
.webp)
Subscribe to Our Newsletter
Read the latest in the world of AI, data center, and edge innovation.

Google knows a bit about AI. After all, their data stores include every search ever done since the birth of their browser, and they’ve been on the cutting edge of AI integration across their business from the earliest days of machine and deep learning integration. Today’s speakers from Google cloud introduced their talk by positing that AI is the next platform shift…from internet to mobile…and now AI. It’s an interesting analogy coming from a foundational force of the Internet age, and they leaned in to this pointing about the acceleration of generative AI and how many of the innovators in this realm choosing Google Cloud as their foundation. They’re taking advantage of Google Gemini, their foundational AI model that works across the Google-verse and introduced in market at the end of last year. Yesterday, Google delivered Gemma, an open model based on the same technology as Gemini and delivered by the team at DeepMind. It’s fantastic to see Google take this step and is consistent with their history of open sourcing some of their best engineering to the benefit of all (Kubernetes comes to mind as a disruptive opensource innovation delivered in a similar manner).
How is Gemma going to roll out? There’s a natural integration of Kubernetes that supports scaling up to 50K TPU chips and 15K nodes per cluster that extend support for both training and inference for a broad AI ecosystem. And while Google is talking during #Intel day at #AIFD4, they did introduce a graph showcasing their extensive support across major silicon environments:
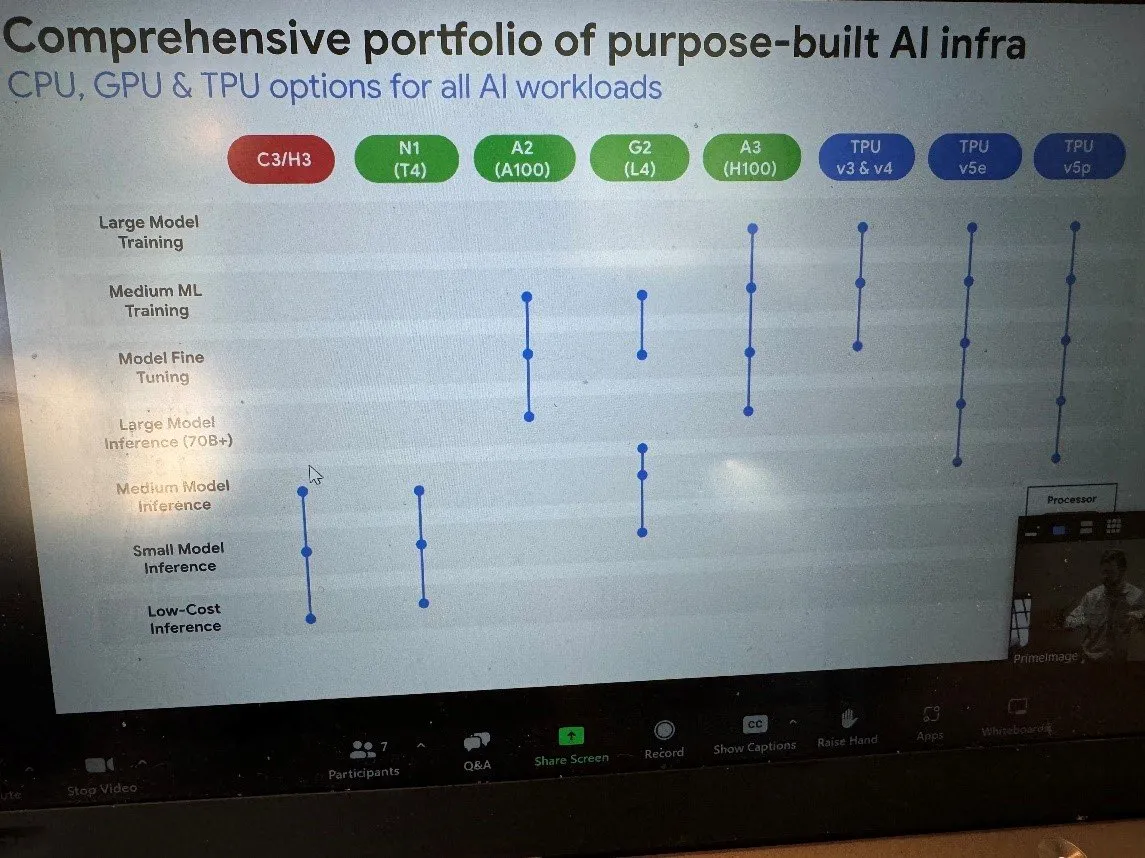
Google went further, calling out that a lot of AI still runs on CPU and noted that Intel’s AMX technology extends the capability of CPU performance for different AI models. Model size is the consideration that will fuel platform choice across CPU/GPU/TPU with Google aligned with Intel’s positioning of smaller models being the natural domain for CPU deployment. Where do Google’s own TPUs play? Google positions them at the other extreme for very large models supported by Pytorch efforts within the company. Now in their fifth generation (they’ve been delivering TPU custom chips since 2018), TPUs are available to customers on the Google Cloud platform. This delivery fits with the frenzy of AI silicon development and showcases Google’s end game in this space. I’d expect to see more emphasis here from all large cloud players who prioritize their own silicon delivery with their own AI training models, and as this landscape evolves I wonder if we’ll continue to see a multi-architecture support slide or one that more fully leads with bespoke custom silicon offerings.