful, it does more on the edge, and what do we want? We want more—and that means you go back to the data center more and more frequently.”
So what’s the TechArena take? The news this weeks puts a lot of wind in the sails of Cerebras market advancement. I expect that Andrew and the Cerebras team will leverage this news to fill 2025 with continued performance optimization advancement across large language models. I’m expecting to see more customers hop aboard the Cerebras wagon as enterprises seek inference performance at scale and are willing to invest the deep engineering collaboration time to tap Cerebras hardware to its fullest capability. This will be bolstered by the massive uptick in developer engagement through the new Hugging Face collaboration. While Cerebras may not be every enterprise’s cup of tea (for example small models may not require the gut punch of compute power that Cerebras delivers), many will be attracted by Cerebras’ performance and performance efficiency... and having a second source of supply for AI inference at scale. I love that there is another horse in the race and can’t wait to see how this plays out. More on the AI front next week as TechArena ventures to San Jose with front row seats at GTC.