
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.



















Riding the Visual Edge with Varnish
TechArena host Allyson Klein chats with Varnish CTO Frank Miller about his company’s innovation in delivering media at the edge.

Dynamic Spectrum Allocation and the Future of Digital Services with DGS CEO Fernando Murias
TechArena host Allyson Klein delves deep into dynamic spectrum allocation and new government policy that opens up innovation in how spectrum is accessed for all with DGS CEO Fernando Murias.

NVIDIA Extends AI Supremacy in the Network
TechArena host Allyson Klein chats with NVIDIA VP Rajesh Gadiyar about how his company is riding the AI wave into the heart of the network and edge with innovative platforms like the company’s powerful Ariel VRAN stack.

.webp)
Cellnex Pushes Cross Border 5G Limits with 5GMED
One of the best aspects of Mobile World Congress is uncovering interesting use cases and deployments of the latest technology. That’s why I was so excited to talk to Cellnex’s Jose Lopez Luque about his company’s engagement with the EU funded 5GMED project. 5GMED is testing resilient connection across borders for low latency, high bandwidth service delivery. Cellnex is a leading tower provider and a core participant in 5GMED focused on the France Spain border.
Why is this a focus point? 5G’s full promise delivers increased performance at the edge for services like autonomous driving or in vehicle infotainment. Those of us who travel internationally are all too familiar with the text message that comes from crossing a border stating the new carrier who is providing service and the small lag in connectivity that precedes its arrival. It’s this small lag, a tolerable nuisance for for text and talk connections, that becomes a deal breaker for more demanding applications like video transcoding at the edge. If you happen to be watching a streaming movie while a passenger of a train or car crossing a national border, you’re likely going to experience jitter at best or a dropped service. When you consider the low latency requirements of real time autonomous control of vehicles, you can see that even the smallest lag of connectivity can represent potential disaster.
This is what makes 5GMED so exciting as explained by Jose. With companies working together, these most demanding of network edge services are being put to the test. Cellnex is in a unique position to deliver core capability in this space as borders are likely rural environments without a tremendous amount of dedicated operator connections. A tower operator like Cellnex can deliver shared bandwidth to multiple providers delivering the connectivity and performance users need while keeping costs manageable for all providers.
With the successful delivery of 5GMED, we can expect broad proliferation of 5G access points across European borders in the near future opening the door for things like approval of autonomous vehicles in the EU. To learn more about what Cellnex is delivering in this space, check out our interview, and to learn more about 5GMED, visit the group’s website.
AMD Extends Network Performance and Efficiency Leadership at MWC24
TechArena host Allyson Klein chats with AMD’s Kumaran Siva about his company’s gaining momentum in telco network and edge deployments fueled by EPYC processors and the Siena products uniquely designed for these environments.

5G MED’s Cross Border Service Resiliency with Cellnex’s Jose Lopez Luque
TechArena host Allyson Klein chats with Cellnex’s Jose Lopez Luque about the EU funded 5G MED project testing service resiliency across borders to fuel low latency use cases like autonomous driving, and how his company is poised to deliver efficient and scalable services for broad deployments in 2024.

Curving Towards a Network Future at #MWC24
The great architect and artist Antonio Gaudi once said “There are no straight lines or sharp corners in nature. Therefore, buildings must have no straight lines or sharp corners.” I love Gaudi’s architecture, the elegance of curves, the simplicity of statement that the world is not linear, it is nuanced and circuitous. As we descend on Gaudi’s city of Barcelona, one that is literally littered with many of his master works and infused by his spirit wherever one turns, his inspiration can be felt in this present moment in the communications arena.
I’ve been attending Mobile World Congress for a decade and have seen the evolution of network virtualization and the promise of 5G. We’ve discussed software defined everything, the breaking of stovepipe infrastructure, and the slicing of networks. And yet, just like a Gaudi exterior, we find ourselves curving towards a destination that we can’t quite reach. The true promise of 5G has met less than full joy, and certain promises of the standard including full virtualization of the RAN, delivery of private 5G, and even cloud native network provisioning and automation are sitting at less than ubiquitous deployments. Telecom operators, who have collectively invested billions in 5G infrastructure, are still seeking the revenue streams that will deliver ROI that they’d aimed for through creation of this technology.
The question remains: will 2024 be the year that we finally see 5G hit broad scale across all of its promise? Will enterprises push through to private 5G deployments, will RAN finally be virtualized, and will cloud native NFV finally be deployed across all network services? And the million-dollar question…will AI be the disruptive force to spark this final act for 5G supremacy?
The TechArena will be engaging with companies from across the communications and edge landscape to search for progress, evaluate industry players for breakout stars, and gain proof of the hoped for promise. We’ll look at some pretty ridiculously cool use cases featured in Barcelona, we’ll delve deep into the possible future with 6G, and we’ll sketch out our views on the state of the network and edge in a tsunami of blog posts and podcast interviews befitting the king of communications conferences. And hopefully, we’ll find some time to pay homage to Gaudi himself. Watch this space for the latest from Barcelona, and if you’ll be at MWC24 next week, please connect with us!

MemryX Delivers AI Performance at the Edge
TechArena host Allyson Klein talks to MemryX VP of Product and Business Development Roger Peene about how his company is transforming AI at the edge with their silicon and how we’re sitting in an AI revolution.

MemryX Making a Case for AI Acceleration at the Edge
Yesterday at AIFD4, I wrote about Intel’s latest musings on right sized silicon for AI inference and how the company positions Xeon processors vs. GPU alternatives. This was the latest of many publications on this platform regarding the renaissance of silicon innovation in the AI arena, and one that I expect will be a feature throughout 2024 and beyond. One company that I’ve wanted to talk to in this space is MemryX, a startup founded at the University of Michigan and positioned squarely in delivering AI acceleration of visual processing at the edge.
Why is this important? Once again, we come back to data gravity. While massive AI clusters in the cloud may be the heavyweight champs of AI, the movement of data for AI inference is oftentimes impractical, expensive or downright unfeasible given latency considerations. Instead solutions require fast inference at the edge which can be delivered within the constraints of a vast landscape of edge environments. This calls for solutions that offer performance and watt sipping energy consumption.
MemryX has designed a solution that fits that bill. I caught up with VP of Product and Business Development Roger Peene, and he described a solution that delivered up to 100X more efficient than a CPU and 10X more efficient per watt than a GPU. What makes me impressed with MemryX is that they know what they want to be! They are squarely focused on a high in demand workload in the rapidly advancing edge infrastructure market. And unlike many startups in this space who talk a great PowerPoint game, they have actual silicon! In fact, they received their first silicon late last year and have it up and running in labs today, and with customers in the near future. I’m delighted to see the move to real product delivery in a space so desperate for solution alternatives to fuel customer demand, and I can’t wait to hear more from Roger and the team as solutions reach expected customer trials and deployments in the months ahead.

VAST Data Upends Storage in the AI Era
The heart of AI is utilization of data, and since the first kilobit of data was stored, we’ve been challenged with movement of data to the right place at the right time. As we’ve entered the AI Era, the concept of a data pipeline has evolved which describes the steps of preparing data for AI training. Without this prep, training will be flawed at best. The data pipeline itself is not sexy work, think of it as gathering the right ingredients before one cooks a delicious meal. And like much in life, the hard work part is necessary to get to that sublime experience. Organizations are challenged with data gathering and prep at scale based on the pure limits of traditional storage solutions and distributed data locations.
Enter VAST Data. The team at VAST recognized this opportunity in the creation of their massively scalable NAS solution that provides intelligence injection and oversight for both structured and unstructured data. First gaining traction in the HPC arena whose architectural foundations have formed the structure for AI training clusters, it makes natural sense that VAST would offer the same value for the speed, scale, and structure that these clusters require. And they have the data pipeline down cold…see this image from their AIFD4 presentation, one of the clearest depictions of the AI pipeline that I’ve seen.

What makes them really stand out to me is what they’ve delivered to manage data across distributed environments with VAST Data Spaces which helps enterprises get their arms around their data across on prem, in the cloud, and at the edge.
I first engaged with the Vastronauts at SC 22 at the launch of the TechArena, and there’s a reason I started this wonderful journey with their inclusion. What VAST is building represents the future of how we’re going to compute, and their ability to arrange, organize and compile data in the way organizations want is just the beginning of the VAST Data story. The team and their partners are driving innovation on the VAST Data platform at a ridiculous pace, and I expect to be covering a lot more in this domain in 2024. If they aren’t already, place VAST Data on your must watch list, and if you’re struggling with your data pipeline, check out their solutions.

Intel Modestly Lays its Case for AI
Today at #AIFD4 is Intel Day! Color me excited to hear about how the folks at Intel are pursuing AI workloads in 2024 given the acute innovation across the silicon arena in this space. Disclaimer: for readers unaware of my background, I spent 22 years at Intel including ownership of Xeon and AI marketing so I have a special place in my heart for this groundbreaking platform and its role in cloud to edge performance. And I don’t think it’s a surprise to anyone that Intel has been taking it on the chin in the AI arena over the past few years. They’ve at lost core CPU performance leadership to rival AMD, while NVIDIA at the same time has claimed AI silicon supremacy with their GPUs delivering the training required to unleash LLMs like Chat GPT.
Revenues and profit have suffered, and many are talking about the era of CPU centric computing coming to an end in the era of AI. At the TechArena, we’ve written extensively about the budding silicon industry developing GPU alternatives for both AI training and inference and across model sizes, power constraints, and locations from cloud to edge. So…what is Intel doing to right the ship?
Today Ro Shah, Xeon AI Director at Intel, led the charge with a discussion of where CPUs perform best and where accelerators (assuming including Intel’s own offerings) would be better tools for the job. He described a moat of 20B+ size of LLM as the magical divide between this CPU accelerator decision and outlined the evolution of AI acceleration embedded on Xeon processors over the years including the most recent integration of Intel AMX technology for INT8 and BF16. The result was a shockingly modest positioning coming from the market leader on where CPU will perform. Many of the delegates responded to this modesty with follow up questions…because there must be more right? With accelerators being developed in the “CPU zone” and targeting power sipping TDPs, we are left wondering about the magical divide being an accurate depiction of the market and where it’s going. And does it leave some of the real value that is Intel on the table?
The world today still largely runs on x86, and IT departments are ridiculously comfortable deploying Xeon processors, even today. That’s what you get when you’ve delivered consistently in market for decades. As we see the proliferation of AI extend from the sophistication of large cloud environments, and the engineers who live there that build AI models at breakfast, to the mid-market, organizations need an easy button for AI inference and Intel is uniquely poised to offer this to customers. They’ve delivered the investment in integrated AI acceleration and tools like OpenVINO to get initial AI solutions off the ground, and in so doing garner continued customer loyalty. They are also delivering Intel Core platforms for client and winning the perception game of AI optimization on these platforms which are integrating more and more inference over time.
I would like to see them claim more here, and I’m looking forward to seeing more from them as they continue to deliver both advancements in the core CPU and acceleration elements of their portfolio. I’m also excited to hear more from the other players in the industry on how accelerators will target the inference arena, how NVIDIA will leverage GPU supremacy for broader workload targets, and how AMD will leverage its performance to gain ground in broad market deployments. 2024 is going to be an exciting ride! Watch this space.
Google Cloud Talks AI Trends at AIFD4
Google knows a bit about AI. After all, their data stores include every search ever done since the birth of their browser, and they’ve been on the cutting edge of AI integration across their business from the earliest days of machine and deep learning integration. Today’s speakers from Google cloud introduced their talk by positing that AI is the next platform shift…from internet to mobile…and now AI. It’s an interesting analogy coming from a foundational force of the Internet age, and they leaned in to this pointing about the acceleration of generative AI and how many of the innovators in this realm choosing Google Cloud as their foundation. They’re taking advantage of Google Gemini, their foundational AI model that works across the Google-verse and introduced in market at the end of last year. Yesterday, Google delivered Gemma, an open model based on the same technology as Gemini and delivered by the team at DeepMind. It’s fantastic to see Google take this step and is consistent with their history of open sourcing some of their best engineering to the benefit of all (Kubernetes comes to mind as a disruptive opensource innovation delivered in a similar manner).
How is Gemma going to roll out? There’s a natural integration of Kubernetes that supports scaling up to 50K TPU chips and 15K nodes per cluster that extend support for both training and inference for a broad AI ecosystem. And while Google is talking during #Intel day at #AIFD4, they did introduce a graph showcasing their extensive support across major silicon environments:
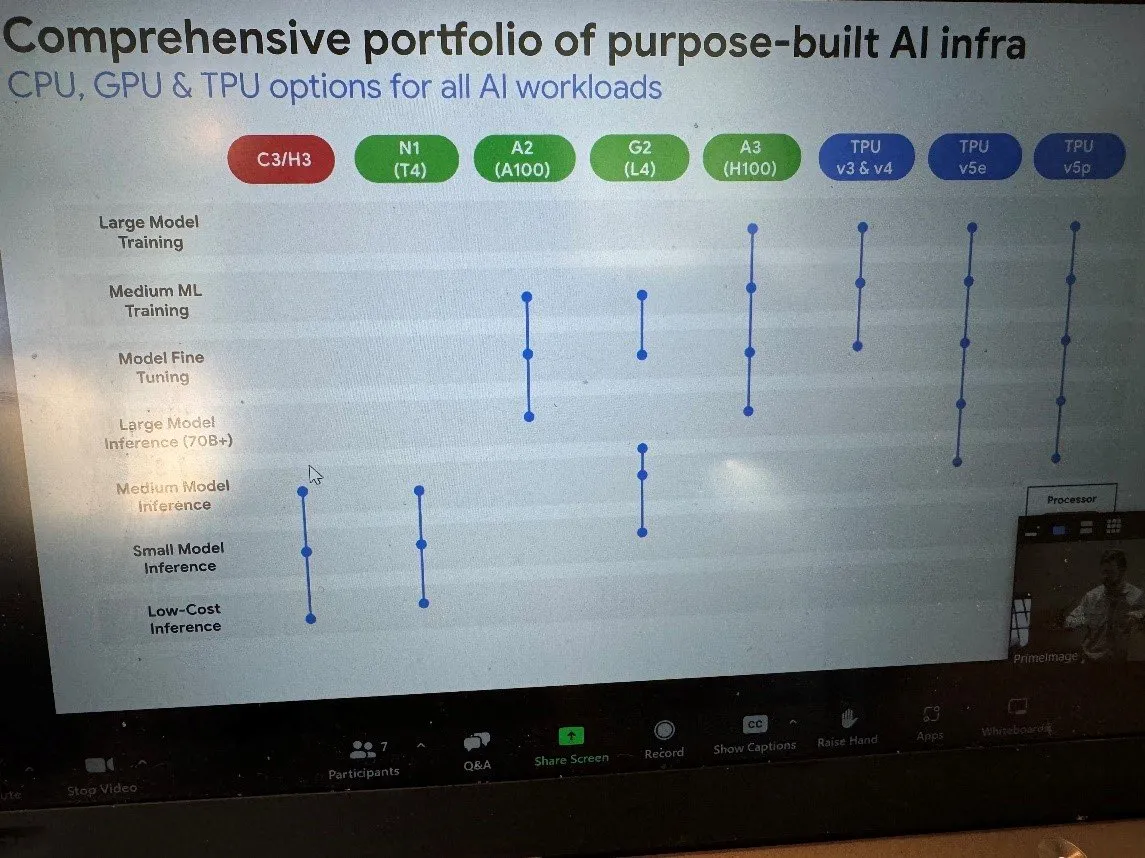
Google went further, calling out that a lot of AI still runs on CPU and noted that Intel’s AMX technology extends the capability of CPU performance for different AI models. Model size is the consideration that will fuel platform choice across CPU/GPU/TPU with Google aligned with Intel’s positioning of smaller models being the natural domain for CPU deployment. Where do Google’s own TPUs play? Google positions them at the other extreme for very large models supported by Pytorch efforts within the company. Now in their fifth generation (they’ve been delivering TPU custom chips since 2018), TPUs are available to customers on the Google Cloud platform. This delivery fits with the frenzy of AI silicon development and showcases Google’s end game in this space. I’d expect to see more emphasis here from all large cloud players who prioritize their own silicon delivery with their own AI training models, and as this landscape evolves I wonder if we’ll continue to see a multi-architecture support slide or one that more fully leads with bespoke custom silicon offerings.

AI in the Marketing Arena with Digital Sunshine’s Gina Rosenthal
TechArena host Allyson Klein chat’s with Digital Sunshine’s Gina Rosenthal about how AI is reshaping marketing as the two preview Gestalt IT’s upcoming AI Field Day 4.
The Emergence of the Chiplet Economy with Alphawave Semi’s Letizia Guiliano
TechArena host Allyson Klein chats with Alphawave Semi’s VP of marketing and product management Letizia Guiliano about the progress the industry has undertaken in the past year on an open market for chiplet innovation and how her company is positioned to thrive on the growth of chiplet solutions readying for market.

Juniper Dials Up AI in the Network
I attended Juniper Network’s analyst and influencer call a few weeks ago, in advance of today’s announcement from the company, to learn more about Juniper’s strategy in the year ahead. You may recall that Juniper was featured at the last Cloud Field Day event, where we got a deep dive into their Apstra solution. Today, as a surprise to no one, Juniper wanted to talk about AI. In fact, they doubled down on the AI Era with the introduction of their AI-Native Network Platform, claiming it as the industry’s first AI-Native solution.
There is absolutely truth that network capability within this brave new world of computing is critical to maximizing organizational return. Applying AI across the network to collect data on the full network experience will enable network operations teams new tools in their toolboxes to manage and optimize the network, and that’s reason enough to make Juniper’s move here quite interesting. When you look at the claims of improved efficiency including elimination of 90% of network trouble tickets, 85% of IT onsite visits, and cutting network issue resolution time in half, you realize that this is not just an interesting academic step into AI but a potential game changer for network operations management holistically.
How do they plan to pull it off? Juniper is targeting leadership with a common cloud native, microservices based AIOPS for the network across data center, campus, and branch, with wider automated WAN coming in the near future. Juniper’s CEO Rami Rahim was very quick to point out that the AIOPS platform was over seven years in the making, forming a major market advantage vs. other network providers. The team went further to discuss deep partner collaborations to bring this core capability to market with the support required to enable swift deployment that works from day one. A highlight of their offering is the introduction of the new Marvis Minis which is automating problem resolution in real-time without users needing to be engaged. They coupled this with Marvis VNA for the data center, delivering a Chat GPT like conversational interface to drive performance of critical applications and ensure improved customer experience. These tools make the claims mentioned above seem attainable when you consider what they provide network ops teams vs. currently available solutions.
Will Juniper be successful in this differentiation? Questions from the analysts and influencers in the session focused on the depth of capability to the new solutions offerings that integrated automation and deeper awareness into the network. There was a drilling down into the topic of WAN as there was no mention of specific AI tools for the WAN environment in our briefing. Juniper acknowledged that the WAN represents broader complexities for integration of these types of tools, but they called out the microservice based common cloud as key to the road forward.
Ethernet fabrics also came up given the importance of this technology for AI compute clusters. This is an area where Cisco has been leading, and Juniper did not have a complete answer when I asked about their strategy at Cloud Field Day. I think this is a space to watch from Juniper moving forward as they underscored the importance of advances to the technology to meet specific AI requirements in their response and were more front footed that more details would follow.
What is the TechArena take on Juniper’s direction? I love the lean in to AI as a strategic element of automating the network end-to-end. I appreciated the honesty on complexity of the WAN space and expect to hear more about their engagement in WAN in the months ahead. The same holds true for data center fabrics. I expect this to be an arena of massive industry advancement with Ultra Ethernet standards delivery to compete with InfiniBand in the advanced edge of capability, and Juniper in my mind will have a role to play in delivery of fabric innovation. Overall, I’m intrigued by Juniper’s announcement today as it underscores a symbiotic relationship between the wide-reaching impact of AI’s transformation of all computing functions including network automation and the importance of network innovation to the future of AI. I do expect other network providers to swiftly follow suit. After all, they too have been privy to the endless industry chatter on AI advancement that was the zeitgeist of 2023. But today is Juniper Network’s day in the sun. Kudos to the team for pulling off this leadership announcement. The TechArena team can’t wait to hear more.

Things Get Interesting with Voltron Data’s Acquisition of Claypot AI
Voltron Data was recently featured on the TechArena discussing composable data system delivery with their Theseus solution. I was ridiculously intrigued by both Josh Patterson’s team’s approach to solving a really challenging aspect of data analysis with acceleration of data preprocessing at scale and the organization’s background in deep knowledge of GPU architectures and accelerated system design. This background has enabled Theseus to deliver an accelerator agnostic framework that not only taps the power of GPUs but enables a host of logic accelerators to work in tandem with high bandwidth memory and fabric technologies to deliver the performance needed as efficiently as possible.
Enter Claypot AI, the company founded by Chip Huyen and Zhenzhong Xu. Claypot is a real time AI solution that will help infuse Theseus with MLOps capability and extend Voltron Data’s offerings to other industry platforms like Apache Arrow, Ibis and Substrait. The technical chops of the Claypot team is impressive. In fact, Chip wrote “Designing Machine Learning Systems” and is a professor on the subject at Stanford. She also has a history at NVIDIA so will bring this background to Theseus development and Voltron Data more broadly.
I can’t wait to hear more from this new collective team as they tackle one of the most daunting challenges of broad AI adoption which is efficient performance delivery of the entire workflow. Watch this space for more!

Data Observability in the AI Era with Unravel Data CEO Kunal Argawal
TechArena host Allyson Klein chats with Unravel Data CEO Kunal Argawal about how his organization is tapping AI to disrupt the data observability arena.
Building Composable Data Systems with Voltron Data CEO Josh Patterson
TechArena host Allyson Klein chats with Voltron Data CEO Josh Patterson about delivery of Theseus, a composable data system framework that unleashes develops with new interoperability and flexibility for AI era data challenges.
Ampere Advances in the Data Center with Jeff Wittich
TechArena host Allyson Klein chats with Ampere Chief Product Officer Jeff Wittich about his company’s progress in winning data center deployments, advances in performance and sustainability, and pushing the limits on core density.
Security in the AI Era with Fortinet’s Srija Allam and Julian Petersohn
TechArena host Allyson Klein chats with Fortinet security experts Srija Allam and Julian Petersohn about the expansive Fortinet solution portfolio and how the company is leaning into AI to help deliver the protection customers require.
Delivery of the CXL Vision with the CXL Consortium's Kurtis Bowman and Kurt Lender
TechArena host Allyson Klein sits down with the marketing co-chairs of the CXL Consortium at SC’23 to discuss the introduction of the new 3.1 spec, the emergence of true CXL 2.0 solutions, and what comes next from this disruptive standard that will re-define data center infrastructure.

Arm Targets an Ecosystem for Growing Data Center Deployments
I was delighted to catch up with Arm’s Eddie Ramirez at last week’s Open Compute Project Summit and learn about how he sees Arm growing its presence in the data center. I’ve been following Arm’s rise for years, first when responsible for tracking competitive technologies at Intel and later in delivery of some of my first TechArena conversations with Ampere. The value proposition for Arm platforms has always been intriguing given the architecture’s inherent advantages with energy efficiency. With power management becoming a much more urgent concern of operators with rising energy prices and more focus on corporate sustainability challenges, Arm has taken off with cloud service providers. Interestingly, earlier this year we also saw Arm gain great enterprise traction with announcements like Oracle database and SAP Hana support for the architecture.
When I spoke to Eddie, he emphasized the value of the architecture but then went further and pointed to the expansion of heterogeneous computing as an important opportunity for Arm. Arm makes a perfect option for companies looking to deploy accelerator rich platforms as well as a foundation for chiplet configurations offering integrated acceleration, and Eddie noted that he’s hearing about demand in this space and pointed to Meta’s OCP talk as an example.
“Meta said, ‘there isn't a one size fits all solution for AI. For some models, we're going to need a lot of memory. In other models, we're going to need more compute. The space of a one size fits all AI hardware is very difficult to try to crack.’ We love that because at Arm we can give partners the ability to design customized silicon for whatever use case they want to optimize around. These AI accelerators are a perfect example of a broader trend around heterogeneous computing, whether it's in a chip interface, if it's multiple chips on a board or multiple solutions in a rack.”
This observation from Arm is spot on and reflective of a broad trend in the industry around platform customization to address unique workload requirements. What this takes to pull off, however, is enabling an ecosystem of chip suppliers, foundries, and connected technologies to ensure platforms are delivered that work easily for the customer. Enter Arm Total Design, a first of its kind ecosystem that aims to accelerate collaborative design of IP, cores, and custom acceleration for bespoke silicon delivery. There are already thirteen vendors participating in the program with more expected in the months ahead.
As someone who has managed ecosystem programs for silicon innovation in the past, the news of this effort is incredibly interesting as it shows that Arm is serious about leading an entire industry forward based on its architecture and that the technology’s interest is real enough for vendors to be prioritizing engineering cycles for Arm-based innovation. I can’t want to see how this initiative reaps results in the months ahead with customer solution deployment and growing business opportunity for all involved.
Efficient and Secure Data Center Computing with AMD's Robert Hormuth and Prabhu Jayanna
TechArena host Allyson Klein sat down with AMD’s Robert Hormuth and Prabhu Jayanna at the Open Compute Summit to discuss the advancements AMD EPYC processors have delivered in performance, performance efficiency and security capability including AMD’s Infinity Guard technology.


The TechArena Compute Sustainability 2023 Report
TechArena spoke to over 20 industry experts from AMD, Ampere, Arm, Cloudflare, Etho Capital, Fermyon, HED, Intel, Koomey Research, Lemurian Labs, Meta, Microsoft, the Open Compute Project, Oracle, Schneider Electric, Solidigm, and Tenstorrent to publish this comprehensive report on the state of compute sustainability and how organizations should align data center planning and oversight with corporate social responsibility objectives. If you manage an IT organization or oversee data center infrastructure, software, or building management, this report offers practical value for your organization.