
.webp)
Subscribe to Our Newsletter
Read the latest in the world of AI, data center, and edge innovation.

Last year, a company deployed an internal AI assistant to help employees navigate thousands of internal documents. The system worked beautifully in testing. Then a product manager asked a simple question about the company's policy for handling customer data in Europe.
The assistant confidently returned an answer citing an internal policy document.
There was only one problem. The document had been replaced six months earlier. The AI wasn’t hallucinating. It was reasoning correctly. But on the wrong context.
This is becoming one of the most common failure modes in enterprise AI. Not because models are weak, but because the information surrounding them is poorly engineered. In other words, the biggest problem in enterprise AI is no longer the model. It’s the context.
And solving that problem is giving rise to a new discipline that many organizations didn’t plan for: context engineering.
For the past two years, the AI conversation has revolved around model capability: Which model is larger? Which model is faster? Which model performs best on benchmarks?
But once organizations begin deploying AI inside real systems, they quickly discover something uncomfortable: Most enterprise AI failures are not model failures. They are context failures.
Models are powerful reasoning engines, but they are fundamentally blind to the organizations they operate within. They do not understand internal documentation, product terminology, operational workflows, or governance policies unless that information is explicitly provided to them. And that information rarely exists in one place. It is scattered across data lakes, SaaS platforms, documentation systems, and operational databases. Retrieving the right knowledge at the right moment is not a trivial problem. It is an infrastructure problem.
The first wave of generative AI adoption emphasized prompt engineering. Teams experimented with prompt templates, formatting tricks, and system instructions to improve model outputs. While prompts matter, they are ultimately just instructions.
The quality of an AI system’s response depends far more on what the model sees than on how the question is phrased. Enterprise AI systems increasingly rely on pipelines that retrieve and assemble relevant knowledge before a model generates its response.
This architecture typically involves:
The shift from crafting prompts to assembling context is the foundation of context engineering.
Most prototypes hide the true difficulty of context management. A small document corpus is embedded into a vector database. Retrieval works well. The AI assistant appears intelligent. But enterprise deployments introduce realities that prototypes ignore, such as:
Freshness: Knowledge changes constantly. If embeddings are not refreshed regularly, AI systems begin reasoning on outdated information.
Permissions: Enterprise data is rarely universally accessible. Context pipelines must enforce access controls before retrieving sensitive information.
Semantic inconsistency: Different systems often describe the same concepts in different ways. Retrieval pipelines must reconcile these differences.
Traceability: Organizations must know where an AI-generated answer originated, especially in regulated industries.
These challenges are not failures of the model. They are failures of context infrastructure. And they are becoming the defining challenge of enterprise AI.
To solve these problems, enterprises are quietly building a new layer of infrastructure designed to assemble context for AI systems.
At a high level, the architecture looks something like this:
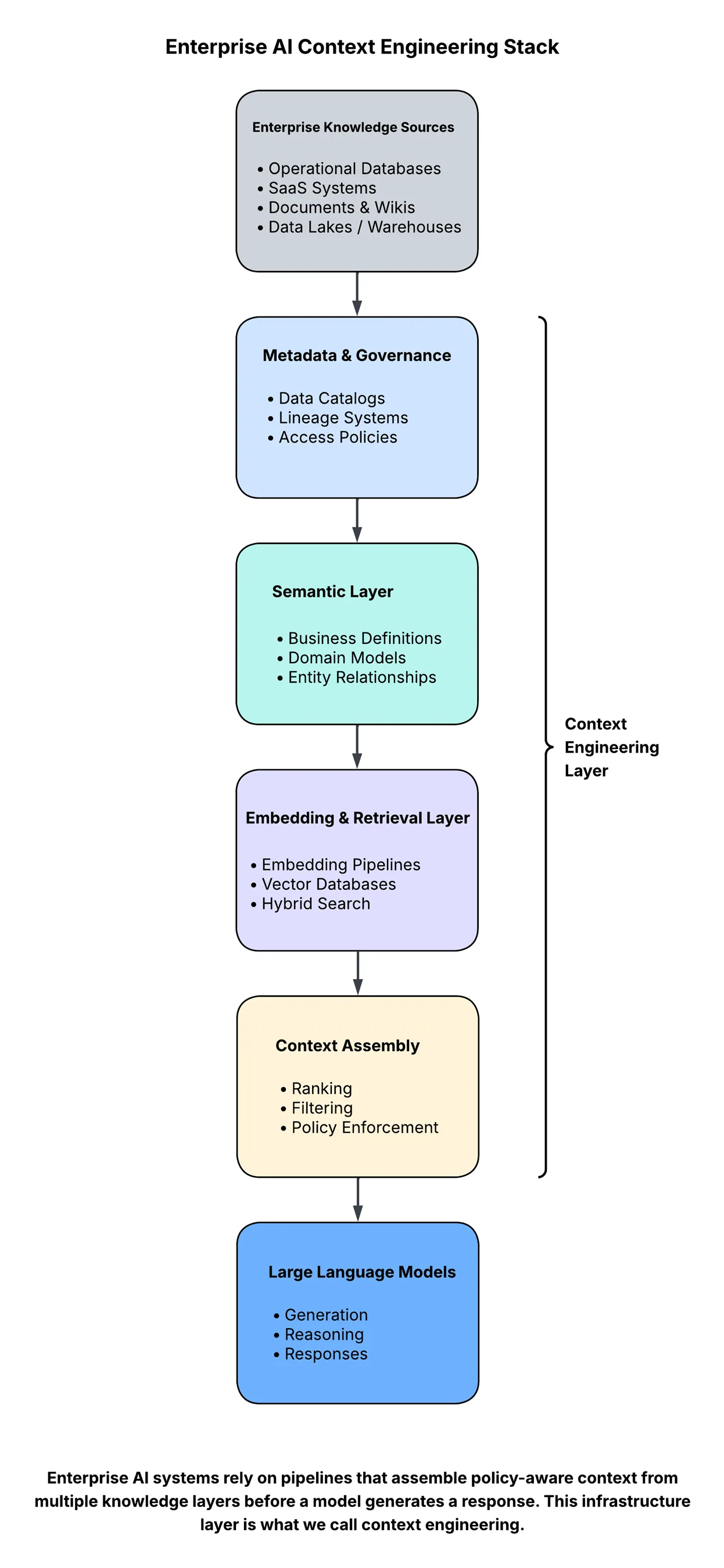
Every layer introduces challenges that look suspiciously familiar to data engineering teams:
In other words, the infrastructure supporting AI applications increasingly resembles the infrastructure powering modern data platforms.
One of the more surprising consequences of this shift is how it changes organizational roles. Many companies began their AI journeys assuming the key hires would be machine learning engineers or prompt engineers.
But as deployments mature, organizations are discovering something else. The teams solving the hardest problems in AI are often data platform teams.
Why? Because the quality of an AI system’s answers depends heavily on how well enterprise knowledge is structured, governed, and delivered at runtime.
This requires capabilities, such as:
These are not new problems. They are data engineering problems that are now appearing inside AI systems, which leads to a somewhat uncomfortable observation: Many enterprises are spending millions optimizing model selection while investing almost nothing in the infrastructure that determines what the model actually sees.
Most enterprise data platforms were designed for human consumption. Dashboards, data catalogs, and analytics systems assume a human analyst interpreting the results.
AI systems operate differently. They require knowledge that is structured, policy-aware, and retrievable in milliseconds. This shift is pushing organizations toward what might be described as context platforms, infrastructure designed specifically to deliver curated knowledge to AI systems.
These platforms combine elements of:
Together, these components form the operational backbone of reliable AI systems.
Most organizations will eventually have access to similar models. The real differentiator will not be model access. It will be context quality.
Organizations that engineer context effectively will build AI systems that are:
Organizations that neglect this layer will continue to experience AI systems that appear intelligent in demos but behave unpredictably in production.
Artificial intelligence often appears to operate at the level of reasoning and language. But beneath every reliable AI system lies something less glamorous: pipelines, metadata systems, governance frameworks, and retrieval infrastructure.
In other words, intelligence at scale still depends on infrastructure. The companies that understand this shift earliest will build AI systems that work. Everyone else will keep searching for better models to solve a problem that was never about the model in the first place.