
.webp)
Subscribe to Our Newsletter
Read the latest in the world of AI, data center, and edge innovation.

Please raise your hand if you knew what DeepSeek was December 2024? Thanks.
The last 2 years of innovations in the AI field have been astonishing, with the only constant being unpredictability. The trend is not expected to change, and projects like DeepSeek are confirmation of this rapidly changing environment. Beside the technical value it brought to the industry with their detailed technical report, there is a significant message hidden in the initiative: “Complete” with massive resource scale is not enough anymore, it’s time to pursue the “Good.”
If yesterday’s focus was on unlocking new capabilities, today’s is optimizing them. Science history is full of examples: computers that once required the size of a house can now fit in a pocket and do way more than their predecessors. While AI is beginning and we should expect much more, there is an incumbent need from the market and the developer communities: the need to do more with less. This need is further motivated by financial considerations and policies on environmental impact.
This is the hidden ambition driving demand for an evolution of all the components of AI pipelines, such as software and hardware, and is not limited to the algorithmic approach itself.
The encouraging aspect is that Intel was able to intercept some of these needs at very early stages, even before DeepSeek became a buzzword, and now developers and enterprises can have the opportunity to “get more with less” out of their infrastructures or preferred devices.
Before seeing how, let’s expand on the key changes proposed by DeepSeek.
DeepSeek News: Separating the Wheat From the Chaff
DeepSeek represents a paradigm shift in AI model development. But what exactly did they do, and why did it generate so much hype?
We can split between business and technical contributions. On the Business side, they proposed a free-to-use model (open-weights with MIT license that allows to build and sell products with it) with competitive performance (see Fig.1 below), obtained using a fraction of the resources claimed by others.
On the technical side, they combined several state-of-the-art methods to squeeze maximum performance at runtime. These include architectural optimizations such as Mixture-of-Experts (MoE), Multihead Latent Attention (MLA), MultiToken Prediction (MTP), revised training procedures like DualPipe, and quantization to FP8 and post-training optimizations such as Group-Relative-Policy-Optimization (GRPO). The explanation of these techniques is outside the scope of this article but all the details can be found in the DeepSeek technical report.
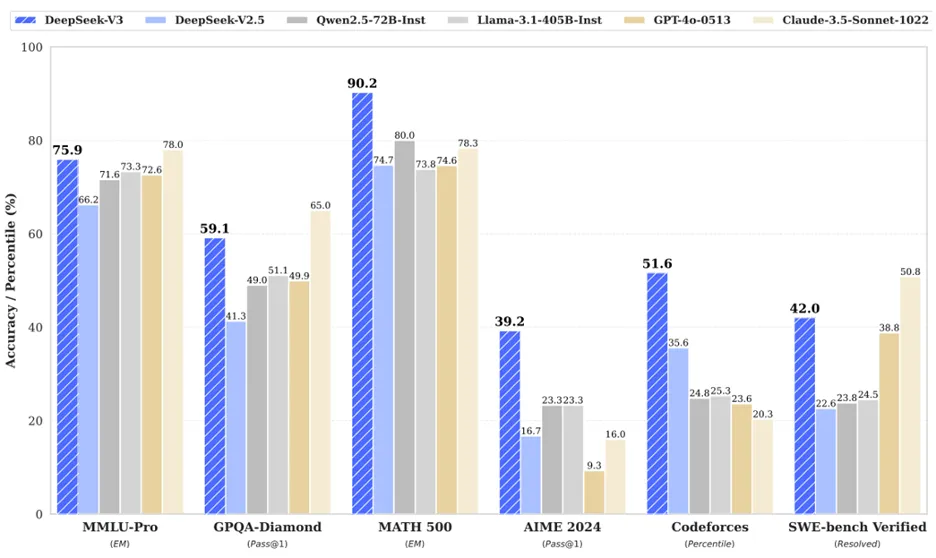
Fig.1: DeepSeek performance comparison with other models. Source: https://arxiv.org/pdf/2412.19437
Key Takeaways for the Market?
To maximize performance during execution time, DeepSeek went beyond the commonly used libraries, like CUDA, and rewrote some of the communication and memory allocation modules from scratch [1]. This means that DeepSeek went off-rail to achieve their goal with what they had. They picked the custom approach over brute-force. It went smarter instead of bigger. Quality over quantity. Maybe they were less scared of customizing code than investing more money in Hardware?
The point is that the market needs alternative routes, not only for training, but also for hosting the inference. This is also confirmed by the variants released by DeepSeek [2], which allow developers to adopt either the 671B version or the smaller 1.5B alternatives [3].
Another bold step they took was to have the model working at a lower resolution, such as FP8. Normally in AI pipelines, the training is performed using more digits (i.e. BF16 or FP32) to better capture the nuances of the data and the correlations in it. More digits make the algorithm more granular, hence more effective. Reducing the number of digits can surely speed-up computation, at the expense of the final model accuracy. More common is quantization being adopted at inference time for easier deployment and faster execution (particularly helpful when dealing with edge devices). In this case, the DeepSeek team quantized the model during training. This is a milestone that can encourage others to follow this approach.
How Does This Match Intel’s Strategy?
Intel has been advocating quantization as a critical method since the launch of its 2nd generation of Intel® Xeon® scalable processors in 2019, when it was only available for speeding-up inference. It extended to training with the 4th generation and confirmed onboard of the latest Intel Xeon 6.
But as mentioned at the beginning, the only constant aspect in AI landscape has been unpredictability. This is why Intel has worked on various fronts to enable AI tools to be hosted everywhere, from edge-to-cloud ensuring maximum flexibility to reduce risks and maximize ROI for enterprises. But let the actions speak for themselves!
Below are reported the best-known-methods to host DeepSeek locally, where no data is shared externally to protect privacy on client platforms, Intel® Core™ Ultra desktop processors (series 2), AI PC, using the distilled and smaller version of the model, as well as on Intel Xeon servers, fully enabled with Intel® Gaudi® as AI accelerators for the 671B version. The examples are not limited to DeepSeek, and there are many cases where Xeon-only might represent the best performance/value option to host the models. Below is a reference on how to test additional models, using Intel Xeon CPU only, to get initial evaluation.
Run DeepSeek using CPU, NPU and ArcGPU
Run DeepSeek using Intel Gaudi 3 and Intel Xeon
Additionally, here is a technical research paper with experiments on 671B DeepSeek-R1 done on Intel Gaudi 3
Conclusion
Intel’s mission is to democratize access to leading technologies and to offer our customers a choice of deployment options for AI. DeepSeek's effort on the creation of more efficient models that can run on advanced compute solutions paves the way for a future where AI is more accessible, sustainable, and versatile. As these technologies continue to evolve, the potential for AI to transform industries and improve lives is boundless, heralding a future where intelligent systems are seamlessly integrated into the fabric of our daily lives.
[2] https://github.com/deepseek-ai/DeepSeek-V3
[3] https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B