
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















.webp)
Cirrascale CEO on Defining Compute Efficiency
As organizations push more workloads into inference and AI-driven applications, compute efficiency is moving to the top of every buyer’s checklist.
We sat down with Cirrascale CEO Dave Driggers to walk through the practical yardsticks they use when evaluating performance, the trade-offs behind scheduling and accelerator selection, and the engineering choices that sustain efficiency even at high rack densities.
Check out the Q&A below to learn how Cirrascale defines compute efficiency in business terms, what levers they pull to optimize GPU utilization, how storage tiers and data movement policies keep costs predictable, and the apples-to-apples tests Driggers recommends for validating provider claims.
Q1: How do you define “compute efficiency” in business terms for Cirrascale customers—what simple yardsticks (e.g., performance delivered per dollar or sustained GPU utilization during runs) actually tell you they’re getting efficient compute?
A1: We measure actual job performance and build a TCO model based upon using different accelerators (including GPUs) to determine the most cost-efficient platform for the customer to use.
Q2: From the provider side, what are the two biggest levers you pull to raise effective GPU utilization—guiding customers to the right accelerator, improving scheduling/pooling to cut idle time, or removing storage/network bottlenecks? A quick example of impact would help.
A2: We run the actual workload on different accelerators and measure the relative performance. We then compare the costs of both the hardware and the operating cost to run them. With that data we create a "total cost of ownership" (TCO). With our Inference as a Service offering we also look at the actual time the workloads need to run. Is it real time or batch? That determines the scheduling needed.
Q3: Inference at scale often loses efficiency when data movement gets expensive or slow. What have you done around storage tiers and data-movement policies to keep GPUs fed and the bill predictable?
A3: We do not charge for Ingress or Egress of data, so the bill is very predictable. We offer multiple tiers of storage to best match the performance requirements.
Q4: Rack densities are rising fast. Without getting into plumbing, how are you planning for 100–150 kW racks so compute efficiency doesn’t drop to thermal throttling or queue delays? What’s one decision that materially changed outcomes?
A4: All of our racks support water to the rack. For densities higher than 75kW/rack, we leverage Direct Liquid to Chip (DLC) and additional water to air cooling at the rack level like using RDHX doors.
Q5: Your Inference Cloud uses token-based pricing. How does that map to customers’ efficiency goals versus GPU-hour billing, and when does it meaningfully lower total cost to serve?
A5: We offer both token-based pricing with our inference as a service offering and GPU-hour billing on our dedicated inference offerings. The token-based pricing is typically a better deal for customers that are not using the servers 24/7 whereas the dedicated inference is better for folks using the GPUs continuously.

Arm’s AI Infrastructure Advantage: Efficiency Meets Innovation
The semiconductor industry has undergone a dramatic transformation over the past decade, shifting from commodity hardware approaches to purpose-built silicon designed around specific data center architectures. At the heart of this revolution sits Arm, whose 35-year legacy in efficiency-first design has positioned it perfectly for the artificial intelligence (AI) era’s demanding performance and power requirements.
I recently sat down with Mohamed Awad, senior vice president and general manager of Infrastructure Business at Arm, we and discussed how the company is enabling partners to build the next generation of AI-optimized systems while addressing the massive scale challenges facing the industry.
The Infrastructure Paradigm Shift
The cloud industry’s evolution from cobbled-together commodity hardware to purpose-built systems reflects broader changes in how organizations approach infrastructure. As Mohamed explained, the traditional approach of building data centers around available silicon has inverted entirely. Today’s hyperscalers design silicon around their data center architectures and specific workload requirements.
This shift has been accelerated by AI’s exponential growth. With projections of $6-7 trillion in AI infrastructure investment by 2030, and training models like GPT-4 requiring petabytes of data, the industry has taken to creating “AI factories”—full racks where networking, compute, and acceleration are designed as integrated systems to optimize both performance and efficiency.
Efficiency at Gigawatt Scale Drives Arm Adoption
The scale challenges caused by this transformation are staggering. Data centers are entering the gigawatt era in power consumption, making efficiency non-negotiable, and the cumulative effect of small gains can be massive.
“When you’re talking about a 500-watt CPU, pulling 20% or 30% of the power out may not seem like a lot, but when you start multiplying that across an entire data center, that means a lot more AI you can fit into those platforms,” Mohamed explained.
This efficiency advantage plays one part in explaining Arm’s growing share in the hyperscale computing market. Amazon Web Services (AWS) has already shipped 50% Arm-based compute over the past two years, and other major cloud service providers are following suit. The company forecasts that half of all compute shipped to top hyperscalers in 2025 will be Arm-based, a remarkable transformation given its previous focus on mobile and embedded applications. This growth stems from as hyperscalers recognizing the total cost of ownership benefits and performance-per-watt advantages that Arm-based solutions deliver.
Momentum Accelerates with Software Optimization Primacy
Arm’s growth in this competitive market coincides with a major shift in software optimization patterns, as today’s massive AI software infrastructure is increasingly being optimized for Arm first. As Mohamed noted, whether running on NVIDIA’s Grace platform or custom hyperscaler silicon, the software optimization work being done for Arm creates a sustainable advantage that extends across the entire ecosystem.
This shift has created a tremendous advantage for Arm, lying in the consistency of their CPU implementations across different hyperscaler platforms. Because AWS, Google, Microsoft, and other cloud providers base their custom silicon on Arm CPU implementations, software optimized for one platform can leverage benefits across all of them, creating genuine workload portability.
This consistency allows enterprises to take advantage of the 40% to 60% performance per watt improvements that hyperscalers report with their Arm-based solutions, while maintaining flexibility to move workloads across cloud providers or bring them on-premises as business requirements evolve.
Ensuring AI Success Through Ecosystem Innovation
Mohamed emphasized that we’re still at the beginning of the transformation to meet the sheer demand of AI, and that collaboration will be key to meeting this challenge. “I think it’s clear that no one organization, one company, one technology, is going to be able to solve that all by itself,” he said. “It’s incredibly important that we collaborate together and look for ways to advance for the common good se we can all benefit from the potential that AI is bringing to the table.”
This collaborative approach aligns with Arm’s historical role as an enabler of ecosystem innovation. Through programs like the Arm Total Design ecosystem, Arm provides foundational technologies that allow partners to create optimized solutions for their specific requirements rather than settle for general-purpose alternatives.
The TechArena Take
Arm’s position in the AI infrastructure transformation reflects strategic foresight allowing the company to face a confluence of market forces. While this platform may not play in every corner of the data center market, Arm has staked a claim in large and strategic segments. Their 35-year focus on efficiency-first design has become essential as the industry grapples with power and thermal constraints at unprecedented scales. The shift to Arm being the primary optimization target for AI infrastructure represents a fundamental market transition, and the approach of Arm Total Design recognizes that success in custom silicon requires comprehensive support for the entire development process.
As organizations increasingly recognize that workload-specific silicon optimization delivers measurable advantages, Arm’s positioning as the flexible foundation for innovation becomes increasingly valuable. For technology decision makers evaluating infrastructure strategies, Arm’s trajectory suggests that efficiency and customization flexibility will continue driving market adoption.
Connect with Arm on LinkedIn to continue the conversation about Arm’s AI infrastructure innovations, or learn more about Arm’s solutions at arm.com.

AI in Finance: Governance, Compliance, and Innovation
Anusha Nerella joins hosts Allyson Klein and Jeniece Wnorowski to explore responsible AI in financial services, emphasizing compliance,collaboration, and ROI-driven adoption strategies.

Cerebras Scales Real-Time AI with Wafer-Scale Innovation
At AI Infra Summit, CTO Sean Lie shares how Cerebras is delivering instant inference, scaling cloud and on-prem systems, and pushing reasoning models into the open-source community.

Cerebras Soars with $1.1 B of Pre-IPO Investment
Andrew Feldman, founder and CEO of Cerebras Systems, has a vision of taking on NVIDIA for AI supremacy. His team, best known for inventing wafer-sized chips to fuel AI acceleration, has recently expanded its approach to drive customer adoption with new data center environments, spurring developer activation on their platforms. The latest opened just last week in Oklahoma City.
This model of owned service delivery, combined with instances on tier-one players like AWS, makes sense given the complexity of Cerebras' solution deployment and the immaturity of broad-scale enterprise inference deployments. What's sprung from service offerings? More market traction, with a "who's who" of the AI landscape engaging. Collaborations with Hugging Face, Docker and Data Robot have given more credibility to the company as investors sift through alternatives for the next major move for their portfolios.
While some had expected an IPO at this time, Cerebras had recently faced criticism over concentrated investment from the Middle East thwarting its progress. This latest round of pre-IPO funding buys the company time to garner more market traction while signaling U.S. investor confidence in its long-term outlook.
Led by Fidelity Management & Research and Atreides Management, the heavyweight list of backers—including Tiger Global, Valor Equity Partners, 1789 Capital, Altimeter, Alpha Wave, and Benchmark—bolsters confidence in Cerebras' trajectory and puts a valuation north of $8 billion on the firm. Notably, 1789 Capital's involvment stands out, given its close relation to the Trump administration and potential warming of U.S. interests in the company's future.
At TechArena, we’ve been longtime fans of Cerebras’ designs and market engagement for years. We see this new round of funding as testament not only to the surging demand for AI acceleration (and competition for team green) but also to the bold path Cerebras is carving from silicon to services. Should we begin to view Cerebras as a neo-cloud alternative with homegrown silicon built in? Perhaps we're getting ahead of ourselves, but we're excited to see what is next for market traction now that the company has been infused with a strong dose of capital.

5 Fast Facts: Arm’s Role in Shaping AI Infrastructure
As artificial intelligence (AI) becomes central to virtually every layer of the compute stack, the onus is shifting from “who can build a fast chip” to “who can build an efficient, scalable, end-to-end AI platform.” Arm has staked its reputation on not just the cores, but on knitting together silicon, software, tools, and partner ecosystems into something more holistic. In this conversation, we put this thesis to the test with Eddie Ramirez, vice president of Go-to-Market, Infrastructure Business at Arm.
Eddie walks us through how Arm’s approach differs when viewed through the lens of full stack deployment rather than just instruction sets, and why decisions made today in software portability, workload optimization, and partner enablement will echo throughout the AI infrastructure investments of the next decade. Below, he dives into how Arm is enabling AI across data centers, edge environments, and everything in between.
Q1: Arm is central to AI across data center, edge, and devices. From your vantage point, what makes Arm’s approach to AI distinctive at the platform level, not just in cores, but in how partners build and deploy AI services end-to-end?
A1: What sets Arm apart is that we’re enabling entire ecosystems. From data center to edge, Arm provides a common foundation across computing components while giving our partners the flexibility to design silicon optimized for their specific workloads. Beyond the silicon, we’re deeply invested in the software stack and tooling and the developer ecosystem, helping developers get top-tier AI performance. We provide tools like Arm Kleidi, a software library that is integrated with leading ML frameworks, to help developers get the best performance possible on Arm-based systems without needing to rebuild their workflows. This full-stack enablement is what makes our approach unique.
Q2: We are shifting to accelerated compute platforms fueling AI factories in the data center. How does Arm help deliver performance and efficiency as a foundational element in these platforms?
A2: With the amount of data that will pump through AI factories, efficiency is no longer negotiable. The highly power efficient Arm Neoverse platform enables hyperscalers and cloud providers to design for high performance, high-throughput AI workloads without breaking their thermal or power envelopes. That means more compute in the same footprint and more AI delivered at scale.
Q3: Analysts project roughly $1T in AI infrastructure investment by 2030. Where does Arm expect the biggest efficiency gains to come from in that buildout, and what choices today will compound the most value over time?
A3: The most valuable efficiency gains will come from system-level choices like performance-per-watt optimization, workload-specific silicon, and software that’s portable across environments. We’re helping the industry enable greater performance with optimized silicon and giving developers a consistent foundation that scales with them.
Q4: Enterprises and providers are moving toward more tailored silicon. How are Arm Total Design and Neoverse CSS accelerating that shift, and what macro outcomes (i.e. time-to-market, performance-per-watt, cost predictability) matter most to customers?
A4: Time-to-market, performance-per-watt, and cost are consistently the top considerations for companies building specialized silicon. Arm Total Design was designed to address those needs by bringing together the pre-integrated foundation of Neoverse CSS with an ecosystem including IP providers, foundries, and EDA tools, working collaboratively. The Arm Total Design ecosystem helps accelerate partners’ time to market with lower engineering costs and reduced friction.
Q5: How does Arm approach software optimization across environments, and does this include work to drive more efficient workload management?
A5: Arm Neoverse architecture is already the foundation for major hyperscaler platforms like AWS’ Graviton, Google Cloud Axion and Microsoft Cobalt. The wide availability of Arm-based options enables a unified software experience for end customers across clouds, on-prem, and edge. We optimize from the framework level all the way down, allowing developers to build once and deploy efficiently and effectively, regardless of environment. For workload management, we invest in tools that help customers make smarter decisions about where and how workloads can be optimized. For example, the Arm Total Performance tool provides the insights needed to tune for performance, efficiency, and scalability of software workloads running on Arm-based silicon. Our goal is to maximize efficiency across entire systems, not just at the chip level.

Nlevel Rethinks Power: What If Energy Worked Like the Internet?
In my line of work, I come across a lot of interesting technologies—some evolutionary, others so revolutionary they challenge the status quo. Real-Time Energy Routing (RER) is one of the latter. Data centers are the invisible engines of the digital world, powering everything from cloud services to AI. Yet, their energy needs continue to rise, consuming around 1-1.5% of global electricity and relying on centralized, inefficient power grids and backup systems. At some point, this insatiable power demand will become a showstopper. What if we could rewrite the rules of energy distribution for data centers?
One ex-Tesla electrical engineer thinks it can be done. His company, Nlevel.de, has developed RER, a concept that radically reimagines how energy flows through data centers. Instead of treating electricity as a static commodity, RER proposes an energy internet, where power is dynamically routed and modular, just like how data packets flow over a network.
The BIG Idea: Energy as a Network, Not a Lake
Just as the internet replaced local traditional phone systems with a global, open network, RER replaces rigid power grids with a modular, software-defined energy architecture. At its core, RER introduces Energy Routers (RERM), small, intelligent modules that dynamically route electricity, much like how routers manage data traffic. These modules enable an open, interoperable energy network where electricity flows in parallel, eliminating single points of failure and inefficiencies.
Why This is Revolutionary
Traditional data centers rely on centralized Uninterruptible Power Supply (UPS) systems and diesel generators for backup. RER turns every rack into a node in a self-healing energy network. Imagine a data center where energy is as flexible and scalable as cloud computing—where solar panels, batteries, and grid power seamlessly integrate without conversion losses or mechanical switches.
Key RER Components:
- Modularity: RER modules scale from low to high voltage, accommodating a mix of old and new batteries, grids, and renewable sources.
- Software Control: Energy flows are managed in real time, optimizing efficiency and resilience.
- Open Protocol (RERP): An open standard for energy transmission, ensuring compatibility across diverse energy sources and systems.
How it Works: Decentralized Energy Routing
RER’s architecture is built on the principle of decentralization. Instead of relying on a single, centralized power source, RER distributes energy management across a network of RER Modules (RERM). Each module acts as an intelligent node, capable of routing energy dynamically based on real-time demand and supply conditions. This modular approach allows datacenters to integrate a variety of energy sources—such as solar panels, batteries, and the traditional grid—directly into their infrastructure.
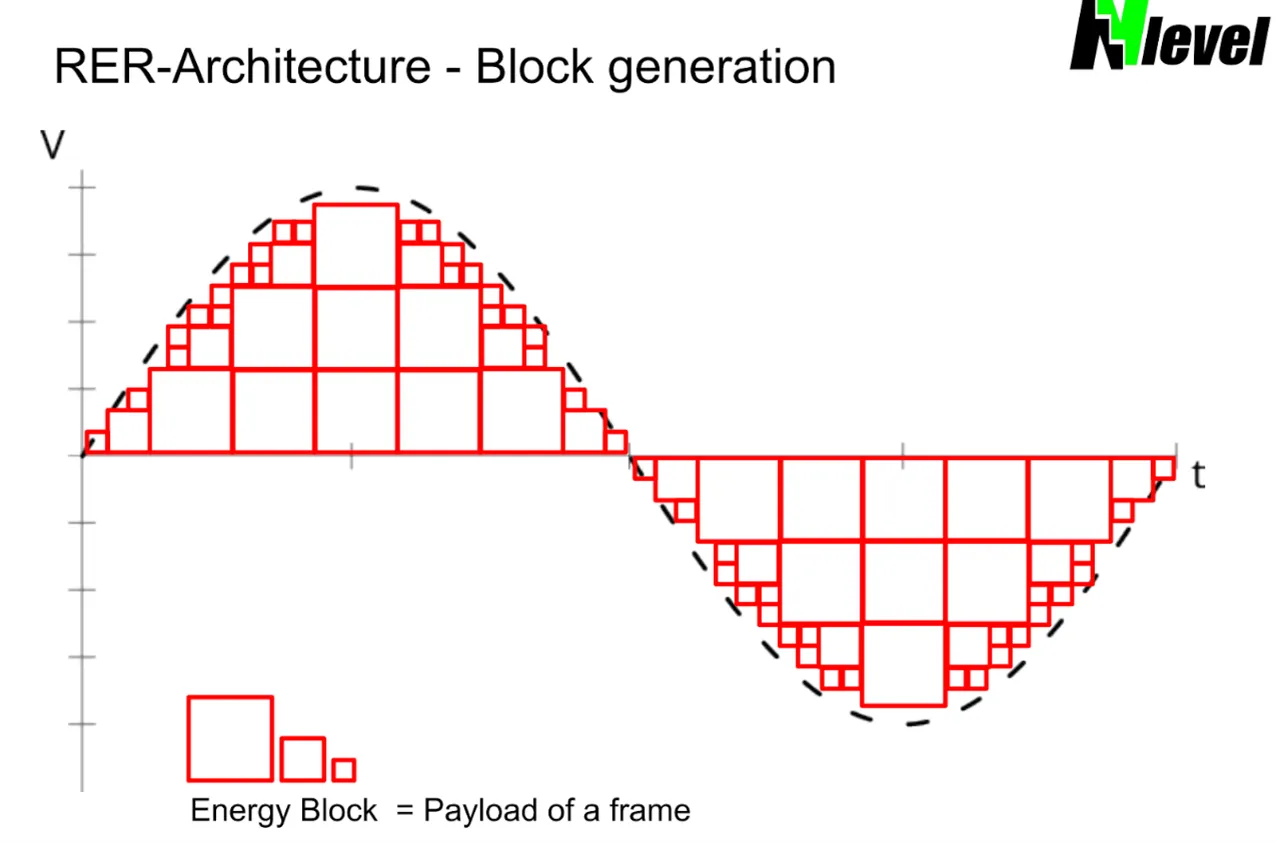
This diagram illustrates how RERM modules connect in parallel, forming a scalable and redundant energy network. Each block represents a module that can route energy bidirectionally, enabling seamless integration of multiple power sources and loads. With the ability to scale by adding more modules.
Dynamic Energy Flow
Each RERM module is equipped with advanced power electronics that enable bidirectional energy flow. This means energy can be drawn from or supplied to any connected source, whether it's a battery, a solar panel, or the grid. For example, during peak solar production, excess energy can be routed to batteries for storage or directly to server racks. Conversely, during high demand or grid outages, stored energy can be seamlessly redirected to where it's needed most. This creates a self-balancing energy network that adapts to changing conditions without manual intervention.
Storage Agnostic
One of RER’s standout features is its storage-agnostic design. The system can work with any type of battery technology — lithium-ion, flow batteries, or even emerging storage solutions — without requiring significant reconfiguration. This flexibility ensures that datacenters can leverage the latest advancements in energy storage as they become available, future-proofing their infrastructure.
Software-Driven Control
At the heart of RER is a software-defined control system that continuously monitors and optimizes energy flows. This system uses algorithms to predict demand, manage load balancing, and ensure resilience. By eliminating the need for mechanical switches and centralized busbars, RER reduces points of failure and enhances the overall reliability of the energy network. The software can also prioritize renewable energy sources, further reducing the carbon footprint of data centers.
Scalability and redundancy
RER’s modular design allows for easy scalability. Data centers can start with a small number of RERM modules and expand as needed, adding more modules to accommodate growth or integrate new energy sources. Additionally, the decentralized nature of the system provides built-in redundancy. If one module fails, energy can be automatically rerouted through other modules, ensuring uninterrupted power supply.
Why this Matters for Data Centers (and Potentially Beyond)
RER’s ability to directly integrate renewable energy sources — like solar and batteries — without the need for energy conversion is a game-changer for sustainability. By eliminating waste and reducing reliance on fossil fuels, RER could significantly lower the carbon footprint of data centers, aligning them with global climate goals. Beyond sustainability, the system’s design ensures inherent resilience. With no mechanical switches or central busbars, energy flows are managed in real time, creating a self-healing network that minimizes downtime. This resilience is especially critical for modern data centers supporting high-demand applications like AI and machine learning, where uninterrupted power is non-negotiable.
What truly sets RER apart is its future-proof modularity. Compatible with the Open Compute Project (OCP), RER can adapt to evolving technologies, from advanced battery chemistries to higher voltage systems, without requiring costly infrastructure overhauls. By reducing the need for copper cabling, mechanical switches, and large-scale infrastructure, RER not only lowers capital and operational costs but also translates efficiency gains into long-term energy savings. This makes it a scalable, cost-effective solution for both today’s needs and tomorrow’s innovations.
.webp)
The Mindset Shift
The biggest challenge isn’t technological—it’s conceptual. The industry has long treated energy as a pool of resources, something to be managed rather than optimized. RER demands we think of energy as a clearly defined, programmable object — like data in a network. This shift opens up new possibilities: If data centers can operate like nodes in an energy internet, why not extend this model to smart grids, electric vehicles, or industrial facilities? The potential for RER goes far beyond data centers — it could redefine how we distribute and consume energy across all sectors.
Final Thoughts
The journey toward a decentralized energy future is already underway. Early adopters, particularly those aligned with the Open Compute Project, are piloting RER’s modular 48V/800V hybrid systems, marking the first steps toward a bold vision: data centers powered by fully decentralized, renewable energy networks. While RER is still in its early stages, its potential to transform energy systems is undeniable. As the industry continues to seek sustainable and resilient power solutions, RER stands out as a development worth watching — one that could redefine not just data centers, but the broader energy landscape.
If interested you can learn more about nlevel RER here: https://nlevel.de/

AI-Generated Code: Unlocking Speed – with Guardrails
Artificial intelligence (AI) is transforming software engineering. Generative AI tools now enable rapid function creation, efficient refactoring, and swift generation of complete modules. For developers and organizations seeking improved delivery timelines, this capability marks a significant advancement. Teams are able to allocate more time to complex problem-solving while reducing repetitive coding workloads and mitigating lifecycle bottlenecks.
However, these advancements bring new challenges. Research indicates that some AI-generated code snippets may feature vulnerabilities. This should not deter adoption; rather, it underscores the importance of integrating AI within robust security frameworks. As compilers, version control systems, and automated testing have previously revolutionized development, AI will become an essential partner when speed is balanced with security.
The Importance of Guardrails in AI Deployment
AI-assisted code generation excels at delivering functional solutions efficiently, but can occasionally replicate insecure patterns from training data or overlook specific contextual nuances. Outputs that seem correct initially may necessitate adjustments to comply with industry regulations or meet unique business needs.
These limitations highlight the ongoing necessity for human judgment within the process. Developers play a critical role in reviewing and enhancing AI-generated code, ensuring both operational effectiveness and resilience against contemporary threats. By implementing appropriate safeguards, organizations can leverage AI advances without compromising system security.
Enhancing Threat Modeling in the AI Age
Threat modeling remains fundamental to embedding security at the design stage. Its significance is magnified as AI accelerates development cycles. Rather than a static procedure, threat modeling should become a continuous practice that evolves alongside rapid technological changes.
Ongoing threat modeling enables organizations to identify risks associated with AI-generated code, validate architectural assumptions, and prioritize mitigation strategies. Advanced automated validation tools complement these efforts by flagging issues such as insecure input handling and outdated cryptographic protocols. Through a combination of automation and expert oversight, teams can manage the pace of AI-enabled development while reinforcing security across all stages.
Transforming Risks into Strategic Advantages
Viewing AI solely as a source of potential vulnerability overlooks its value in elevating security practices. The efficiency of AI-driven output permits developers to dedicate additional resources to secure design, thorough testing, and comprehensive validation. This facilitates accelerated feature development, prompt feedback loops, and integration of stronger controls without impeding release schedules.
This creates a positive cycle: AI streamlines productivity, while effective threat modeling maintains rigorous security standards. Over time, organizations adopting this approach will benefit from enhanced agility, greater resilience, and increased stakeholder trust.
Human-AI Collaboration: Advancing Secure Innovation
The integration of AI does not diminish the essential roles of developers and security professionals; rather, it augments their capabilities. Developers can delegate routine coding tasks to AI, focusing their expertise on quality assurance and alignment with organizational standards. Security specialists can embed best practices directly into AI workflows, reinforcing security throughout the development pipeline.
Forward-thinking organizations treat AI-generated code similarly to contributions from junior developers: valuable, yet subject to thorough review and mentoring. This ensures consistent human supervision and informed decision-making, allowing AI to enhance overall productivity. The result is innovation that is both expedited and fortified.
Shaping the Future of Secure Development
Merging AI technologies with established security practices paves the way for advanced development environments. These settings may include real-time compliance checks for every line of AI-generated code, immediate risk identification, and seamless refinement of outputs. Incident response teams could harness AI-driven analytics to expedite vulnerability detection and resolution. Such possibilities are increasingly accessible as organizations adopt AI responsibly.
Striking the right balance between productivity and discipline is essential. Organizations that integrate security-focused workflows, encompassing threat modeling, automated validation, and a strong security culture will transform AI from a risk factor into a foundational competitive advantage.
Conclusion
AI-generated code presents organizations with significant opportunities to innovate rapidly. While it introduces new security considerations, these serve as catalysts for improvement. By advancing threat modeling methodologies, incorporating stringent guardrails into development processes, and maintaining human expertise at the forefront, organizations can fully realize AI’s potential while protecting future interests.
Secure software development is not a choice between speed and safety; it is an undertaking that requires the pursuit of both. Embracing AI-fueled innovation concurrently with robust security measures is pivotal to sustaining progress and resilience.

Ventiva Reinvents Cooling with Silent Airflow Tech
Ventiva CEO Carl Schlachte joins Allyson Klein to share how the company’s Ionic Cooling Engine (ICE) is transforming laptops, servers, and beyond with silent, modular airflow.

Intel on Compute Efficiency and the Future of AI Data Centers
As generative AI workloads push data centers into ever-higher power densities, the race for compute efficiency is more urgent than ever. Intel is staking a bold claim: an ambitious 10× energy efficiency improvement for server processors by 2030. But that goal doesn’t live in a vacuum. Behind it lie deep architectural trade-offs, new cooling paradigms, and the evolving balance between Arm and x86 in large-scale deployments.
In this Q&A, Intel’s Lynn Comp tackles these tensions head on. We explore whether energy gains in mobile SoCs map to cloud environments, what innovations are driving the 2030 target, and how enterprises can navigate power versus performance, especially as AI racks surge toward 100 kW+ densities.
Q1: Many claims are made that the Arm (Advanced RISC Machine) architecture is inherently more energy efficient than x86 in the data center, pointing to the fact that Arm is the basis of the iPhone and Apple computing clients that deliver some of the best battery life from within the phone and laptop. How much does the efficiency of a system on chip (SoC) designed for a cellphone translate into efficiency in the largest cloud scale compute instances? Do enterprises realize a benefit from the efficiency of Arm in the largest cloud instances?
A1: The Architectural (“capital A”) debate between complex instruction set computing (CISC) and reduced instruction set computing (RISC) has raged for decades. While this might be entertaining for academics or the most technical members of the press and analyst communities, the real-world efficiency of a CPU is primarily driven by micro-architectural decisions including, but not limited to: circuit design, the number of execution engines implemented, cache size, voltage/frequency operating points, process node, process optimization (low leakage or high performance) and advanced power management capabilities known as “P-states”. x86-based CPUs are used in three quarters of the enterprise server and cloud instances based on its proven ability to deliver the best combination of performance, energy efficiency, and software compatibility for the workloads that matter in today’s data centers and tomorrow’s AI factories. There are examples of highly efficient x86 client and server implementations that offer better battery life and more efficient operations than their Arm-based equivalent implementations.
In summary, the fact that a particular instruction set architecture is used widely in battery-powered consumer devices does not imply that a given system on chip design is the optimal solution to meet the demands of the modern data center. The recently formed x86 Ecosystem Advisory Group is further advancing the instruction set architecture with consistency between x86 vendors to enable faster ecosystem adoption and end-user value.
Q2: With the amount of energy consumed by data centers continually rising, Intel has set ambitious goals, including a 10x energy efficiency improvement for processors by 2030. What specific architectural innovations and design philosophies are driving Intel toward this target, and how close are you to achieving it?
A1: With the new-generation Intel® Xeon® processors with P-cores and E-cores, we continue to deliver holistic design solutions for a sustainable and efficient data center lifecycle. Intel Xeon 6 processors are equipped with power optimization features to deliver up to 7–10% power savings at 50% load, resulting in lower total cost of ownership (TCO).
To enable power and energy measurements in data centers for software developers and drive energy transparency and industry standardization, Intel Labs teamed up with National Renewable Energy Laboratory to publish an in-depth guide to measure power and energy for its applications. With the goal of enhancing data center operational efficiency, in May 2024, Intel established the community to mobilize the entire liquid cooling ecosystem and introduced its first Open IP Advanced Cooling Solutions and reference design, which prioritizes openness, ease of deployment, and scalability in response to the growing power density in data centers, cloud, and edge computing.
We worked with key customers to drive technical feasibility of single-phase immersion cooling solution (1-PIC), to support volume adoption and deployment of this novel technology in data centers. Intel is on track to meet our 2030 server product energy efficiency goals. With the Intel Xeon 6 processor products launched in 2024, we achieved 10% of the planned trajectory for our server products, a 2.85x average toward a 10x improvement by 2030.
Q3: AI workloads are dramatically changing data center power profiles, with rack densities moving from 30kW today toward 100kW+ in the coming years. What is Intel’s strategy to be part of the solution across “head node” efficiency power management technology, and efficiency of non-accelerated platforms evolving to handle these extreme density requirements while maintaining efficiency?
A3: One of the best things that can be done to improve the energy efficiency of enterprise AI deployments is to narrow the scope of each function in the workflow to what is necessary for that task and to match the model’s architecture to a given task.
For example, in an agentic workflow, an LLM may invoke a workflow, but many of the subtasks could be executed by agents that leverage more efficient SLMs or domain-specific pre-tuned models. This can reduce the amount of reasoning or token generation to get to a result within a controlled environment as well as limit the amount of data movement or I/O, which tend to be the biggest culprits in energy consumption. Said another way, while an aircraft carrier can technically cover land, sea, and air, it can’t change direction in under four nautical miles, so using an aircraft carrier when agility is required will fail at both the mission and in accomplishing tasks as efficiently as a more agile destroyer. Even NVIDIA has blogged about this dynamic, saying, “LLMs are often recognized for their general reasoning, fluency, and capacity to support open-ended dialogue. But when they’re embedded inside agents, they may not always be the most efficient or economical choice.”
Q4: How do you see enterprises tackling compute efficiency differently than a few years ago, and how does this differ from large scale cloud players?
A4: Enterprises are struggling with a conundrum on compute efficiencies when trying to add new capabilities that spike power demands when a minimum hardware configuration delivers dozens of GPUs. The promised efficiencies in AI can look more like a Rube Goldberg machine when factoring in return on investment (ROI) and utilization of an expensive dedicated asset delivering simple use cases like chatbots and RAG-enabled document processing.
Starting with free cloud credits for prototyping has been one tactic most large enterprises have used that helps avoid direct electricity bill spikes. Unfortunately, an enterprise may find the cloud-only economics turn upside down because LLM-API costs are layered on top of existing cloud spends and can be highly variable if reasoning models are employed. Agentic AI that combines different models for narrower tasks and can leverage the location of existing data repositories reduces unnecessary round trips and improves the overall efficiency in a task.
Q5. How do you see the landscape shifting from on-prem to cloud usage within an AI era, and how does this impact our collective challenge on compute efficiency?
A5: From a practical implementation standpoint in the enterprise, data has gravity and will pull compute to it since there are so many inefficiencies in moving large datasets. Companies that were ‘born in the cloud’ are likely to have to stay there, and companies with a multi-cloud hybrid environment will be unable to change their model because of where they have data. Although sovereignty isn’t entirely a compute efficiency concept, it is possible that sovereign AI or simple data sovereignty reduces compute efficiency by moving workloads out of large scale data centers, while increasing overall efficiency by limiting the amount of data movement overall.
Reference information:
For more details including test configurations, refer to: Pages 47-49 2024-2025 Intel Corporate Sustainability Report.
Customer spotlights:
Green Data Center with Moro Hub, UAE: We recently collaborated with More Hub, UAE’s innovative data center to establish a Green Data Center powered by Intel® Xeon® Processors. Check the customer story here.
Liquid Cooling technology advancements: We recently collaborated with Shell to establish industry-first certified cooling fluids for data centers, available worldwide. Check the customer story here.

AI, Flash, and Data Protection: Scality’s Vision with Paul Speciale
Scality CMO Paul Speciale joins Data Insights to discuss the future of storage—AI-driven resilience, the rise of all-flash deployments, and why object storage is becoming central to enterprise strategy.

Valvoline Brings Liquid Cooling Power to AI Data Centers
From racing oils to data center immersion cooling, Valvoline is reimagining thermal management for AI-scale workloads. Learn how they’re driving density, efficiency, and sustainability forward.

Reinventing RAID for AI: Xinnor and Solidigm on Storage’s Future
This Data Insights episode unpacks how Xinnor’s software-defined RAID for NVMe and Solidigm’s QLC SSDs tackle AI infrastructure challenges—reducing rebuild times, improving reliability, and maximizing GPU efficiency.

AI Infra Summit 2025: Agents, Utilization, and Innovation
AI Infra Summit is an encapsulation of AI’s advancement in event form. This annual gathering in the bay has grown from tiny upstart just a few years ago to a must-attend conference for AI infrastructure providers reflecting the advancement of AI into the enterprise. It’s also a must-attend event for TechArena as we seek insight on exactly where AI value is being extracted across industries and how the industry is migrating from brute force to elegant deployments. The 2025 edition did not disappoint for key insights – let’s get started.
Agents Have Arrived Ahead of Schedule
We’ve been following the transition of pure LLM activation to agentic computing integration into enterprise workflows. I have to admit, I thought that agents would take their own sweet time gaining employee access within large firms as IT departments navigate data security, trust, and privacy concerns associated with agentic deployment. Talks with IT leaders tell a different story with adoption taking flight across market sectors.
No conversation brought this more to light than my interview with Walmart’s SVP of Enterprise Business Services, David Glick. Glick shared his organization’s advancement of multiple classes of agents focused at support of IT engineers and his group’s plans for broad scale agentic deployment across the massive retailer’s broad functions. The specificity of his narration demonstrated that this was not just talk. Walmart is aggressively utilizing agents as an employee aid to accelerate work productivity and drive efficiency to the business. And Glick was not alone. I heard Glick’s enthusiasm for agentic computing’s value well beyond what we’ve seen from true use case value from LLMs echoed in my discussions with Arun Nandi, AI lead at Carrier; Nikhil Tyagi, senior manager of Emerging Devices Innovation at Verizon Business; Rohith Vangalla, lead software engineer at Optum Technologies; and Anusha Nerella, a leading AI innovator in the financial services space.
Agents Also Fuel Infrastructure Advancement
While broad enterprise use cases were the center of the conversation, agentic computing also held focus on two other topics at the Summit: advancement of silicon to keep pace with customer demand and broad changes in how data is accessed and remembered within agentic workflows.
To unpack the former, we talked with Anand Thiruvengadam, senior director and head of AI product management at Synopsys, as he shared the news of delivery of the company’s LLM Copilot for silicon engineers as its first phase of full agentic tool delivery to this foundational use case. We’ve written about Synopsys a lot on TechArena, and this announcement was an expected advancement from the company. Still, it’s terrific to see that they are progressing with their master plan on schedule and gaining market traction with partner collaborations along the way.
And while Synopsys is the market leader in delivering this technology breakthrough to silicon engineers, they aren’t alone in driving advancement. We met with Shashank Chaurasia, co-founder and chief AI officer at Moores Lab AI, at the show, an emerging player led by a team of former Microsoft silicon architects and engineers (yes, those folks who actually make their own silicon). They have delivered full agentic AI to accelerate universal verification methodology (UVM)-based verification flow and are claiming traction with the who’s who of silicon development with their new capabilities. While this addresses a small slice of silicon design, we walked away with two insights. First, agentic integration in this space will be driven quickly based on a critical need for silicon design teams to accelerate product design cycles while also widening chip delivery for custom solutions. Second, there’s a unique alignment for development of agentic control from those with experience in the domain, and this should influence how we see startups arrive for different function integration across a broad swath of use cases.
And as we weave a gordian knot of interconnected advancements on display at the Summit, we shift to what agentic computing means to the breadth of infrastructure architecture. One thing that stood out to me was the growing importance of storage architectures within an agentic world. Anyone who has actually used an agent knows that sustained memory is critical for workflow completion, and leading industry voices echoed this sentiment in discussions, including David Kanter, founder of MLCommons and head of MLPerf, and Daniel Wu, AI executive and educator. Key takeaway? Expect storage innovation from media to systems and orchestration to continue to advance at a frantic pace as operators build out agentic computing’s ability to remember.
Feeding Compute is the Name of the Game
Workflow advancement also showcased the importance of compute innovation and also uncovered some surprising trends on where and what compute is required to fully deliver agentic advancement. We started the show a chat with Mohamed Awad, SVP and GM of infrastructure business at Arm, where he shared how his company has grown massive traction in the data center through efficient CPU delivery. Of course, we’ve seen this with hyperscale adoption of Arm as its chosen core for indigenous silicon advancement, but we also are seeing broader market traction as Arm cores become more ubiquitous and things like workload portability become less of a hurdle to manage for IT administrators.
In case you’ve forgotten, Arm is also the Grace in Grace Hopper, and while team green gets most of the credit for heady performance delivered for AI factories, Grace is delivering important control at multiple points along an AI workflow, especially when we forward our focus to agentic computing.
Arm demonstrated this at the conference, highlighting how the Arm Neoverse processor handle many critical elements of the agentic workflow. Utilizing a Gmail automation use case, emails were fetched and analyzed for intent. Based on this analysis, specialized agents were then deployed to schedule, summarize and create replies. It was a terrific reminder that as the “head node” within the system, the CPU was acting as the workflow control center, managing system resources, igniting actual execution of the workflow like retrieving and delivering emails, pre-processing data, and triggering actions based on the analysis delivered by the GPU. If we think about what CPUs and GPUs are good at, this makes perfect sense, and Arm gave us a good reminder that CPUs remain master of the domain and could be argued to have a renaissance of relevance coming as agentic workflows become much more advanced.
Arm, of course, was far from the only processor vendor on hand. A slew of accelerator vendors showcased their latest advancements, including the largest processor on the planet, Cerebras, and arguably the most advanced power sipping accelerators around, Axelera AI. We loved to see both of these extremes on display as they provided insight into the breadth of deployment scenarios driving AI adoption today, from the Cerebras clouds popping up all across the globe to Axelera AI’s target of edge implementations requiring dialed in performance for power sensitive environments. We’re excited to see these companies gain market traction, noting that open innovation will fuel advancement to keep the entire industry working together to the customer’s benefit.
SOS: Compute is Stranded
Our final takeaway is likely the largest challenge facing transforming AI data centers from brute force compute delivery to elegant deployments that balance performance, efficiency, and scale. The truth is that an alarming percentage of GPU utilization is left sitting idle in data centers today…waiting for data to process. When you consider the vast sum being spent on these processors, it’s clear that increasing GPU utilization should be a rallying cry for the entire industry to solve. And while we’ve already discussed storage architecture and the transformation of data pipelines for AI workflows, another area is in need of urgent advancement: AI data center networks. Today, network congestion is the main culprit of low utilization rates with a combination of antiquated technology and poor network architecting for current requirements to blame.
Cornelis Networks has emerged as a vendor with a solution for this challenge, with the introduction of their CN5000 network solutions delivering congestion-free networking dialed in for AI workloads. I caught up Cornelis CEO Lisa Spelman at the Summit, and she confirmed that this challenge is being felt across hyperscale, neocloud, and enterprise. “Right now infrastructure is holding back the next great discovery. It’s holding back the next human achievement. It’s holding back the next business evolution…and we want to provide a path to unlocking that,” she said.
The TechArena Take: Acceleration Ahead
So what’s the TechArena take from all of this advancement? Those expecting to see the chasm of AI adoption emerge may be disappointed as enterprises heat up agentic solutions for deployment across job functions. And while early LLM use cases have been somewhat limited to customer support, marketing, and other read/write heavy environments, agents will go deeper into every corner of business, fueling a broad adoption of AI infra from cloud instances, to enterprise on-prem, to the edge. The diversity of opportunity should rise, even if some players only carve out small segments of success, purely based on the gargantuan scale of deployment. And we’ll inch our way closer to elegant as advances are made across every element of infrastructure from compute, storage and networking to power delivery, cooling, and application oversight. Thanks to the AI Infra Summit team for putting on such a valuable conference and practitioners and vendors alike sharing their views on the state of advancement.

WEKA on AI Data Centers: A New Infrastructure Playbook
In this episode, Allyson Klein, Scott Shadley, and Jeneice Wnorowski (Solidigm) talk with Val Bercovici (WEKA) about aligning hardware and software, scaling AI productivity, and building next-gen data centers.

Inside Yotta’s Innovate Arena: Standout Breakthroughs for AI
At Yotta 2025, I had the privilege of judging Innovate Arena sessions—a Shark Tank-style innovation contest in which innovators pitched their latest concepts reimagining how we power, cool, and sustain the digital world.
From the stage, the mix of rigor and audacity was unmistakable. The ideas weren’t incremental; they aimed at what’s next—and they stuck with me.
Innovate Arena spotlighted new approaches to some of the most pressing challenges facing our industry, from infrastructure efficiency to breakthrough applications. My role as judge gave me a front-row seat to entrepreneurs and visionaries who are imagining new tech frontiers.
Innovation From All Angles
What struck me most throughout the sessions was the diversity of ideas. Some solutions were deeply technical, drilling into hardware optimization and software integration. Others were transformative in their vision—rethinking the very inputs we use to generate and deliver power. The range itself underscored that innovation isn’t one-size-fits-all. The answers to today’s challenges will come from unexpected directions, and we need to create more venues like this to give them visibility and foster open collaboration.
Judging these sessions was a blast. I got to kick the tires on bold ideas, press on the business logic, and challenge assumptions. The energy from startups and smaller teams was palpable—the spark that keeps this industry moving.
Highlights from Innovation Arena
Several presentations stood out for the way they attacked real bottlenecks across the AI landscape—everything from how we move electrons to how we pull permits. We saw farm-level methane captured and upgraded into RNG to decarbonize energy inputs, a tightly integrated power chain to accelerate delivery inside the data center, and aluminum-air systems offering cleaner, on-demand backup power. Add in smarter fiber deployments at giga-scale, a reimagined critical-power supply chain, AI that compresses permitting from months to hours, and modular/immersion builds that deploy fast with ultra-low PUEs—and you get a snapshot of innovation that’s practical, scalable, and ready for the AI era.
Amp Americas – Turning Manure into Megawatts: Capturing methane from dairy operations and upgrading it into pipeline-quality RNG, displacing fossil fuels while slashing emissions. Impact to date includes abatement tied to more than 170,000 cows and over 2.3M metric tons of CO2e avoided—showing how circular-economy thinking can deliver real grid value at scale.
DG Matrix – Integrating the Power Chain: Led by CEO Haroon Inam, DG Matrix is laser-focused on accelerating power delivery inside the data center. Their “power router” approach emphasizes tight integration of power electronics and controls to move more electrons, more efficiently, from the grid edge to the rack—exactly the kind of systems thinking AI facilities need.
Phinergy – Aluminum-Air Backup Without the Smoke: CEO Emmanuel Levy and team are advancing aluminum-air technology as on-demand, zero-emission backup power. For data centers and telecom, it offers a compelling alternative to diesel gensets—high-energy density, rapid availability, and a cleaner path to meeting uptime and sustainability targets.
Via Photon – Smarter Fiber for AI Factories: Via Photon tackled one of the most overlooked challenges in AI infrastructure: fiber optic cabling. With gigawatt-scale facilities requiring up to 10 million strands of fiber, their pre-terminated, factory-tested modules cut installation time, reduce rework, and protect against damage, helping data centers go live faster and at lower risk.
Hyper – Reinventing Supply Chains: Hyper is rethinking how we build critical power infrastructure. By tapping latent capacity in adjacent industries like aerospace and automotive, they can rapidly scale manufacturing of switchboards, PDUs, and RPPs. Paired with their Hyperspace portal, they offer end-to-end transparency and QA so customers get certainty in an uncertain supply chain.
Blumen – AI for Permitting: Blumen addressed a pain point every developer knows too well: permitting delays. Their platform digitizes zoning codes and merges them with thousands of geographic datasets, using AI to analyze requirements in hours instead of months. For data centers facing new local rules, that speed can be the difference between breaking ground or walking away.
DUG – Immersion Cooling & Modularity: DUG has proven immersion cooling at scale with near-optimal efficiency, and is now packaging that capability into modular “Nomad” units—10-foot and 40-foot containers that can be shipped, deployed, and plugged in quickly. The result: sustainable, mobile compute capacity with PUEs as low as ~1.03.
Mod42 – Modular Data Centers: Mod42 takes a ground-up modular approach. Their factory-built data centers can deploy up to 60% faster and at lower cost than traditional builds, while reducing land disturbance and improving site density, exactly the combination the AI era needs to scale responsibly.
Lessons from the Arena
Across the sessions, a few themes consistently emerged.
First, efficiency is non-negotiable. Every presentation, whether explicitly or not, touched on how solutions must reduce environmental impact. Our industry is under increasing pressure to deliver on efficiency goals, and innovators are stepping up.
Many of the best concepts drew on adjacent disciplines—agriculture, materials science, industrial engineering—bringing fresh tools to familiar problems in compute, power, and cooling.
And thirdly, the ecosystem matters. Even the most brilliant innovation needs a supportive ecosystem of investors, policymakers, and infrastructure providers to move from concept to scale. Many presenters acknowledged this, speaking to how they plan to bridge the gap from prototype to production.
Harnessing Tech for a Better Future
Serving as a judge was both an honor and a learning experience. The energy of the presenters was infectious, and their passion reminded me why I fell in love with this industry in the first place. Too often, we get caught up in the incremental—the next quarter, the next benchmark, the next feature release. Innovate Arena reminded me of the importance of stepping back to look at the big picture: where is the world headed, and how can technology be harnessed to make it better?
Props to Yotta for creating this platform. Giving innovators the stage, and giving industry leaders the chance to engage with them directly, is how we accelerate progress. The format worked beautifully—part competition, part collaboration, and all inspiration.
Looking Ahead
As I left the Innovate Arena sessions, I felt a renewed sense of optimism. The challenges we face, from energy efficiency in AI infrastructure to sustainable growth in data centers, are real and daunting. But they are not insurmountable. Events like this prove that the ingenuity, creativity, and drive to solve them are alive and well.
My biggest takeaway: innovation lives in barns, in universities, in startups, and in the imaginations of people bold enough to ask, “What if?”
I am grateful for the chance to play a part in this process, and I look forward to seeing how these ideas evolve in the months and years to come.

Hybrid AI at Scale: Celestica’s Playbook
From AI Infra Summit, Celestica’s Matt Roman unpacks the shift to hybrid and on-prem AI, why sovereignty/security matter, and how silicon, power, cooling, and racks come together to deliver scalable AI infrastructure.

Cooling the AI Heat: JetCool’s Strategy for Data Centers
Discover how JetCool’s proprietary liquid cooling is solving AI’s toughest heat challenges—keeping data centers efficient as workloads and power densities skyrocket.

Solidigm on Building Future-Ready AI Storage
Solidigm’s Ace Stryker joins Allyson Klein and Jeniece Wnorowski on Data Insights to explore how partnerships and innovation are reshaping storage for the AI era.

MLCommons: Setting the Standard for AI Performance
From storage to automotive, MLPerf is evolving with industry needs. Hear David Kanter explain how community-driven benchmarking is enabling reliable and scalable AI deployment.

AMD’s 38x Efficiency Leap Sets Stage for Ambitious 2030 Goal
As the demand for AI scales and the energy footprint of data centers comes under sharper scrutiny, AMD is pushing the boundaries of what’s possible in efficiency. The company surpassed its ambitious energy-efficiency goal ahead of schedule, with a 38x improvement, and is now setting its sights even higher: a 20x rack-scale efficiency target by 2030.
In this Five Fast Facts Q&A, I sat down Justin Murrill, senior director of corporate responsibility at AMD, to explore what these milestones mean in practice, from slashing carbon emissions for AI training to reimagining rack-level design—and how innovation in hardware, software, and ecosystem collaboration will be key to building a more sustainable future for compute.
Q1: AMD just announced surpassing your ambitious 30x25 goal ahead of schedule, achieving a remarkable 38x improvement in energy efficiency. Can you walk us through what this achievement means in practical terms for data centers and AI workloads, and how this 97% reduction in energy consumption compares to what the industry was achieving just five years ago?
When we set our 30x25 goal, we wanted to ensure it was rooted in a clear benchmark and represented real-world energy use.[i] We worked closely with renowned compute energy efficiency researcher and author, Dr. Jonathan Koomey, to develop a goal methodology that includes segment-specific data center power utilization effectiveness (PUE) and typical energy consumption for accelerated computing used in HPC and AI-training workloads.
The practical implication is that data centers utilizing AMD CPUs and GPUs can achieve the same computing performance with 97% less energy when compared to systems from just five years ago. This represents more than a 2.5x acceleration over industry trends from the previous five years (2015-2020). We achieved this through deep architectural innovations, aggressive performance-per-watt gains across our data center GPU and CPU products, and software optimizations.
Our teams are accelerating innovation to improve energy efficiency, which will continue to have ripple effects. On the software side, we can continue to drive enhancements well after products ship. As exciting as it was to beat our goal, we are looking forward to the advances we will continue to make.
Q2: With AI scaling rapidly and energy demands growing exponentially, you’ve set another bold target: 20x rack-scale efficiency improvement for AI training and inference from 2024 to 2030. This shifts from node-level to system-level optimization. What drove this strategic pivot to rack-scale metrics, and how does this new goal address the reality that a typical AI model requiring 275+ racks today could theoretically run on less than one rack by 2030?
As workloads scale and demand continues to rise, node-level efficiency gains won't keep pace. The progression of our product goals to rack-level reflects an expanding ambition and business strategy to optimize a broader portion of the ecosystem. This is reflected in our journey to building a best-in-class portfolio to address the rapidly evolving AI market. Over the last few years, we have made several strategic acquisitions to expand our AI software, hardware and systems capabilities, including scaling to full rack-level system design with the acquisition of ZT Systems.
Our new rack-scale goal outpaces the historical industry improvement trend (2018 to 2025) by nearly 3x. To demonstrate the real-world implications of our goal, we used a typical AI model in 2025 as a benchmark, which today requires more than 275 racks for training. With the energy efficiency gains we plan to make, we believe we could accomplish this training with less than one fully utilized rack in 2030.[ii] This rack consolidation could enable more than a 95% reduction in operational electricity use and a 97% reduction in carbon emissions.
Q3: The environmental implications are staggering – potentially reducing carbon emissions from 3,000 to just 100 metric tons CO2 for training a typical AI model. Given the industry’s growing focus on sustainable AI, how does AMD’s approach to energy-efficient design integrate with broader sustainability goals, and what role do you see these efficiency gains playing in making AI more environmentally responsible at scale?
Our environmental sustainability goals span our operations, supply chain and products, and are integrated into how we conduct business responsibly. Increasing the computing performance delivered per watt of energy consumed is a vital aspect of our corporate strategy, our climate strategy, and our ethos to tackle some of the world’s most important challenges. Global electricity consumption trends show a collective trajectory to consume more energy than the market can support within the next two decades.[iii] Further, many of our customers have energy efficiency and GHG emissions goals of their own. Therefore, the need for innovative energy and computing solutions is becoming increasingly important – perhaps nowhere more so than in the data center.
We also see opportunities for AI to advance overall data center sustainability. For example, AI-driven power management can identify inefficiencies, like underused or overtaxed equipment, and automatically adjust the allocation of resources for optimal power consumption. AMD GPUs, CPUs, adaptive computing, networking and software are designed to all work together seamlessly to help optimize data center energy management systems by adjusting workloads and system configurations.
Beyond the data center, AMD today is the only provider delivering end-to-end AI solutions. Being able to deliver AI compute locally on a device – whether a PC or a processor embedded at the edge – can help reduce the power burden on data centers.
Q4: Your 20x goal represents what AMD can control directly through hardware and system design, but you've indicated that combined with software and algorithmic advances, we could see up to 100x overall efficiency improvements. How is AMD enabling and collaborating with the broader ecosystem to unlock these additional gains beyond your direct hardware contributions?
We know that on top of the hardware and system-level improvements, even greater AI model efficiency gains will be possible through software optimizations. We estimate these additional gains could be up to 5x over the goal period as software developers discover smarter algorithms and continue innovating with lower-precision approaches at current rates. [iv]
This is why we believe the open ecosystem is so important for AI innovation. By harnessing the intelligence of the broader developer community, we can accelerate energy efficiency improvements. While AMD is not claiming that full multiplier in our own goal, we are proud to provide the hardware foundation that enables it and to support the open ecosystem and developer community working to unlock those gains.
Whether through open standards, our open software approach with AMD ROCm™, or our close collaboration with our partners, AMD remains committed to helping innovators everywhere scale AI more efficiently.
Q5: AMD has consistently exceeded its public efficiency goals over the past decade. As you embark on this new 2030 target that aims to exceed industry improvement trends by almost 3x, what gives you confidence this ambitious goal is achievable, and how will you maintain transparency and accountability as the industry watches the company’s progress toward this next milestone?
At AMD, we have repeatedly demonstrated the ability to lay out a vision for computing energy efficiency, project the pathway of innovations, and execute on our roadmap. We have significantly expanded our engineering talent pool with the best and brightest minds to deliver some of the world’s most advanced chips, software, and enterprise AI solutions. We’ve also steadily increased our investment in research and development to drive ongoing innovation in compute performance and efficiency. These strategies, along with comprehensive design solutions, will support exponential growth of both improved performance and increased energy efficiency.
Fundamentally, our culture at AMD thrives on setting big goals that address important challenges and require new ways of thinking. We will continue to transparently report annually on our progress toward our goals and work with third-parties on measurement and verification. You can read more about our recent progress in our 30th annual Corporate Responsibility Report.
[i] Includes high-performance CPU and GPU accelerators used for AI training and High-Performance Computing in a 4-Accelerator, CPU hosted configuration. Goal calculations are based on performance scores as measured by standard performance metrics (HPC: Linpack DGEMM kernel FLOPS with 4k matrix size; AI training: lower precision training-focused floating-point math GEMM kernels operating on 4k matrices) divided by the rated power consumption of a representative accelerated compute node including the CPU host + memory, and 4 GPU accelerators.
[ii] AMD estimated the number of racks to train a typical notable AI model based on EPOCH AI data (https://epoch.ai). For this calculation we assume, based on these data, that a typical model takes 1025 floating point operations to train (based on the median of 2025 data), and that this training takes place over 1 month. FLOPs needed = 10^25 FLOPs/(seconds/month)/Model FLOPs utilization (MFU) = 10^25/(2.6298*10^6)/0.6. Racks = FLOPs needed/(FLOPS/rack in 2024 and 2030). The compute performance estimates from the AMD roadmap suggests that approximately 276 racks would be needed in 2025 to train a typical model over one month using the MI300X product (assuming 22.656 PFLOPS/rack with 60% MFU) and <1 fully utilized rack would be needed to train the same model in 2030 using a rack configuration based on an AMD roadmap projection. These calculations imply a >276-fold reduction in the number of racks to train the same model over this six-year period. Electricity use for a MI300X system to completely train a def
[iii] “The Decadal Plan for Semiconductors,” Semiconductor Research Corporation, https://www.src.org/about/decadal-plan/ (accessed May 23, 2024).
[iv] Regression analysis of achieved accuracy/parameter across a selection of model benchmarks, such as MMLU, HellaSwag, and ARC Challenge, show that improving efficiency of ML model architectures through novel algorithmic techniques, such as Mixture of Experts and State Space Models for example, can improve their efficiency by roughly 5x during the goal period. Similar numbers are quoted in Patterson, D., J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L. M. Munguia, D. Rothchild, D. R. So, M. Texier, and J. Dean. 2022. "The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink." Computer. vol. 55, no. 7. pp. 18-28.”
Therefore, assuming innovation continues at the current pace, a 20x hardware and system design goal amplified by a 5x software and algorithm advancements can lead to a 100x total gain by 2030.

AI-Driven Chip Design with Synopsys
Allyson Klein talks with Synopsys’ Anand Thiruvengadam on how agentic AI is reshaping chip design to meet extreme performance, time-to-market, and workforce challenges.

Iceotope’s Sustainable Cooling Vision for the AI Era
With sustainability at the core, Iceotope is pioneering liquid cooling solutions that reduce environmental impact while meeting the demands of AI workloads at scale.


Dell Highlights Four Shifts Powering the AI Storage Revolution
Dell outlines how flash-first design, unified namespaces, and validated architectures are reshaping storage into a strategic enabler of enterprise AI success.
.webp)
5 Fast Facts on Compute Efficiency with Flex’s Chris Butler
The rise of AI has brought unprecedented pressure on the power and cooling systems that sustain today’s data centers. Racks that once drew 30kW are now pushing 100kW or more, with 1MW configurations on the horizon. Meeting these demands isn’t just about scaling capacity — it’s about rethinking the entire power delivery chain for maximum efficiency and sustainability.
Flex, a global leader in manufacturing and critical power solutions, is tackling this challenge head-on. From high-voltage DC architectures and 97.5% efficient power shelves to integrated liquid cooling and vertically integrated “grid to chip” solutions, the company is reshaping how data centers operate in the AI era.
In this “5 Fast Facts on Compute Efficiency” conversation, I sat down with Chris Butler, President of Embedded and Critical Power at Flex, to explore how innovations in power, cooling, and manufacturing scale are unlocking new levels of efficiency, and how these breakthroughs could redefine sustainable AI infrastructure in the years ahead.
Q1: Chris, we’re seeing data center power requirements evolve dramatically with AI workloads pushing racks from 30kW to potentially 100kW+ and even toward 1MW configurations. You recently announced a power shelf system achieving 97.5% efficiency at half-load for NVIDIA GB300 NVL72 systems. How is Flex rethinking fundamental power architectures to not just handle these demands, but do so with maximum efficiency? What specific innovations in DC voltage levels and power conversion are proving most impactful?
A1: As AI workloads push data center rack densities higher, data center operators are fundamentally rethinking power architectures to meet energy consumption demands with maximum efficiency, scalability, and sustainability. A broader industry shift toward high-voltage DC architectures, particularly +/- 400 V DC and 800 V DC, has the potential to reduce conduction losses, enable longer cable runs, and minimize the conversion stages required to step power down from the grid, improving system efficiency and reducing thermal management overhead.
Flex collaborates with hyperscalers well in advance of new standards and product introductions to ensure their power architectures are innovation-ready — an example being our recently announced power shelf system that is optimized for NVIDIA GB300 NVL72 platforms. Achieving 97.5% efficiency at half-load, it leverages native 800 V DC input to streamline power conversion and reduce the need for intermediate AC stages. That improves energy efficiency while simplifying infrastructure design, allowing for denser deployments and faster scalability within the same data center footprint.
Q2: Flex has rapidly expanded manufacturing capacity by over 8 million square feet since fiscal 2024, including new facilities in Dallas and Columbia, South Carolina, focused on critical power product manufacturing and assembly, and Poland, which doubled your critical power product manufacturing capacity in Europe. You've stated that “rapid AI adoption across sectors is increasing data center operators’ need for reliable, efficient, and scalable power infrastructure solutions.” How does Flex’s manufacturing scale-up enable efficiency gains beyond just meeting demand? What efficiencies are you achieving in time to market and deployment that directly translate to operational efficiency for your customers?
A2: Proximity matters. With advanced manufacturing facilities in 30 countries, we enable customer regionalization strategies while providing the local expertise and global scale needed to drive competitive advantage. Customers benefit from capabilities and expertise that allow them to shorten the distance between manufacturing and deployment, speeding time to compute — a critical ROI metric for data center operators and investors — reducing their carbon footprint, and enhancing scalability within and between facilities. It also accelerates the delivery of services, from design and engineering support through deployment, installation, refurbishment, and recycling.
Depending on the engagement, operational efficiency may take the form of faster prototyping, reduced downtime, agile deployment, or post-sale value capture, among myriad other benefits. A mosaic of manufacturing facilities across geographies also enhances supply chain resilience, enabling customers to better navigate geopolitical uncertainties, shifting demand, labor shortages, and unforeseeable disruptions. Flex’s manufacturing capacity enables us to meet the insatiable demand for embedded and critical power solutions — not to mention cooling solutions and essential infrastructure such as racks and enclosures — while delivering tangible operational efficiency gains for data center customers worldwide.
Q3: Following Flex’s acquisition of JetCool Technologies, you now offer liquid-cooled racks supporting up to 120kW per rack with a clear upgrade path to 300kW, utilizing JetCool's microconvective cooling® technology. How does integrated liquid cooling improve thermal management and overall data center efficiency?
A3: With data center cooling needs surpassing what can be accomplished with traditional air-cooling systems, liquid cooling has become the go-to choice for dealing with the excessive heat produced by the power-hungry AI and HPC workloads in high-density compute environments. Leveraging our direct-to-chip cooling technology, data center customers enable zero water consumption, over 50 percent decrease in cooling power usage, and an 18 percent decrease in total power consumption, preventing an annual emission of 35 million metric tons of CO2 with widespread adoption.
While AI receives the lion’s share of attention, it’s important to remember that it still accounts for just 14 percent of global data center power usage — which means that the vast majority of data center space is dedicated to CPU-based workloads. To that end, we’re also at the forefront of developing innovative cooling solutions that deliver immediate performance and efficiency improvements without requiring any changes to data center infrastructure. For instance, the standalone JetCool SmartPlate™ System, designed to simplify the adoption of liquid cooling, eliminates the need for facility water — not a priority in air-cooled environments — while delivering an average total IT power savings of 15 percent, enabling customers to maximize compute in power-constrained environments.
Q4: Flex positions itself uniquely with solutions spanning “grid to chip” — from critical power infrastructure through embedded power modules. Your recent analysis suggests new configurations can improve system efficiency by about 20 percent annually per rack. As you look at the complete power delivery chain, where are the biggest efficiency gains being unlocked, and how does your vertical integration approach enable optimizations that wouldn’t be possible with point solutions?
A4: With 1+ MW racks on the horizon, data center operators are rethinking their architectures as power and thermal management requirements escalate. Today, power, cooling, and servers are often fully integrated within the same rack, an innovation that has served the industry well. However, not doing so can (perhaps paradoxically) ease space constraints while imparting a host of other benefits. While power and cooling may be disaggregated into separate “sidecar” racks to increase compute capacity in the IT rack, this still requires an integrated, seamless interplay of systems from grid to chip to extract maximum value.
For instance, a beefier 4,000-amp busbar feeding power into a reconfigured data hall with an end-of-row cooling distribution unit (CDU) can accommodate high-density IT racks and elevate the power architecture to 400V. Flanking the IT racks with standalone power cabinets and CDUs not only increases the amount of space in the IT rack dedicated to compute, it opens up the data hall floorspace considerably. Furthermore, the new configuration can improve system efficiency by about 20 percent — which translates into significant energy savings annually per rack. In large data centers with thousands of racks, the potential savings are clear. Data center operators are looking for partners that have the ability to design and manufacture complete solutions and deploy them at scale worldwide.
Q5: Looking ahead to the next three to five years, AI workloads will continue intensifying power and cooling demands while sustainability pressures mount. You’ve mentioned the potential for a 90 percent reduction in electrical room square footage by 2030, along with significant energy efficiency leaps. What efficiency breakthroughs do you see on the horizon that will be game-changers for sustainable AI infrastructure, and how is Flex positioned to lead in that transformation?
A5: Traditionally, converting incoming AC power to a DC voltage usable at the chip level requires several conversion steps, each of which impacts energy efficiency. But we’re seeing higher DC voltages emerge in the data center, including the 800 V DC that allows direct connection to renewable energy systems and +/- 400 V DC required for the integration of battery energy storage systems (BESS) and microgrid applications.
Condensing power conversion into a single solid-state transformer not only produces efficiency gains, it reduces the square footage required for electrical rooms significantly — by some estimates, up to 90 percent by 2030. This opens up new paths to profitability: saving on construction costs when capacity can be met with less space or increasing compute capacity in the existing envelop by adding more racks. We call this the convergence of power and IT, and it is a welcome step forward.