
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.




















TechArena Data Center Compute Efficiency Report 2024
Check out TechArena’s Data Center Compute Efficiency Report 2024 to discover how AI-driven innovation is reshaping data centers, reducing power consumption, and driving efficient compute solutions.

Scaling Innovation: How MIPS Balances Performance with Flexibility in a Data-Driven World
MIPS CTO Durgesh Srivastava shares insights on AI, data centers, automotive edge, and how MIPS is leveraging RISC-V to drive efficient, flexible computing solutions.

.webp)
OVHcloud Carves Out Unique European Space in Global Cloud Market
Jeniece Wronowski and I recently got the chance to sit down with Gregory Lebourg of OVHcloud, a major European cloud provider that’s been making significant strides in the global cloud market. With a focus on sustainability, data sovereignty, and competitive pricing, OVHcloud is challenging carving out a space that’s distinctly European. Our conversation delved into OVHcloud’s unique approach, their mission, and the trends they see shaping the future of cloud computing.
One of the first things that Gregory emphasized was OVH’s identity as a European service provider. While the cloud market is dominated by American and Chinese giants, OVHcloud stands out as a provider deeply rooted on the continent, adhering to European standards and business practices. This isn't just about where they’re based, but about how they operate. Data sovereignty is at the core of their operations, and OVHcloud ensures that customer data remains protected under European regulations, providing a significant advantage for businesses looking to avoid the complexities of non-EU data jurisdiction.
Gregory leads OVH’s sustainability practices, and in terms of environmental impact, OVHcloud is setting a very high bar. They’ve adopted a circular economy approach, focusing on minimizing waste and optimizing resource efficiency across everything they do. In our chat, Gregory shared that OVH data centers are equipped with custom water-cooling systems that reduce energy consumption by up to 50% compared to traditional air-cooling methods. This innovative approach has earned them an impressive PUE (Power Usage Effectiveness) rating of around 1.1 across most of their facilities, which is significantly better than industry averages. But that’s not all. They also use refurbished servers, which helps them keep costs low while reducing their carbon footprint. OVHcloud’s data centers operate on a massive scale, with more than 400,000 servers across 33 data centers globally. Despite this scale, they’ve managed to maintain competitive pricing without compromising on performance, a feat they attribute to their sustainability practices and vertically integrated supply chain.
We also had a chance to discuss pricing with Gregory, and it became clear that OVHcloud’s commitment to affordability is about more than just competing with other cloud giants — it’s part of their mission to democratize cloud access. By controlling their supply chain and building their servers in-house, they’re able to offer services at 20%-50% lower costs than the major competitors. This cost advantage has been crucial in helping small and medium-sized businesses access high-performance cloud services that might otherwise be out of reach.
One area where OVHcloud is particularly focused is in supporting multi-cloud strategies. Businesses are increasingly looking for flexibility in their cloud environments, and OVHcloud has responded by offering a range of services that can integrate seamlessly with other providers. This approach provides customers with more choices and enables them to build cloud architectures that suit their unique needs.
In today’s digital landscape, data security and privacy are critical concerns. OVHcloud takes a strong stance on data sovereignty, a major selling point for European customers wary of foreign jurisdiction over their data. They’ve also aligned their services with GDPR (General Data Protection Regulation) requirements, which gives customers the peace of mind that their data is protected according to some of the strictest standards in the world.
During our chat, Gregory underscored their commitment to transparency and compliance. They’re actively involved in initiatives like GAIA-X, which aims to create a federated and secure data infrastructure for Europe. This aligns with OVHcloud’s long-term vision of building a robust digital ecosystem in Europe that champions trust and user control over data.
When it comes to future technologies, Gregory shared that OVH is keeping its eyes on the horizon. They’re particularly interested in quantum computing and AI, areas they believe will transform the cloud landscape in the coming decade. Their partnership with the French government on the Plan Quantum initiative exemplifies their proactive approach to these technologies. As Gregory sees it, quantum computing holds the potential to revolutionize data processing and encryption, making it a game-changer for sectors like finance, healthcare, and defense. Meanwhile, OVH is investing in AI-driven tools that will enhance cloud services, offering more intelligent insights and automation options for customers.
So what’s the TechArena take? After our conversation, I walked away with a sense that OVHcloud is setting a very high standard for innovative cloud services, designed for their market and aimed at delivery with sustainability in mind. Services are high-performance, affordable, and sustainable, reflecting European customer priorities. Their commitment to data sovereignty is particularly timely, as businesses are becoming increasingly pressured to manage these aspects to keep aligned with government regulations. OVHcloud’s approach is refreshing in a market dominated by a few powerful players. For businesses in Europe and beyond, OVHcloud is proving to be a compelling alternative to the usual suspects, and I’m excited to see how they continue to evolve in the years to come.
Listen to the full conversation with OVHcloud here.

CircleB: Optimizing Data Centers for AI Workloads
Tune in as Jason Maselino of Circle B discusses the role of Open Compute Project in revolutionizing data centers with energy-efficient solutions, modular designs, and AI-ready infrastructure.

Exploring Aerospace Innovation with Airbus Acubed's Arne Stoschek
I recently had the pleasure of hosting Arne Stoschek, VP of AI and Autonomy at Acubed by Airbus, In the Arena. If you’re not familiar with Acubed, it’s the innovation hub of Airbus based in Silicon Valley, where they’re tackling the big questions of tomorrow’s aerospace industry. Arne and his team are at the forefront of pioneering advancements in autonomous flight and digital design tools. Our conversation gave a fascinating glimpse into the future of aerospace.
The Vision Behind Acubed
Arne shared Acubed’s mission to push the boundaries of what’s possible in aviation. While traditional aerospace projects can take decades to develop, Acubed operates at Silicon Valley speed, testing and iterating quickly to fast-track technology to maturity. It’s this ability to act nimbly that distinguishes Airbus from other aerospace companies working as a “startup within a big company” where Arne’s team has the creative freedom to explore without being bound by traditional corporate constraints.
When you consider the level of scrutiny that goes into design and manufacture of aircraft, this approach is fantastic from my perspective given the unfettered ability to dream big prior to facing integration of technology through regulatory hurdles. Arne shared that he focuses on harnessing the creativity and innovation found in tech while leveraging Airbus’s deep knowledge and resources within the aviation domain to produce results that are both innovative and practical for the arena in which they are targeted.
Autonomous Flight Advancement
One of the most exciting areas of Acubed’s work is in advancement of autonomous flight, something that at rudimentary level has existed for some time in aircrafts. Arne explained that Acubed is building advanced autonomous systems that can operate safely and efficiently alongside human pilots with an ultimate goal to reduce pilot workload and increase safety, particularly in urban air mobility (UAM) scenarios.
When it comes to autonomous vehicles, many of us might think first of self-driving cars. However, Arne believes the impact of advancement in autonomous flight could be even more profound. He envisions a future where fleets of autonomous aircraft could relieve urban congestion by transporting people and goods in ways we’ve only seen in sci-fi movies. Arne pointed out that Acubed’s technology is already proving itself in smaller pilot projects, which is a huge step toward making advanced autonomous flight a reality.
Digital Design Tools: The Key to Faster Innovation
Arne shared how digital design tools are transforming the aerospace industry. Traditionally, aircraft design is a painstakingly slow process, but Acubed is leveraging digital twins and other cutting-edge technologies to speed things up. These tools allow his team to create virtual models of their projects, test them in simulated environments, and identify potential issues long before a physical prototype is built.
Arne believes these digital tools will be crucial for the future of aerospace, as they enable rapid iteration and refinement. By incorporating real-world data into these simulations, Acubed can make better, faster decisions that ultimately result in safer and more efficient aircraft.
So what’s the TechArena take? Listening to Arne, it was hard not to get swept up in the excitement of Acubed’s work. They’re tackling some of the most complex and ambitious projects in aerospace, with a clear focus on sustainability, safety, and efficiency. What stood out to me most was Airbus’ approach to innovation — bold, forward-thinking, and unafraid to challenge the status quo. As someone who’s watched the tech industry evolve over the years, I’m always thrilled to see groups like Acubed bringing that same spirit of innovation to other sectors. Arne and his team are not just imagining the future; they’re building it, and I can’t wait to see where they’ll take us next.
To learn more check out our interview with Arne.

5 Fast Facts with Flex’s Rob Campbell
I recently caught up with Rob Campbell at Flex to learn more about how power and cooling technology choice helps yield improved efficiency to solution delivery in the market. As an advanced, end-to-end global manufacturer, Flex offers
the data center industry a unique combination of manufacturing, products, and
lifecycle services focused on data center IT and power infrastructure.
Rob is Flex’s President of Communications, Enterprise & Cloud. He oversees the team that supports leading cloud, data center operators and communication solutions providers to fuel the expansion of next-generation AI data centers, enterprises and communication networks. In the data center space, this includes hyperscalers, tier-two operators, colocation companies, and the solution providers that support them.
ALLYSON: Rob, thank you for being here today. Flex engages with some of the world’s largest cloud providers to deliver foundational technology to fuel the digital services we all rely on. Why is this moment so unique in hyperscale buildout?
ROB: The proliferation of artificial intelligence (AI) has broken the typical model for data center design and operations, and the industry faces a number of challenges around power, heat, and scale.
There’s increased IT complexity in the data center core and major power challenges at every level of the data center, and even out into the grid. Whether a cloud service provider is upgrading an existing data center or building a new one, there is a need to think about compute capabilities along with the entire power envelope of the data center. These dynamics are driving the evolution towards integrated systems and solutions.
Since every data center has different requirements depending on the mix of applications, size, and a variety of other factors, there is no one-size fits all solution. This means that the largest companies require customization in the various products and services that are part of a vertically integrated solution. At the same time, data center operators want more plug-and-play like deployments for speed and simplicity.
Finally, demand has been consistently high, unlike the normal variability we see in other industries. And companies have compressed timelines to deliver everything from new processors to greenfield data centers.
There are a lot of dynamics at play, and Flex is well positioned to support the industry to turn challenges into opportunities.
ALLYSON: When you consider the size of investment for greenfield data centers, the challenges in grid availability for greenfield projects, and the complexity of brownfield upgrades, how does a power and cooling partner like Flex work with customers to ensure the scale and speed of solutions to get data centers powered up swiftly and reliably?
ROB: A lot of companies are trying to support accelerated timelines for AI technology and data center expansion. They may have great technology, but they often lack the ability to deliver at the scale needed to relieve the pressure on these data center operators.
What makes Flex stand apart is the fact that we offer a portfolio of data center IT and power solutions combined with advanced manufacturing services across the product lifecycle for servers, storage, vertically integrated racks, and power products coupled with cooling at the board, rack and facility levels. We deliver scale and speed so companies can execute their ambitious AI and data center strategies and accelerated timelines.
We deliver a number of embedded and critical power products, but let’s use the example of a power pod from Anord Mardix, a Flex company. These power pods enable the rapid deployment of power capacity, which could be in a greenfield data center or to upgrade power capacity in brownfield data centers.
Our team designs, builds, tests, delivers, and commissions these modular, vertically integrated pods with everything needed to connect to the grid. We’re able to deliver 84% reduction in on-site man hours during installation phase and 75% reduction in onsite assembly and testing. This saves a lot of time and money. For brownfield data centers, you can drop a pod onto the site and increase power capacity almost overnight. For greenfield projects facing a shortage of construction workers, this solution eliminates that headache, among others.
ALLYSON: The metrics of power from platform to rack to data center are changing dramatically with the growth of AI server cluster deployments. How does this change the fundamentals of what you deliver to the market?
ROB: The rapid adoption of AI servers, primarily by hyperscale data centers, requires a different approach to how you think about power at the server, the rack, and the entire data center.
We have customers deploying 30kW racks today, and that will need to double to over 60kW in the near term and exceed 100kW in the next several years. This means we have to think about the rack as an integrated system where we consider factors such as server power density, rack power, and rack cooling. This means that data center operators are looking for partners that have the capabilities to design and manufacture a complete AI server cluster and deploy it at scale worldwide.
Our fundamental value is the combination of power products with advanced manufacturing and services across the product lifecycle, delivered on a global scale.
We understand the long-term trends and challenges and continue to drive R&D and innovation to help customers stay ahead of the challenges. We engage data center operators and vendors very early in their product development lifecycle, often years ahead of an official launch. This includes custom power modules designed for GPUs, CPUs, FPGAs and SoCs, as well as data center racks, power shelves, power pods and a host of other data center infrastructure solutions. We’re then able to deliver these innovations at a scale and speed that is unique and valuable to our customers.
Technically speaking, AI creates multiple ripples starting with the chip and cascading across the data center and ultimately the grid. Power consumption, rack density, heat generation, energy loss and grid disturbances are a few of the challenges.
Flex is focused on improving power efficiency and distribution, architecture optimization, and cooling. This includes ongoing architectural advances to place point-of-load DC/DC converters as close to the power source as possible for greater power accuracy, efficiency and latency. For most applications, the traditional lateral placement of a converter alongside the processor on the printed circuit board (PCB) is effective, and forced air cooling works well with this design.
AI is different. These AI processors and DC/DC converters need to be as close as possible to avoid static and dynamic voltage drops across power rail connections. A vertical power delivery (VPD) module, as the name suggests, places the DC/DC vertically underneath the processor on the bottom side of the PCB for optimum power transfer and minimum power delivery network losses. This design also aligns well with direct-to-chip liquid cooling with a cold plate alongside the DC/DC converter and the processor.
We’re designing power shelves to stay ahead of expected 125kW and 1MW rack requirements. We’re also looking at the use of different voltages and more concentrated AI clusters to better manage power demands.
Additionally, high-speed switching with GPUs can create disturbances and transients that affect power quality. This makes it necessary to manage these impacts carefully to avoid further inefficiencies. We recently announced Flex’s Capacitive Energy Storage System designed with hyperscale partners to balance peak power and protect the grid from line disturbances during AI training and inference periods. The solution includes state-of-the art capacitor technology from Musashi Energy Solutions.
These are just a few examples of the innovation we’re driving in collaboration with customers and the ecosystem.
ALLYSON: Cooling technologies are critical within this context as well. How do you see the change to liquid cooling, and how does Flex plan to play a role in this arena?
ROB: Liquid cooling has multiple drivers that are supporting the adoption and growth of liquid cooling technologies in the data center. For example, rising rack power densities have already exceeded the ability for traditional air cooling at the server and rack level, and are driving innovation in cooling technologies. Also, large data centers have seen marginal improvements in efficiency with the current cooling technology and are looking to innovate and re-architect data center designs to meet their sustainability goals.
Flex has over a decade of experience in liquid cooling, and we continue to invest in liquid cooling technologies to provide our customers with innovative power and cooling solutions that support their large-scale deployments of AI server clusters. Liquid cooling is a critical part of the Flex strategy to be the partner of choice for our data center customers, and complements our existing portfolio of critical power, embedded power, mechanicals, and IT infrastructure products and services.
ALLYSON: Where can our readers find out more about Flex solutions in this space and engage the Flex team to learn more?
ROB: Visit our website at www.flex.com and if you’re attending the OCP Global Summit, stop by booth A11.

You Can’t Have It All: Managing Expectations in Complex Projects
“You know, when I fumbled and lost the West High game, it took a whole roll of LifeSavers to make me feel better.”
“You got a whole roll?”
“Here, there’ll be other games, kiddo.”
-Commercial from 1976
A lesson in planning: Ineffectiveness is habitual.
There. It’s in print. Especially as veterans of the technology community, we feel that we can escape the ravages of ennui, entropy, etc., because we took the hard road, and it steeled us for non-failure. Our plans are exceptional, and setting those clear goals and expectations will magically coalesce the team to whip whatever schedule or project into a shining example of efficiency and excellence. (Leading to exasperation and excuses.
Several current high-tech examples come to mind, but the personal is always the best. So we offer the following lesson, still ongoing.
Yer’ Humble Author (YHA) was reminded of the rules of recently, specifically during a recent discussion with local county government officials about a complex taxpayer-funded project in our purview* that was about to tip over the top of budgetary expectations. The conversations were sanguine on at least one end, mostly because some failure is usually an option in certain circles. But it prompted several long-ago planning and organizational lessons to come to mind.
In a couple of those conversations, an old technology saying was presented. When faced with the triumvirate of schedule, features, and budget, you-the-management may pick any two. That doesn’t mean you’ll get both, but you clearly won’t get the three. Pressure comes in all shapes and sizes. And while it’s supposedly good for carbon and silica, it’s not so much for plans. Even those of us who are pretty good at screaming into the buffeting winds are eventually sandblasted to submission. Low expectations aside, it can be hard to accept that you can’t keep sliding the levers and hope nobody notices the migrating goalposts.
One opinion (the correct one) would point back to clear goals and expectations: it will cost this much and arrive on this date.
Said project still looks very good for schedule (two months left!). And the entire team is currently very focused on understanding the trade-offs that are pushing the budget and limiting any new unnecessary expectations that might occur. We’re all sure that it’ll be a non-contentious product introduction that the community will mostly appreciate. This leads to another habit good planners embrace.
YHA’s favorite direct manager (yes, they’re all ranked, and most of them know where they land on the spreadsheet) was very fond of building his organization around a simple methodology: We Suck Less. Like hikers encountering ursine denizens, sometimes it’s okay to just be a little faster. While this particular project looks to be taking 2.5% more than hoped, any someone could cast within the territorial boundaries of said government budget and find four or five similar projects that freewheeled one of the three and are currently blowing the other two. The comparisons will still create eventual kudos that will further create favorable memories when we’re done.
It’s still about expectations. Even while reminding those in charge that We Suck Less, it’s useful to gently remind the charges that We Still Suck. As said above, permission to spend above budget isn’t unlimited. So those of you in planning, please remember, pick your two and be firm in your fluidity. Your products and your customers will thank you for it.
*(When one “retires” a bit too early, one ends up volunteering skills taught in the brutal territory of high tech to help the less experientially-fortunate, which will be a common feature in this space. It’s okay to be bad at retirement sometimes.)

Don’t Skip Leg Day
Weightlifting, like many sports, has a distinct culture that I started learning about when one of my sons started working towards maxing out his scores for a military PT test. He was oriented entirely around one objective and set of exercises until the test was updated. That military branch realized they needed to test for proficiency in movements more typical in the field. At this point, skipping leg day was not an option since chicken legs aren’t efficient or effective at transporting a payload amounting to 180 lbs of sheer upper body muscle.
Computing services have also tripped over the same over-engineering of a single element, because there’s no time, no cash or no clarity on what commercially viable uses a technology or system will have. It is inevitable that if you get enough processing power to solve a problem, your next challenge will be keeping that processor from stalling because – like a no leg day curlbro with chicken legs – the transport layer is too tiny to move the payload except at a snail’s pace. Recently a friend at one of the hyperscaler cloud providers told me “we have demonstrated we can multiply numbers effectively with AI GPUs. Now it’s a mere matter of keeping the beast fed.”
Having had the opportunity to work on 3DXP memory technology that would sustain a data lake the depth of Lake Tahoe and was inhibited by its connection to the rest of the world being the width of a drinking straw – I do wonder who tames whom. Will the unique movement, uses, types and amounts of data that feed the AI beast transform the network? Or, given how much the network has clapped back at compelling but unsustainable business models (true cloud gaming, for example), perhaps I should wonder what the network will do to the AI beast.
AI requires enormous amounts of data to support model advancements. Omdia recently stated that by 2030 75% of all network application traffic will involve AI content generation, curation or processing. When I was running a “Visual Cloud” business in 2020, Cisco’s annual networking report made a near identical claim that video traffic represented 75%+ of all internet traffic. Despite the dominance of video, there were a number of network characteristics that video-based workloads have to work around to improve delivery of their payloads. The hardware at the end points processing these video payloads had a nearly inconsequential role in the service – the network in between enabled or eradicated video business economics.
When it comes to AI bandwidth “more is more” – yet anyone who tells you bandwidth is cheap and plentiful is, in the words of the Dread Pirate Roberts – selling something. AI imposes the requirement for near real-time responses. Network responsiveness correlates to distances – in the datacenters, between data centers and on the internet. AI requires lossless delivery networks. In the 1980’s “Sneakernet” was coined because interoperability and lossless communications were safer if transporting data on physical discs between compute networks. In the 2020’s, “command streaming” seemed like the best way to make cloud gaming economically feasible, yet GPUs couldn’t reliably count on a perfect, lossless transmission and often displayed garbage due to the occasional packet drop.
If this isn’t a tall enough order, the network must be zero-trust, since the data used in AI is often sensitive, while sustaining extensive east-west traffic exchanges. All that, plus adhere to a broad industry standard with a diversity of suppliers, while reaping the benefits of high volume manufacturing economics.
I would love your perspectives here:
-Will AI force the industry to get serious about network “leg day,” accepting that networks are a foundation for AI infrastructure as much as legs are a foundation for a fully optimized human body?
-Or, similar to the infamous “penguin walk” after leg day, are the past 30 years of network architecture buildout such a disincentive to change that AI infrastructure will have to adapt to the network?

Why My Wife and I Decided to Write a Book Using ChatGPT
Toward the end of 2022, ripples of ChatGPT-generated buzz began to propagate through my network of technical colleagues. The whisper was, “This is new. This is something.” I dutifully set myself up with a ChatGPT account, and like almost everyone who tries modern AI for the first time, my head began to fill with questions and concerns. I was also impressed.
It is true that there are future existential threats that humanity will need to navigate, and which I will touch on below, but my existential fears were more immediate: I had recently published my third book on AI and I began to wonder, “Was that my last book? Has AI overtaken humanity in the realm of creative writing, and nudged me off the top of the food chain?”
I shared my concerns with my wife, Theresa Hart, who is an entrepreneur and attorney, but rather than fret, we hatched a plan. We began work on a new AI book, to be written entirely by ChatGPT and illustrated by an AI service called Night Café. Thus, “ChatGPT, An AI Expert, and a Lawyer Walk Into a Bar…The History of Creativity and Communication” was born. The rules were simple: We could enter any prompt we liked, but we could not directly edit the resulting text.
Testing ChatGPT’s early capabilities
We explored the limits of that version of ChatGPT, we asked dumb questions, we asked evil questions, we asked ChatGPT to write jokes and to entertain us. What we found was a tool that went far beyond any previous technology that had ever existed in the areas of language creation, and in many cases we observed behavior that mimicked creativity. We also found that ChatGPT had limitations that prevented it from always getting facts right, and we noted that it could not form an opinion or argue a point for the purposes of making a case or telling a story.
In short, ChatGPT was a powerful tool for augmenting humans, but not yet one that could replace them. I began to think of Generative AI (“GenAI”) as more of a colleague than as a competitor. Phew!
Fast forward almost two years…We have seen explosive growth in the development and propagation of new GenAI models: multiple versions of GPT and ChatGPT, Claude, Gemini, and Llama, just to name a few. Of particular note are the multimodal GenAI models that can generate images, video, and audio from text, and vice versa, because these technologies have been used by criminals to scam companies and individuals out of millions of dollars and they have been used to manipulate the public with false imagery.
These developments are generating excitement, but also reigniting our original existential fears. Will my job be displaced by AI? Will I be scammed by an AI? Will AI take over the world? What legislation should be put in place to protect human society from AI?
This last question is particularly timely: Governor Gavin Newsom of California just vetoed some broad legislation aimed at regulating AI and making companies developing AI accountable for some misuse of their tools, and requiring specific features to be incorporated into AI systems by developers.
I can see on social media that the majority of my high-tech colleagues are celebrating this veto as a victory in the name of speed to market, innovation, and fewer regulatory hurdles to develop products. I personally would assert that it is fortunate that this legislation did not pass because it arose out of fearful, somewhat uninformed thought processes and was not likely to result in beneficial, meaningful improvements in the way that we develop and deploy AI.
Thoughtful AI legislation requires discussion across disciplines
I also know for a fact that leaders in a variety of disciplines are strongly in favor of thoughtful legislation that will help ensure protections for consumers and workers without putting unrealistic expectations on the folks who are developing new technology. I was very fortunate to participate in a private, round table discussion with a dozen well-informed and connected leaders from Silicon Valley, Texas and Washington, DC, covering areas of expertise as broad as quantum computing, robotics, healthcare, governance and policy, venture capital, and international tech journalism. Frankly, it was such a who’s-who, that I had to pinch myself that I was included in the cast.
What I experienced was a balanced discussion coming from a diverse group of perspectives, all converging on a few key ideas: “bad” regulation will hurt innovation and potentially negatively impact national security; “good” regulation is needed to ensure transparency about the dangers and limitations of the technology that is being developed so rapidly right now; concerns about job loss in some sectors are real, so incentives for upskilling employees as automation of their jobs increases will be necessary, but using regulation to slow down deployment of new automation technology is not a good idea.
Bad regulation in this context tended to be specific requirements on what an AI system could do, how it was developed, requirements to expose the details of data used to train AI, and importantly, direct accountability for misuse of tools by third-party evildoers.
Good regulation tended to include labeling, so that users know they are interacting with AI or experiencing AI-generated content, increased transparency around the potential risks and shortcomings of AI output, and expansion of existing rules to ensure that using AI to scam or manipulate people is punished vigorously.
I was impressed by the overall sentiment from this group of technical and tech-adjacent leaders, that their role is not to resist regulation at all cost, but to provide informed input to lawmakers that will ensure that we end up with sensible regulation that is good for society as a whole.
AI tool developers: Inform the public, lawmakers about capabilities and risks
Getting back to the original subject of this article, it is crucial that the people who are developing these tools, and those who are using these tools on a daily basis to create value, continue to inform the public and lawmakers about what the real capabilities of the latest GenAI systems are, where there are known risks and design flaws, and what we might realistically need to prepare for in the next one to two years. Beyond this timeframe, the future is not knowable, so we also need to maintain some flexibility in our approach to AI regulation. I hope that the discussion I participated in, which was intended to generate real inputs to lawmakers, is being mirrored by many others in tech who can really speak to the strengths, weaknesses and evolving abilities of modern GenAI.
One of the most distinguished members of the group pointed out that it is hard to fix law once it is in place. He cited the HIPAA law that was designed as an initial attempt to protect healthcare patient data privacy in anticipation of an increasingly connected world. The law was written in 1996, before the Internet, before mobile phones, before social media, and is now painfully outdated, and yet, despite these shortcomings it has not really changed since 1996. So we need to be flexible in our approach to AI legislation.
As I reflect on all of this, I wonder if perhaps it’s time for Theresa Hart and me to get together with ChatGPT to write another book. This one will be about AI safety, societal impact, and the quest to create beneficial AI legislation. Maybe it will be called, “ChatGPT, an AI Expert, and a Lawyer Walk into Congress…”

A Primer on Functional Safety in Auto
Deep thoughts - if two self-driving cars get into an accident… who would be at fault? The automotive industry’s case for functional safety.
Hopefully this is a somewhat tongue-in-cheek way to grab your attention. To be clear, self-driving cars aren’t the primary driver of automotive functional safety (FuSa). Automotive functional safety has been an area of focus since 2011, when the Automotive Safety Integrity Level (ASIL) based upon the ISO 26262 specification was first introduced.
However, the awareness of cars with increased levels of autonomy is indeed driving an even greater focus on FuSa. Understandably so, as increasing levels of autonomy also lead to significant increases in the amount of semiconductors employed in the vehicle. In turn, these semiconductors have greater levels of physical control of the vehicle. The increase in semiconductors in the vehicle also drives explosive levels of growth in overall system complexity.
As an illustration of the complexity associated with today’s car, a high-end vehicle contains over 300 million lines of software. This is expected to grow to 1 billion by the end of this decade. With these levels of complexity, there is a good reason why there’s such a keen focus on FuSa.
Functional safety, as it’s defined, is the discipline of implementing safety measures to prevent or reduce the risk of harm caused by a vehicle’s electrical or electronic systems failing or behaving unexpectedly.
There are a lot of key components to unpack from what appears to be a fairly innocuous statement.
- Implementing safety measures to prevent or reduce risk: Safety measures typically translate into additional hardware overhead that needs to be added when a semiconductor or system is being designed. This overhead needs to accomplish several key things:
- Know what “normal operation” looks like & detect when a system is not acting “normally”
- Once abnormal behavior has been detected, either
- Provide a corrective action that restores the failed system to “normal operation”
or - Provide a flag or warning from the failed system that will allow the vehicle to be able to take the appropriate action in response to the flagged departure from “normal operation” – depending on the severity of the failure, the right response from the vehicle could from “take no action” (one pixel on a display is not working) to cripple the vehicle (something affecting vehicle safety has failed) pulling it over to the side of the road.
- Provide a corrective action that restores the failed system to “normal operation”
- Risk of harm caused by a vehicle’s electrical or electronic systems: ASIL, which is measured by the letters A,B,C, & D where each progressive letter of the alphabet leads to increasing levels of scrutiny. The elements that are typically considered in establishing the required safety level (A vs. D for example) for a given component (i.e. Antilock Braking System, Air Bag, Lane Keeping, Headlight, etc.) includes the following:
- Hazard analysis
- What could happen to the vehicle in the case of a failure?
- Risk analysis
- How likely is a failure going to happen?
- How severe will the impact be if a failure happens?
- Hazard analysis
The ASIL is then determined by:
- The failure rate - how likely the failure may occur?
- What is the level of tolerance in the system to undetected failures
While an argument might be to ensure that undetected failures never occur, higher levels of ASIL typically come with significantly higher costs due to the additional hardware overhead required to detect failures. So if the inherent failure rate of a component is very low and the impact of an undetected failure is quite limited, then specifying an ASIL D for that component will likely result in a loss-leader, especially so in the cost-conscious automotive industry.
As an extreme example, ASIL D solutions can be based upon triple mode redundancy (TMR). TMR employs three identical copies of the same hardware with additional hardware that can detect if the output of the three copies match. When they don’t match, typically one of the three outputs doesn’t match the other two. The checking hardware will flag that there was an error but rely on the two matching outputs for the correct value. As you can begin to see, the costs of achieving ASIL D certification can get expensive.
- Systems failing or behaving unexpectedly: Another important point that can be easily overlooked in this statement. While this was just alluded to, which is the ASILs correlate to different detected failure rates, ASIL does not specify the absence of a failure. It is anticipated that failures will indeed naturally occur in a system for a number of reasons.
While functional safety is not primarily focused on preventing a random failure, it is, however, the responsibility of the system, to “always” be able to recognize when the system is failing or behaving unexpectedly.
The term FIT (Failure in Time) is the term used in FuSa to specify how many failures - i.e. missing an event when a component isn’t working properly over a period of time that is specified in the ISO 26262 spec and reflected in the ASIL rating. ASIL D, with a rating of 10 FITs implies that only 10 failures are acceptable in 1 Billion Hours of operation. That is equal to 10 failures in roughly 114,000 years or 1 failure in just over 11,400 years. To the best of my knowledge, there are no cars on the road that have reached that age - yet. In other words, this specification is very stringent.
It’s also key to note that I have been trying to use the word “component” carefully, because while ASIL certification is specified at the semiconductor device level, it is also measured and specified at the system level – which takes into account all the devices associated with a given system / component in the vehicle. This implies that while an ASIL D FIT rate of 10 is required at the system level, this budget of 10 will be distributed across the different semiconductor devices that make up the system. This implies that the FIT rate at the device level must be some percentage of that 10 – further increasing the complexity of designing a device targeting auto while still remaining profitable.
These insights into these stringent specifications should hopefully instill a sense of increased confidence that there is very significant scrutiny in the electronics systems in the automobile - with levels of scrutiny that are directly correlated to the impact of failure of a given system.
There are many different topics that could be discussed when looking at FuSa and it’s easy to go down a rabbit hole. To put the scale and importance of FuSa into perspective, an automotive OEM typically will have their own safety department with teams of engineers focused purely on FuSa. The same level of staffing also exists for the semiconductor manufacturer who is selling components into automotive applications. Both the OEM and semiconductor companies will require a “Safety Office” staffed with a “Safety Manager” and multiple safety engineers. This is also true for the Tier 1s.
Lastly, two more topics to cover – systematic fault coverage and random fault coverage.
Systematic fault coverage evaluates the design, test, verification, documentation, and other such processes to ensure that there are faults or errors that have been systematically introduced due to bad hygiene in the areas of design and test of the device. Systematic fault coverage also extends into the manner that software is developed both in the form of firmware as well as overall system software. Stringent processes and methodologies are called out in the ISO 26262 specification with correlated levels of scrutiny as dictated by the given ASIL.
The importance of addressing systematic fault coverage requirements cannot be overstated. Several years ago, the highly visible case of a vehicle that suffered from a faulty “stuck accelerator” was found to have not employed best practices in the development of the underlying software that was used to control the operation of the accelerator. Realizing that poor software development practices were at fault resulting in “spaghetti code,” the OEM quickly settled the case resulting in several combined financial settlements in excess of $2.5 B over 10 years ago.
Random fault coverage focuses on the random hardware failures which can occur unpredictably during the lifetime of a component. These failures can occur even if there have been no flaws in the development and manufacturing of the component. These failures typically are caused by cosmic neutron strikes or alpha particles from the package material. Here again, there are different ASILs that correspond to the rate at which these random failures go undetected. ASIL D specifies 10 FIT for the probabilistic metric for random hardware failures (PMHF).
ASIL D is a very difficult specification to achieve at the component level and so typically systems are designed using devices that have a lesser ASIL random fault coverage rating i.e. ASIL B. Through ASIL decomposition, which is a structured way of adding redundancy to the system, the requisite ASIL can be achieved. Random faults ultimately will be detected via the redundancy.
FuSa is a very complex topic of which I've barely scratched the surface. These rigid processes ensure that the vehicle is designed to stringent specifications to minimize the effect of the failure of a component. As mentioned, with an ever-increasing amount of complex systems taking over the control of the vehicle, the need for rigid safety processes can’t be overstated. Hopefully as you have been able to see in this blog, there is a lot of scrutiny and rigor in designing a system to achieve a given ASIL to hopefully avoid two self-driving cars from getting into an accident.
.webp)
Powering AI with ZincFive’s Sustainable Battery Solutions
Tod Higinbotham, COO of ZincFive, discusses the role of nickel-zinc batteries in supporting AI workloads, improving data center efficiency, and advancing sustainability in power infrastructure.

5 Fast Facts with Justin Murrill at AMD
I recently caught up with Justin Murrill at AMD to learn more about how processor innovation helps yield improved efficiency to data center workload delivery. AMD is delivering leading compute silicon with a broad offering of foundational CPU and acceleration technologies aimed at data center environments.
Justin is the AMD Director of Corporate Responsibility and is responsible for coordinating the company's sustainability strategy, goals and reporting.
ALLYSON: Justin, thank you for being here today. As you know, AI has fundamentally changed the requirements for computing in the data center. With estimates that >40% of all servers will be dedicated to AI by 2026, how is AMD seeing computing evolving across CPU, GPU, and FPGA?
JUSTIN: As AI continues to evolve rapidly, having a broad range of compute engines will be critical to scaling performance and efficiency. We see each of these different compute engines playing a unique role, particularly as AI workloads shift and as use models evolve. We also look to enable more on-device processing across the edge and end devices — further helping to drive efficiencies. Having our full range of processing engines allows customers to balance the competing demands for disparate performance levels, throughput, capacity, energy consumption, programmability and available space. Offering compute engines that address these needs while increasingly accommodating AI requirements is a critical differentiator for AMD.
ALLYSON: This increased compute demand is placing greater emphasis on compute efficiency. How does AMD integrate efficient design into roadmap planning, and what has this influenced in your architecture?
JUSTIN: The computing performance delivered per watt of energy consumed is a vital aspect of our business strategy. Our products’ cutting-edge chip architecture, design, and power management features have resulted in significant energy efficiency gains. AMD has a track record of setting long-term energy efficiency goals and incorporating them into engineering roadmaps for successful execution.
We have a bold goal to achieve a 30x improvement in energy efficiency for AMD processors and accelerators powering HPC and AI training by 2025—our “30x25 goal”.1 If all AI and HPC server nodes globally were to make similar gains to the AMD 30x25 goal, we estimate billions of kilowatt-hours of electricity could be saved in 2025, relative to baseline trends.2 Achieving the goal would also mean we would exceed the industry trendline for energy efficiency gains and reduce energy use per computation by up to 97% as compared to 2020. As of late 2023, we achieved a 13.5x improvement in energy efficiency from the 2020 baseline, using a configuration of four AMD Instinct MI300A APUs (4th Gen AMD EPYC™ CPU with AMD CDNA™ 3 Compute Units).3 Similarly, this kind of philosophy and process helped influence design choices across our “Zen” architectures for the AMD EPYC server CPU family—to develop a core infrastructure that balances performance, efficiency and density.
To embed energy efficiency goals into the design process, we collaborate closely with customers to understand their unique needs for performance, power targets, features and more. All this input is included in the design process, and teams have different stages in the process to check on the alignment with the end functionality that they are targeting.
One example of how AMD is addressing customer performance needs and configuration flexibility, while also advancing sustainability, is the modular architecture we pioneered with chiplets. Instead of one large monolithic chip, AMD engineers reconfigured the component IP building blocks using a flexible, scalable connectivity we designed known as Infinity Fabric. This laid the foundation for our Infinity Architecture, which enables us to configure multiple individual chiplets to scale compute cores in countless designs. Not only does this further optimize energy efficiency, but it also reduces environmental impacts in the wafer manufacturing process.
By breaking our designs up into smaller chiplets, we can get more chips per wafer, lowering the probability that a defect will land on any one chip. As a result, the number and yield percentage of “good” chips per wafer goes up, and the wasted cost, raw materials, energy, emissions, and water goes down. For example, producing 4th Gen AMD EPYC™ CPUs with up to 12 separate compute chiplets instead of one monolithic die saved approximately 132,000 metric tons of CO2e in 2023 through avoidance of wafers manufactured, 2.8 times more than the annual operational CO2e footprint of AMD in 2023.4
ALLYSON: With markets like the EU placing greater emphasis on embedded carbon and other sustainability metrics, how is AMD working with manufacturing partners to deliver transparency within your product offerings?
JUSTIN: We work with our Manufacturing Suppliers to advance environmental sustainability across a variety of metrics, including emissions related to AMD purchased goods and services (Scope 3 emissions). Aligned with guidance from the GHG Protocol, we directly survey manufacturing suppliers representing ~95% of our related supply chain spend and use the data to estimate and publicly report our related Scope 3 emissions.
We also set goals for our manufacturing suppliers and report our progress annually. Our 2025 public goals are for 100% of manufacturing suppliers to have their own public GHG reduction goal(s) and 80% to source renewable energy. Our latest report shows 84% of our Manufacturing Suppliers had public GHG goals and 71% source renewable energy.
Carbon emissions in our supply chain are primarily generated at silicon wafer manufacturing facilities. Most AMD wafers come from TSMC, which implemented more than 800 energy savings measures in 2023, saving approximately 92,960 MWh of energy and 46,000 metric tons of CO2e attributed to AMD wafer production. In September 2023, TSMC announced an accelerated renewable energy roadmap, increasing its 2030 target from 40% to 60% of the total energy supply, and pulling in its 100% renewable energy target from 2050 to 2040.
In the near term, the amount of renewable energy available in Taiwan and other regions in Asia is very limited. To help address this challenge, AMD is a founding member of the Semiconductor Climate Consortium and a sponsor of its Energy Collaborative working to accelerate renewable energy access in the Asia-Pacific region.
ALLYSON: How do you see AI actually influencing the delivery of efficient compute as a strategic tool for AMD innovation in the future?
JUSTIN: Energy efficiency has always been a key pillar of our design and ecosystem enablement approach, and we take a holistic view at the silicon, software and system level to get the most performance and functionality out of every watt consumed. The benefits are so much more impactful when hardware, software and systems can evolve in more relative lockstep, which requires deep technical collaborations.
We also embrace the scaling of efficiency impacts that AI can enable as it matures and proliferates – from helping assign compute resources more optimally to monitoring and diagnosing underperforming hardware. Some of the leading application vendors we collaborate with in electronic design, simulation and verification are developing AI-enabled tools to optimize system and cluster performance, automate and augment common routines, reduce waste and improve productivity.
ALLYSON: Where can our readers find out more about AMD solutions in this space and engage the AMD team to learn more?
JUSTIN:
- Explore the AMD 2023-24 Corporate Responsibility Report
- Learn more about how AMD is advancing data center sustainability here
- Get the details on AMD EPYC server CPU energy efficiency here
- Use the AMD TCO Greenhouse Gas Calculators – Bare Metal and Virtualization versions
1 Includes AMD high-performance CPU and GPU accelerators used for AI-training and high-performance computing in a 4-Accelerator, CPU-hosted configuration. Goal calculations are based on performance scores as measured by standard performance metrics (HPC: Linpack DGEMM kernel FLOPS with 4k matrix size; AI-training: lower precision training-focused floating-point math GEMM kernels such as FP16 or BF16 FLOPS operating on 4k matrices) divided by the rated power consumption of a representative accelerated compute node, including the CPU host + memory and 4 GPU accelerators.
2 “Data Center Sustainability,” AMD, https://www.amd.com/en/corporate/corporate-responsibility/data-center-sustainability.html (accessed May 15, 2024).
3 EPYC-030a: Calculation includes 1) base case kWhr use projections in 2025 conducted with Koomey Analytics based on available research and data that includes segment specific projected 2025 deployment volumes and data center power utilization effectiveness (PUE) including GPU HPC and machine learning (ML) installations and 2) AMD CPU and GPU node power consumptions incorporating segment-specific utilization (active vs. idle) percentages and multiplied by PUE to determine actual total energy use for calculation of the performance per Watt. 13.5x is calculated using the following formula: (base case HPC node kWhr use projection in 2025 * AMD 2023 perf/Watt improvement using DGEMM and TEC +Base case ML node kWhr use projection in 2025 *AMD 2023 perf/Watt improvement using ML math and TEC) /(2020 perf/Watt * Base case projected kWhr usage in 2025). For more information, www.amd.com/en/corporate-responsibility/data-center-sustainability
4 AMD estimation based on defect density (defects per unit area on the wafer), chip area and n-factor (manufacturing complexity factor) to estimate the number of wafers avoided in one year. Yield = (1 + A*D0)^(-n) where A is the chip area, D0 is the defect density and n is the complexity factor. The area is known from our design, D0 is known based our manufacturing yield data, and n is a number provided by a foundry partner for a given technology. The calculations are not meant to be precise, since chip design can have a large influence on yield, but it estimates the area impact on yield. The carbon emission estimates of 132,064 mtCO2e were calculated using the estimated number of 5 nm wafers saved in one year, based on the TechInsights’ Semiconductor Manufacturing Carbon Model. Comparison to AMD corporate footprint is based on AMD reported scope 1 and 2 market-based GHG emissions in 2023: 46,606 mtCO2e. Water savings estimates of 1,110 million liters were calculated using the estimated number of 5 nm wafers saved in one year times the amount of water use per 300mm wafer mask layer times the average number of mask layers. Comparison to AMD corporate water use is based on AMD 2023 reported value of 225 million liters.

Sustainability in Cloud Services with OVHcloud's Grégory Lebourg
During this episode of Data Insights sponsored by Solidigm, Grégory Lebourg – Global Environmental Director at OVHcloud – discusses how companies can meet their environmental goals effectively.

5 Fast Facts with Solidigm’s Dave Sierra
As we prepare to roll out the TechArena 2024 Data Center Efficiency Report, I was honored to sit down with Solidigm’s Dave Sierra to learn more about how storage media innovation will help yield improved efficiency to solution delivery in the market.
Solidigm has been featured extensively on TechArena and is a leading supplier of storage media aimed at data center-to-edge environments. Dave is part of Solidigm’s Data Center Solutions Marketing team and is responsible for proving and conveying the value of their storage products.
ALLYSON: Why is compute efficiency becoming so critical in 2024? Is this just about AI, or are other factors like the slowing of Moore’s Law coming into play?
DAVE: As a former Intel-er, I greatly appreciate the nearly 60-year run of Gordon Moore’s Law, but technology, physics, and economic limitations are bringing that era to a close. What isn’t slowing is the pace of compute innovation and performance improvement, largely driven by the economics of the AI opportunity. While GPUs and other compute elements are indeed becoming more energy efficient, it comes at the price of huge overall increases in raw power needs. Securing and allocating more and more power for compute resources is becoming the critical factor in efficient AI data center design.
ALLYSON: How is storage part of the energy efficiency solution, and why is the move to SSDs a critical part of any IT strategy?
DAVE: You can’t talk about energy efficiency without talking about AI, and vice versa. The mind-boggling energy needs of today’s GPU infrastructure and the corresponding difficulty in sourcing power rightly grabs headlines. But storage is an underappreciated component of a modern data center’s power consumption, with several estimates pegging it at 30-35% of overall DC IT power. Solutions designed with performant, power efficient, high-capacity SSDs enable you to store more data in less space versus legacy storage options. Designing for fewer drives in a solution is more energy efficient, requires fewer servers, and reduces overall cooling infrastructure needs.
ALLYSON: Solidigm is a leader in delivering storage media to the market with decades of experience working from data center to edge. How have you differentiated your solutions from an efficiency perspective?
DAVE: As a company, Solidigm’s sole focus is delivering reliable and innovative storage solutions from the data center core to the edge. We paved the way for the industry’s ongoing transition to more space and energy efficient EDSFF (Enterprise and Data Center Standard Form Factor) SSDs with our first-to-market ‘Ruler’ design in 2019. Today, our ultra-high-density Quad Level Cell (QLC) SSDs allow infrastructure efficiency leaders to consolidate less efficient, less reliable storage designs onto a modern, high capacity, power and space efficient infrastructure. We have a roadmap of innovations that will continue to deliver improved core-to-edge efficiency value in the coming years.
ALLYSON: What do you see as the lifecycle of storage media, and is it changing?
DAVE: When SSDs first entered the market, there was significant industry concern around drive wear out – a limited number of times you could reliably move data in and out of a NAND cell. With improved technology and algorithms, those concerns are mostly a thing of the past, but today’s high-density SSDs are further improving the narrative around SSD endurance. Consider the 61.44TB Solidigm™ D5-P5336 SSD, with a lifetime petabytes written (PBW) rating of 65.2 petabytes. A typical Content Delivery Network (CDN) workload might take 14 years to write that much data to a single drive. ‘Your mileage may vary’, but you can model your own workload characteristics against Solidigm’s products using our endurance estimator at https://estimator.solidigm.com/ssdendurance/index.htm.
ALLYSON: Where can readers find out more about Solidigm products and connect with the Solidigm team?
DAVE: A great place to learn more about our power and space efficient storage is at https://www.solidigm.com/solutions/artificial-intelligence.html. Other ways to connect:

AI and Autonomous Advancement at Airbus
Join Arne Stoschek, VP of AI and Autonomy at Airbus Acubed, as he discusses the role of AI in aviation, the future of autonomous flight, and innovations shaping the industry at Airbus.

5 Compute Efficiency Takes with WEKA President Jonathan Martin
As TechArena prepares to roll out the 2024 Compute Sustainability Report, I was privileged to sit down with WEKA President Jonathan Martin to discuss how the right data foundation is critical to make GPUs more efficient and improve the sustainability and performance of AI applications and workloads.
WEKA's leading AI-native data platform software solution, the WEKA Data Platform, was purpose-built to deliver the performance and scale required for enterprise AI training and inference workloads across distributed edge, core, and cloud environments.
Jonathan, WEKA’s President, is responsible for the company’s global go-to-market (GTM) functions and operations, which include sales, marketing, strategic partnerships, and customer success.
ALLYSON: Jonathan, thank you for being here today. It used to be that data storage was an arena not exactly known for innovation. With organizations utilizing multiple clouds and looking to do more interesting things with data, that has fundamentally changed. How do you view data platforms today?
JONATHAN: While we are still in the early days of the AI revolution, we’re already seeing how transformative this technology can be across nearly every industry. Enterprises are now adopting AI in droves – and despite being relatively new in the market, generative AI is eclipsing all other forms of AI. A recent global study conducted by S&P Global Market Intelligence in partnership with WEKA found that an astounding 88% of organizations say they are actively exploring generative AI, and 24% say they already see generative AI as an integrated capability deployed across their organization. Just 11% of respondents are not investing in generative AI at all.
This rapid shift to embrace generative AI is forcing organizations to reevaluate their technology stacks, as they struggle to reach enterprise scale. The same study found that in the average organization, 51% of AI projects are in production but not being delivered at scale. 35% of organizations cited storage and data management as the top technical inhibitor to scaling AI, outpacing compute (26%), security (23%) and networking (15%).
At WEKA, we believe that every company will need to become an AI-native company to not only survive, but thrive, in the AI era. Becoming AI-native will require that they adopt a disaggregated data pipeline-oriented architectural approach that can span edge, core and cloud environments. A typical AI pipeline has mixed IO workload requirements from training to inference and is extremely data-intensive. Legacy data infrastructure and storage solutions fall short because they weren’t designed to meet the high throughput and scalability requirements of GPUs and AI workloads.
A unified data platform software approach also gives organizations the ultimate flexibility and data portability they need at the intersection of cloud and AI. Instead of vertical storage stacks and data siloes, a data platform creates streaming horizontal data pipelines that enable organizations to get the most value from their data, no matter where it is. A unified data platform is the data foundation of the future.
ALLYSON: WEKA has made a name for itself with sustainability. Why is this important for the way you’ve designed your solutions?
JONATHAN: WEKA’s software was designed for maximum efficiency, which is inherently more sustainable. Legacy data infrastructure contains a lot of inefficiencies, which have a steep environmental cost. Further compounding the problem, AI workloads are incredibly power-hungry and enterprise data volumes are growing, so the environmental impact of AI is a big global issue, and a growing area of concern for businesses.
In fact, in the S&P Global study, 64% of respondents worldwide say their organization is “concerned” or “very concerned” about the sustainability of AI infrastructure, with 30% saying that reducing energy consumption is a driver for AI adoption in their organization.
There are a few ways organizations can start addressing AI’s energy consumption and efficiency issues. The first is GPU acceleration. On average, the GPUs needed to support AI workloads sit idle about 70% of the time, wasting energy and emitting excessive carbon while they wait for data to process. The WEKA Data Platform enables GPUs to run 20x faster and drives massive AI workload efficiencies, reducing their energy requirements and carbon output.
Second, traditional data management and storage solutions copy data multiple times to move it through the data pipeline, which is wasteful in multiple ways—it costs time, energy, carbon output, and money. The WEKA Data Platform leverages a zero-copy architecture, helping to reduce an organization’s data infrastructure footprint by 4x-7x through data copy reduction and cloud elasticity.
For WEKA customers, this means they’re not only getting orders of magnitude more performance out of their GPUs and AI model training and inference workloads, but they’re also saving 260 tons of CO2e per petabyte stored annually. When it comes to their data stack, we don’t believe organizations should have to choose between speed, scale, simplicity, or sustainability – we deliver all four benefits in a single, unified solution.
ALLYSON: What do you think is critical for the enterprise data pipeline today, and how is WEKA meeting these challenges with your solutions portfolio?
JONATHAN: The first critical element of a data pipeline is having ultimate flexibility. Most organizations are challenged by growing data volumes and data sprawl, with data in multiple locations. The second thing enterprises must have, and this is also tied to flexibility, is a solution that can grow with them into the future. The third factor is simplicity, because data challenges are becoming more complex in the AI era.
When ChatGPT emerged in late 2022, no one could have predicted just how fast AI adoption would proliferate. As we discussed before, a whopping 88% of organizations say they are now investing in Generative AI. That’s an astounding rate of adoption in just over a year.
Although WEKA couldn’t predict the dawn of the AI revolution, a decade ago, our founders could see modern high-performance computing and machine learning workloads were on the rise and likely to become the norm, requiring a wholly different approach to traditional data storage and management approaches.
Our founders deliberately designed the WEKA Data Platform as a software solution to provide organizations with the flexibility to deploy anywhere and get the same performance no matter where their data lives, whether on-premises, at the edge, in the cloud, or in hybrid or multicloud environments. It also offers seamless data portability between locations.
While it’s difficult to predict what an organization’s technology requirements will be in five or 10 years, the WEKA Data Platform is designed to scale linearly from petabytes to exabytes to support future growth and keep pace with their innovation goals. Today, WEKA has several customers running at exascale. Tomorrow? The sky's the limit.
Additionally, WEKA saw that many customers were struggling to get AI into production and needed a simplified, turnkey option that enabled them to onramp AI projects quickly. We introduced WEKApod™ at GTC this year to provide enterprises with an easy-button for AI. WEKApod is certified for NVIDIA SuperPOD deployments and combines WEKA Data Platform software with best-in-class hardware, minus the hardware lock-in. Its exceptional performance density improves GPU efficiencies, optimizes rack space utilization, and reduces idle energy consumption and carbon output to help organizations meet their sustainability goals.
ALLYSON: From a sustainability perspective, how do you see AI influencing the data center of the future?
JONATHAN: As we’ve discussed, AI’s energy and performance requirements are already shaping how organizations are evaluating their data center investments. Whether its implementing new data architectures, embracing hybrid cloud strategies, shifting infrastructure vendors, or moving AI workloads to specialty GPU clouds, organizations are already reinventing how, when and where they store and manage their data. Power is shaping up to be the new currency of AI. The data center of the future will need to balance AI’s need for highly accelerated compute with its massive energy needs. There are various ways companies can address this, ranging from leveraging public and GPU clouds that leverage renewable energy, to deploying cooling technology, adopting and embracing more efficient data infrastructure solutions that support sustainable AI practices.
ALLYSON: Where can our readers find out more about WEKA solutions in this space and engage the WEKA team to learn more?
JONATHAN: Visit our website at www.weka.io and follow our latest updates on LinkedIn and X.
Source: 451 Research, part of S&P Global Market Intelligence, Discovery Report “Global Trends in AI,” August 2024

Ayar Labs Aims to Light up AI Applications with Optical I/O-based Fabrics
Imagine the amount of data required to train ChatGPT and the size of the compute cluster required to train it. Now imagine the speed and scale of connectivity required to move all of that data across compute cluster nodes. As we look at AI era computing, the connectivity of compute is an ever- scaling challenge, which is why I was so excited to catch up with Ayar Labs CEO Mark Wade at the AI Hardware Summit last week. Ayar is a leading provider of integrated optical connectivity solutions, and Mark shared how their optical I/O is revolutionizing AI performance. Mark delved into how optical is uniquely positioned to solve data bottleneck challenges within the data center. With the explosive growth in AI workloads, traditional copper based I/O is struggling to keep up, leading to latency issues and inefficiencies. Ayar Labs’ integrated optical technology addresses this by significantly improving data transfer speeds, reducing power consumption, and unlocking higher levels of performance.
One of the most exciting parts of our discussion was how Ayar Labs solutions can handle terabytes of data per second with incredible efficiency. Mark emphasized that this technology enables 8-10x more bandwidth than traditional copper interconnects, all while consuming 10x less power. This is a game changer for large-scale AI systems where speed and energy efficiency are paramount. Mark explained that within compute clusters, there’s a requirement for scale up and scale out fabric connections, also known as the back end and front end network. Ayar’s technology is aimed primarily at the scale-up fabric where ultra-high bandwidth is required. Mark highlighted that Ayar Labs has already secured partnerships with several leading chipmakers who are embedding Ayar Labs technology into their future chiplet based designs, and they're seeing increasing interest from companies looking to upgrade their scale up fabrics without overhauling their entire infrastructure.

What really caught my attention was Mark’s explanation of Ayar’s new metrics for measuring effectiveness of GenAI delivery across profitability, interactivity and throughput. Here Ayar is taking a leadership position to drive common metrics on implementations with a focus on being a big part of the solution in driving successful results.
Mark detailed his excitement for delivering dramatic improvements in profitability and interactivity for AI inference with optical I/O. “At the end of the day, why we're so excited about bringing forth optical I/O, is that you see dramatic improvements in profitability and in interactivity. You can open up larger domains of interactivity to support machine-to-machine communications and agentic workflows. But you do that in a way that creates enough room for application builders and customers to actually build profitable business models on top of this.”

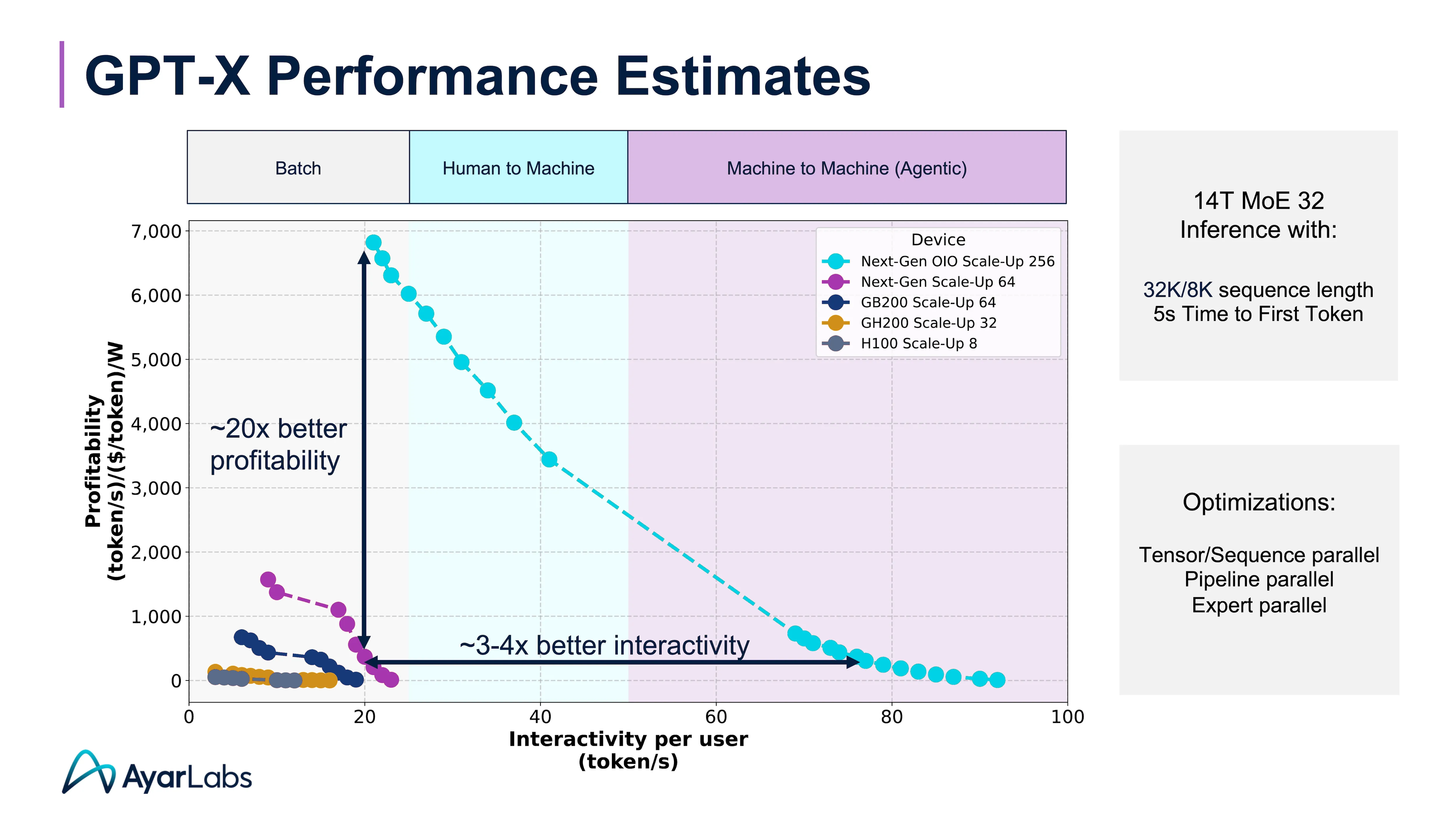
So what’s the TechArena take? As AI continues to push the limits of computing, technologies like optical I/O will become essential. Ethernet’s next speed bump will likely push copper out of the running as a viable solution. It’s not just about making AI faster; it’s about enabling more complex, data-intensive models across data intensive workloads. Ayar Labs has a differentiated solution in integrated optical, and integration into a chiplet delivers differentiated performance and efficiency. I expect the market to move in this direction, positioning Ayar squarely in the sweet spot for market uptake, and I can’t wait to see more from the company as enterprise AI adoption hits its stride in the next two years.

5 Key Considerations for Ethical AI Deployment
Artificial Intelligence (AI) is rapidly transforming the digital landscape, offering unprecedented opportunities for growth and innovation. However, the widespread use of AI also raises important ethical questions that technology leaders must grapple with. If you're steering an organization through the AI revolution, here are five critical ethical considerations to keep in mind.
1. It's crucial that we develop AI in an ethical manner.
Artificial Intelligence (AI) isn't a one-size-fits-all term. Even when we simplify things, AI can be categorized into three buckets: Narrow AI, Artificial General Intelligence (AGI), and Artificial Super Intelligence (ASI). Currently AGI and ASI are still theoretical, in large part because the computational power to build them is not available yet.
Narrow AI includes Generative AI, analytical AI, as well as limited memory AI, which trains the algorithms that enable self-driving cars. Narrow refers to the narrow focus of these algorithms. They can’t do anything beyond the single thing on which they’ve been trained.
It is imperative to build Narrow AI systems ethically because AGI and ASI will be built on their shoulders.
2. Data transparency is essential to ensure ethical AI.
Developing AI models requires massive amounts of training data. Where does it all come from? This is one of the biggest ethical dilemmas in the field of AI today.
Open AI uses data that is publicly available on the internet, data licensed from third parties, and data provided by users or “human trainers” to train ChatGPT. However, sourcing training data from the internet has led to models containing stereotypes related to gender, race, ethnicity, and disability (On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? - via ACM Digital Library).
If biases are present in the training data, that can lead to prejudiced outcomes. This can impact everything from hiring practices to criminal justice systems. Question where your data comes from and scrutinize its fairness. Ensuring data transparency is not just a best practice but a necessity to ensure ethical AI.
3. Effectively overseeing AI systems is essential to avoid reinforcing social inequalities.
AI systems have the potential to perpetuate social inequalities if not carefully managed. In the book “Automated Inequality: How High-Tech Tools Profile, Police, and Punish the Poor,” Virginia Eubanks writes about the ways data mining, algorithms, and predictive risk models can have disastrous results when not managed carefully.
One example Eubanks provided was of the Family and Social Services Administration in Indiana. This agency provides programs like food stamps and welfare for some of the most vulnerable populations.
The state turned to automation to streamline services and prevent welfare fraud. They got rid of caseworkers and relied on an automated database to deliver services. The result? Algorithmic bias prevented qualified individuals from collecting services when they needed them the most.
4. We’ve seen multiple examples of algorithmic bias.
Algorithmic bias is when an AI system uses “unrepresentative or incomplete training data or [relies] on flawed information that reflects historical inequalities.” (Source: Princeton University Journal of Public and International Affairs).
It comes back to the data again. If the data used to train the models includes data that historically enforced inequality, then that will be embedded into the AI tool that is trained by that data. We’ve seen examples of this in hiring, word associations, and criminal sentencing.
This isn’t a result of overt bias, but instead issues with the data. A historical human bias is baked into our data, especially if it was scraped from public internet. Insufficient training data can also lead to coded bias. This happened to Dr. Joy Buolamwini while she was at MIT, leading her to research facial recognition. She found that one reason faces like hers couldn’t be found by common tools was because of a lack of diversity in the tools’ datasets.
5. We can’t underestimate the environmental impact of AI model training.
Environmental, Social, and Governance (ESG) scores are becoming increasingly important as companies strive for ethical accountability. While AI can optimize resource use, training the models takes an enormous toll on the environment. In 2019, researchers at the University of Massachusetts Amherst found that the energy required to train one LLM is the same as 125 round-trip flights between New York and Beijing.
It's not just the training that impacts the environment. All the data needed by AI models has to be stored someplace, meaning data center capacity is increasing. According to this article, Google reports that 15% of all energy usage of the past three years has been dedicated to machine learning workloads.
The environmental impact of training models is influenced by their locations and the power grids they utilize. When data centers rely on grids powered by fossil fuels, the impact is more significant. Additionally, data centers situated in Asia, or the Southwestern United States often require substantial water for server cooling, further contributing to environmental impact.
These are some of the things to consider if you're responsible for reporting to your ESG administrator. The paper Quantifying the Carbon Emissions of Machine Learning gives more actionable items, including a link to a calculator.
Conclusion
Navigating the ethics of AI is a challenge that technology leaders must face head-on. By considering these five key areas you can guide your organization through the complexities of ethical AI deployment. Staying informed about regulatory landscapes and engaging in policy discussions can help ensure that innovation is both responsible and compliant.

PhoenixNAP's Bare Metal Cloud Meets AI's Data Center Demands
I love hearing from providers on how they’re grappling with delivery of cloud services to support customer adoption of AI. Jeniece Wronowski and I got that chance in a recent episode of our Data Insights podcast when we hosted Ian McClarty, President of PhoenixNAP, for a deep dive into the evolving role of AI in data centers and how bare metal cloud is meeting the demand for infrastructure that’s up to the AI performance challenge.
Our conversation started with Ian sharing his view on the enormous impact AI is having on data centers and the unique demand they bring to both operators and their customers. They require immense compute power as well as low latency communication, putting significant strain on traditional cloud infrastructure. Ian pointed out how the explosion of data—from IoT devices, streaming, and cloud applications—continues to fuel the AI boom, and that AI can’t be treated as another workload in the data center. It demands a completely fresh approach to data center infrastructure, something Ian and his team at PhoenixNAP are laser-focused on providing.
Ian then turned to bare metal cloud offerings, something PhoenixNAP is famous for delivering, and how they are particularly suited to meet AI’s growing infrastructure needs. Unlike typical cloud solutions that share resources, bare metal cloud provides dedicated servers that give companies access to raw, non virtualized hardware. This is key, Ian explained, for resource- hungry AI workloads. Companies working on AI algorithms need the ability to quickly scale, spin up resources on demand, and process huge amounts of data—capabilities that bare metal cloud supports seamlessly.
Ian highlighted three key advantages to this approach: performance, scalability, and control. In traditional virtualized environments, AI workloads can face latency issues or performance bottlenecks due to resource sharing. In addition, bare metal cloud allows for rapid scaling, whether a company needs to deploy a few servers for small-scale training or dozens for large AI models. The infrastructure can be customized and scaled up or down based on demand providing flexibility that is crucial as AI workloads can vary significantly in terms of compute power needed. Control is equally important, and Ian stressed how organizations want more control over their infrastructure when it comes to AI. With bare metal cloud, companies have the freedom to configure the hardware environment to suit their specific needs, which is especially important for workloads involving sensitive or proprietary data. This level of customization and control just isn’t possible in shared cloud environments.
As we love to do on the Data Insights series, we turned the conversation to sustainability. With recent reports placing energy consumption of data centers forecasted to represent up to 20% of the world’s energy supply due to the rise of AI, operators are grappling with driving efficiency across every vector of computing. Ian acknowledged the industry’s responsibility to address the environmental impact and noted that PhoenixNAP is taking proactive steps to design data centers with energy efficiency in mind, from improving cooling technologies to optimizing server utilization. PhoenixNAP is also exploring renewable energy utilization to power their facilities. While the journey to a fully sustainable data center is ongoing, the strides they’re making are encouraging. Ian believes that future innovations in both hardware and software will make sustainability not just an add-on but a core feature of high-performance computing environments.
The conversation made it clear that PhoenixNAP is primed for infrastructure transformation to support AI’s growth. The company’s focus on performance, flexibility, and sustainability positions it uniquely to meet the challenges and opportunities that AI presents. I left the conversation energized about the possibilities bare metal cloud offers for AI innovation and the impact it will have across industries.
Tune in to the full episode for more insights from Ian and how PhoenixNAP is reshaping the future of data centers.

VMware Drives Pull Optimized Solutions for the Edge
Day one of Edge Field Day 3 kicked off with a presentation from VMware. This sage of enterprise cloud and expert in workload automation entered the presentation room with a challenge for us to forget about all of that and focus on the edge.
Chris Taylor, Product Marketing Manager and Alan Renouf, Technology Product Manager for the Software Defined Edge group, bring fantastic technical chops to the table. Alan has an extensive background in workload automation from the data center and Chris brings a unique perspective in manufacturing as a mechanical engineer - as well as seasoning in the security arena - to the table.
So what is the state of edge from a VMware perspective? VMware has created an edge compute stack leveraging an intelligent overlay of VMware VeloCloud SDWAN and SASE Security software and the VMware Telco Cloud Platform driving 5G, Fixed and LEOS network support. This software stack provides a horizontal foundation for deployment across edge environments and vertical use cases. Top markets extend across manufacturing floors, retail, energy generation and distribution, logistics operations and more. What drives customers to edge deployments? Too much data sitting at the edge, unreliable or inefficient networking from edge to cloud, and challenges in moving data due to regulatory requirements like data sovereignty are key customer pain points met by VMware customers.
And with this vast market and clear challenge driving deployment, you’d expect that edge implementations would be scaling like a hockey stick. But Chris and Alan pointed to key challenges for deployment sharing a slightly stunning stat from World Economic Forum that 70% of companies investing in industrial 4.0 projects get stuck in the pilot phase.

The challenges that many of these companies face include oversight of the scale and differentiation of myriad edge devices, use cases, and support required. Underpinning all of this is the noted difference in edge as compute that cannot be managed with the exact approach as cloud. After all, data centers are centralized…they’re rich with IT support, and they are, well, clean and orderly.
So what is VMware’s view on management of this wild west? Alan and Chris stated the approach needs to start with a change in workload management away from push architectures of cloud to pull mode. They signaled that the world of mobile app updates provide a parallel to how they’ve architected their edge stack to perform where management checks for updates and pulls updates when there is network capacity and compute cycles to load.
So how is VMware differentiated? Their edge optmization accounts for real time apps and simplified operations and is based on a flexible platform that grows with edge implementation and breadth of apps deployed. They’ve also built in support for both VMs and K8s with zero-touch orchestration delivering provisioning via preconfigured edge HW authorization and profiles established by an edge admin residing in a central location. This allows for plug-and-play deployment, which allows for an edge device to pull desired apps once plugged in without on-the-ground IT support. Edge admins maintain all workloads across edge locations with monitoring and downloads of components to match desired end state, all delivered by VMware’s Edge Cloud Orchestrator (VECO).
So who is tapping VMware for edge management? This is one area that I wanted to hear more as VMware KNOWs the enterprise. While a breadth of customers was not provided, the one customer example referenced was a big one – Audi. Audi is looking to transform their factory floors for Industrial 4.0 – details here.
What’s the TechArena take? With solutions like ESX and VMware’s SDWAN configurations, we expect those IT admins who have trusted VMware in the cloud may also trust VMware at the edge, all questions about the current state of the company now as part of the Broadcom empire notwithstanding. The solutions discussed provide a practical approach to automated edge oversight, and I’d hoped the speakers would take more credit for what is VMware’s ace in the hole: understanding of customers at a very deep level. I would expect that customer discussions on this edge solution would reflect bringing the entire heritage of VMware to the table, and I expect to see other name brands like Audi to join as notable customer deployments for the edge stack solution.

Zededa Drives Edge Application Management at Scale
Michael Maxey, Manny Calero and Jason Grimm from Zededa shared their vision for the edge today at Edge Field Day 3. Zededa was founded in 2016 with a mission to deliver a cloudlike experience for the edge and most notably began delivering Edge Application Services last year.
Their investors have guided their initial use cases, and with Chevron and Porsche on board, they’ve targeted oil and gas implementation and automotive as well as agriculture, renewable energy, manufacturing and more.
Unpacking the solution, Zededa delivers an open-source operating system based on Linux, a cloud control for edge app management, and a global marketplace for partner applications. They also have a broad ecosystem of supported infrastructure they support from the industry from the usual suspects. Expounding further, their cloud gives central management of all apps at the edge with built-in security, policy-based management, and pull updates for edge to address the unique environmental challenges of managing this fleet of devices.
The LF Edge operating system supports workloads across virtual machines, containers, K8s clusters, VNFs, CNFs, and custom runtimes, giving incredible flexibility to organizations. It is uniquely designed for the edge, providing unique security control given the challenges of maintaining data protection with remote devices. It’s an API-only system - meaning there is no log-in at the edge, which seems like the right choice given relative technical skillsets in edge environments.
The configuration has flexibility for Linux distributions as well as embedded hypervisors and supports partitions to allow for staging of workloads prior to activation. This also means that configurations can be rolled back to ensure reliability and continued uptime.

Zededa has invested in unique edge control in the automotive arena, and Manny walked us through details on a massive deployment they’ve driven with the second largest automotive manufacturer on the planet.
The challenge within automotive? We’ve covered the electrification of automobiles on the TechArena through Robert Bielby’s series, and there are many targets for “data center on wheels” deployment across system control, infotainment, autonomous control and more. Zededa has focused on system control aspects of the automobile to drive secure transfer of data for service activation at the dealership. They’ve delivered a platform that offers the scale required to support millions of vehicles across 70,000 dealerships with an open-source foundation enabling the customer to avoid lock-in to one specific application.
Zededa delivers this configuration with support for all major platforms across x86, ARM and RISC-V. With this configuration, you can expect dealers to improve customer support while increasing high-margin service revenue and grow likelihood for repeat sales in the process.
Zededa also walked through a rail freight use case, and Jason walked us through the details in this space. Their solution has achieved 12 fortune 500 deployments with tens of thousands of nodes in production with zero trust oversight and a host of connectivity options for delivering the solution. The solution was deployed as a bungalow connected via cellular and satellite connected to edge cameras capturing images of train movement. This resilient solution protects against connectivity failures and provides central control via the Zededa cloud controller.
So what’s the TechArena take? What marked Zededa’s session was the scale of deployments they’ve been able to achieve, the real world use cases that they described, and the broad scale of options customers have at every layer of the stack. I’m impressed with their team’s deep knowledge of customer challenges and ability to transform this knowledge into deployed solutions, solving real world business challenges. If companies are evaluating edge orchestration and application management alternatives, Zededa should be on the short list.

OnLogic – Driving Rugged Infrastructure at the Edge
OnLogic capped Edge Field Day 3, and they brought a fantastic story to the event. Lisa Groeneveld and her team described how OnLogic is not the typical VC-funded startup. They are a 20+ year old company headquartered in Burlington, Vermont and led by a husband and wife team that are co-founders of the firm.
They drive infrastructure anywhere – delivering industrial computers, rugged computers, panel PCs, and edge servers to a wide variety of edge deployment use cases.
They specialize in expert technical consultation and built-to-order solutions. They listen to their customers and work to deliver solutions that meet what customers require most. The team shared details of the actual infrastructure. Starting with the far edge, they break down infrastructure requirements as devices and edge servers, and they look at landing infrastructure in these environments to meet temp, dust, space, and vibration realities that exist in these environments.
To tell the story of their infrastructure, the team utilized a series of deployment examples including agriculture. OnLogic’s customer sought foundational compute for robotic food harvesting. Enter the Karbon 800 series computer offering a fanless design, extended temperature range, and military grade shock and vibration tolerance. This computer runs an embedded Intel i9 processor and GPU expansion ports for AI acceleration and comes in three configuration options. The Karbon fueled the robotic solution the customer required to improve crop yields and save costs.
The team shared an example in the mining sector with a partner called Flasheye. Flasheye was seeking to tap visualization to reduce belt downtime to mining operations in horrifically rugged environments. Their customer operated a mine in Northern Sweden whose belt experienced spillage and required human intervention increasing safety risk. With the Flasheye solution, powered by an OnLogic Karbon 400 series platform. This computer can drive uptime up to -40-degree temps with an efficient Atom processor and flexible I/O that supported the visualization integration desired by the customer.

The conversation next turned to a steel mill use case where intense heat and grime and other particulate are a constant challenge. The customer, Steel Dynamics, sought to deliver monitoring of the fabrication environment. Enter the OnLogic Tacton TC401, an all in one panel PC, PCs that are built into the panels of industrial equipment. This PC operates from temperatures between -20C to 70C and features Intel 12th Gen CPU with a ModBay I/O expander supporting wifi and cellular connectivity.
The team rounded out use cases with a residential application, more specifically in hi-rise elevator control. Nantum AI brought OnLogic a challenge for an interesting use case – how to deliver AI control to elevators to predict a power outage and avoid stranding people on elevators. Enter the Helix Industrial Edge Computer featuring a 10th-12th Gen Intel embedded Core processor, solid state design, and operating temps between 0C-50C. The Helix offers slightly less ruggedness than the other solutions mentioned making it perfect for a building deployment.
Finally, the team walked us through their partners. This started with Intel, which was no surprise given the continuous refrain of Intel processors across their fleet. While processors begin the collaboration, OnLogic is also tapping the OpenVino toolkit to optimize software for their targeted solutions. The depth of this partnership, given my own personal history, comes as no surprise. Intel has invested deeply in embedded, IoT, and edge optimization including ruggedization of long-life CPUs. OnLogic’s depth of collaboration extends to AWS. OnLogic is providing infrastructure for AWS Greengrass. The company also extended their collaboration discussion with software providers RedHat, Avassa, and GuiseAI.
What’s the TechArena take? If I ever head back to industry, OnLogic represents the type of culture I’d want to be a part of. This company is led with integrity, and my guess is that extends to customer and partner relationships. But beyond that, they deliver the meat and potatoes of what is required at the edge – computing tailor designed for rugged environments with the core capabilities needed to ensure long life, continued uptime, and feature options to fuel desired workloads. They’ve built a reputation for both broad product configurability as well as trusted reliability. We expect their business to continue its growth path as edge use cases advance.

Why a Self-Driving Car Might Run a “STOB” Sign: To ViT or Not To ViT

The all-too-familiar hexagonal red STOP sign with white trim around the border (at least in the United States) instructs the driver to come to a complete stop, look in both directions, and yield to traffic as required before proceeding. If the stop sign had the misfortune of being vandalized, perhaps a casualty of graffiti, the human driver would most likely be able to look beyond the graffiti to recognize that it is a STOP sign, and take the appropriate action.
It could be said that this behavior is analogous to “inductive priors,” a term used in the science of neural networks, where logical assumptions are made based upon the input data – even though some of the input data may be corrupted or occluded in some manner. In this case, the driver has seen enough stop signs and has enough cues in this sign to recognize it as a stop sign, despite the fact that it has been defaced.
Convolutional Neural Networks (CNNs) typically employ an equivalent type of inductive priors. This class of neural networks assumes that nearby pixels from a camera image are related (typically a reasonable assumption). This class of neural net also assumes that the importance of the different parts of the image is weighted similarly (no one part of the image is any more important than another part). The result is that for CNNs, a relatively limited amount of training is required before the network starts to demonstrate significant levels of accuracy. However, even when fully trained, the inherent accuracy of the CNN is limited when compared to other classes of neural nets, which means it might “jump to conclusions too quickly” to make a judgment and make mistakes.
Slightly off topic for a second, the intelligence of different breeds of dogs is typically measured by how many times a dog of a certain breed typically has to hear a command before that breed of dog can recognize a command, or is trained. I am going to draw the analogy that different classes of neural networks are like different breeds of dogs in both the manner as to how long it takes before they are trained and the accuracy by which they are repeatedly and accurately able to recognize a command from different voices.
While CNNs have been the mainstay deep neural network (DNN) employed to address perception in ADAS applications, as of late, Vision Transformers (ViT) have been gaining significant interest within the ADAS design communities, primarily due to their improved accuracy in object classification over CNNs. In the case of the ViT, however, the increased accuracy comes with the need for a very extensive set of training data. The ViT also demands increased compute performance over that of the CNN during deployment.
ViTs have very low inductive biases. While this is one of the factors leading to improved accuracy (this form of neural networks is less prone to “jump to conclusions”) a significantly larger training set is needed before the ViT can achieve a level of accuracy equivalent to that of the CNN. Also, because the ViT does not assume the importance of adjacent pixels, the full frame with all pixels present must be in place before ViT calculations are performed. This, in turn, is one of several factors that drive up requisite compute performance during deployment/inference.
Increasingly, image sensors with higher resolutions are being employed in the automobile as they can provide a greater amount of information about the surrounding environment of the vehicle as compared to their lower resolution (Mpixel) counterparts. Sensors that provide more information enable objects to be more readily detected from greater distances. This, in turn, enables the vehicle to operate autonomously at higher speeds. As an example, a lower resolution camera may provide only 5 pixels, which reflects an object that has been detected off in the distance. This, however, is an insufficient amount of information to accurately recognize the image and plan the appropriate action. The higher resolution camera, on the other hand, may provide 100 pixels of that same object, enabling the ADAS perception engine to readily recognize that object off in the distance as a pedestrian, cyclist, or stationary object providing more time to the autonomous vehicle to take the right action.
While the CNN doesn’t require the full frame of the image to accurately detect the image, the ViT does. This further exacerbates the computational requirements of the ViT due to the greater amount of data within the frame that must be processed from the higher-resolution camera image in the same time period.
Just as some breeds of dogs have different propensities towards being trained, neural network architectures can be viewed as being on a spectrum of inductive biases from strong to weak. CNNs are on one end of the spectrum while ViTs are on the other end.
As typically seems to be the case, there is no free lunch. The increased power consumption of the ViT driven by the inherent higher computation and the required increased training datasets and training times represent meaningful recurring and non-recurring costs. Hybrid architectures are emerging that combine CNNs and ViTs into one architecture, leveraging the inherent strengths of each neural network. These architectures strike a middle ground between CNNs’ and ViTs' inductive biases, finding a balance between the learning flexibility and accuracy of the ViT while reducing the amount of training required.
While the focus has been on comparing CNN vs. ViT, similar debates and tradeoffs are ongoing in other areas wherever AI is being employed. To that end, this is why it is paramount that upgradable AI architectures are deployed in the field to ensure that the optimal neural network can be deployed as it is unearthed and thus avoiding the wrong response to a STOB sign.

TSecond Delivers Bryck AI for AI Inferencing at the Edge
The co-founders from TSecond, Sahil Chawla CEO, and Manavalan Krishnan, CTO, were on hand at Edge Field Day 3 to showcase Bryck and Bryck AI, black box edge devices chock full of storage, and in the case of the AI flavor, AI accelerators.
These solutions are created due to large stores of data being generated across the edge, and in rising cases, driving AI inference at the edge eliminating the need to move large data stores to the cloud.
We have covered rugged storage platforms for the edge on TechArena, and some of the vertical targets sounded very familiar – media, content delivery, defense to name a few. However, what made my ears perk up was a strong focus on aerospace and deep investment from Boeing in this growing organization.
Let’s go under the covers. Manavalan took us on a detailed tour of the hardware, describing that the standard Bryck is a storage platform with up to one PB of storage running 40GB/sec throughput with 256 parallel PCIe Gen 4 data lanes and integrated security capabilities.
A Bryck requires 240-800W to run, bringing it in as energy efficient vs. storage alternatives. The platform promises to be faster and lighter than competitive offerings as well, while promising rugged resiliency for edge environments, hot pluggability, fault tolerance, and - due to low weight - cost effective to ship to edge locations. TSecond claims less than $100 to ship anywhere in the US – which matters when you consider the scale of edge device delivery in this growing market and you consider that competitive solutions weigh in at up to 500 lbs vs. 20 lbs for Bryck. Bryck can also scale with a multi-Bryck configuration as well as Bryck Mini with various capacities.
Bryck integrates the expected storage software including support for AWS, GCP and Azure for easy integration. They also offer Data Dart, a collaboration with Equinix to accelerate data transport to the cloud utilizing physical Bryck upload with movement of data from Equinix to the cloud provider of choice.

Avassa: The Swedes Have Invaded the Edge
I was delighted to see Avassa back at Edge Field Day showcasing the latest technology that the company is delivering for edge application and orchestration oversight.
Avassa is a software only, cloud based, Control Tower platform for edge that is container first in orientation. Container first is a mantra at the company as Avassa called out the trend that “cloud out” is trending towards VMs eventually being sunset out of existence and “IoT in” seeking containers eventually sunrise as the de facto standard.
Carl Moberg, CTO of Avassa and a TechArena innovation voice, said that full elimination of VMs will be difficult due to pesky Windows-based applications that continue to require support and are unfriendly in native containerized environments.
So what is Avassa doing to support this continuum? They noted that open-industry standard frameworks for integrated VMs and containers is required that supports containerization of VMs for legacy apps.
Avassa delivers encapsulation through a stack containing a container image encapsulating a VM image and start script sitting on top of a container runtime using KVM with integrated health probes. While their container orchestrator cannot natively manage VM updates, they have developed means for this management and demonstrated this live in the session.
Their management extends to leading edge deployments of AI models or web assembly (WASM) containerized alongside Linux-based modern applications. This natural containerization of AI models and web assembly makes sense given that the latter have been primarily developed by born-on-the-cloud organizations by the very same engineers in many cases that built cloud native computing models.

The Avassa Control Tower demonstration highlighted ease of control of edge applications as well as depth of information collected by the Avassa oversight including the aforementioned health probes. They demonstrated migration of a VM-based service to a containerized alternative without disruption of service.
So what about Avassa’s decision to control with Docker runtime with KVM vs. K8s? This was a point of contention in last Edge Field Day’s presentation from the company, and Carl provided a helpful insight on market traction, stating that many companies from mid-market to hyperscalers have embraced this configuration for far or leaf edge environments where Avassa is targeted. He admitted that when edge starts looking like a data center in control and complexity, K8s may make sense, but that this is not Avassa’s target. This makes sense given the leaner stack offered by the Avassa solution for the constraints of edge infrastructure.
Carl and Fredrik moved on to management of applications in offline edge scenarios. Once edge devices are up and running with Avassa’s Control Tower, how are applications managed, and what happens when facing a scenario of upstream outages? The Avassa team provided a demo with a literal cut cord which made the Edge Field Day delegates quite twitchy. After all, many are former or current IT administrators. Carl pointed out that edge requires a different approach to cloud environments, which relies on failover in a situation like this.
How Avassa has managed this is to rely on a downstream admin with unique control of nodes at the site. This control creates an updated stack at the edge disconnected from central Control Tower, and customers choose how they manage the complexity of central workloads vs. local deployments once edge resources come back online.
So what is the TechArena take? Avassa has delivered a compelling central control across device orchestration and application management. I think they’ve made some tough choices on how to manage edge environments with the efficiency and control required for these environments, and I think they’ve chosen wisely for delivery of services within the far edge. For customers looking to deploy containerized environments, they’re a terrific option and should be evaluated by enterprises across industries. To learn more about Avassa, visit their site and check out TechArena’s content featuring the company.